3 분석: 탐색
c(
"rio", "psych", "psychTools", "skimr", "janitor",
"tidyverse", "tidytable", "tidymodels",
"GGally", "ggforce", "gt", "mdthemes",
"r2symbols", "equatiomatic"
) -> pkg
pkg %in% installed.packages()[,"Package"] -> pkg_installed
(pkg[!pkg_installed] -> pkg_new)
if(length(pkg_new)) install.packages(pkg_new)
sapply(pkg, library, ch = T)3.1 기술통계
갑돌이는 모의분석에 필요한 가상자료를 모두 만들어, 수집(측정)과 정제 단계를 마쳤다. 다음 단계인 분석을 할 차례다. 분석은 크게 탐색과 추론으로 구분할 수 있다. 탐색은 본격적인 분석에 앞서 확보한 자료의 내용을 살펴보는 과정이다. 탐색하는 분석이므로 탐색적 자료분석(EDA: Exploratory Data Analysis)라고 한다. 빈도, 중심경향치, 분산성, 이상치(outlier), 변수의 분포, 변수 사이의 관계 등을 탐색한다.
첫 단계는 기술통계(Descriptive Statistics)다. 기술통계는 수집한 자료를 기술(describe)해 요약하는 통계방법이다.
기술통계는 연속변수와 불연속변수(이산변수 혹은 범주형 변수)에 적용하는 방법이 다르다. 등간척도와 비율척도로 측정한 연속형 변수는 연속변수에 대해서는 중심경향치(평균 등)와 분산성측정치(표준편차 등)를 계산하고, 명목척도로 측정한 불연속변수에 대해서는 빈도를 구한다. 서열척도로 측정한 변수에 대해서는 측정 정밀도에 따라 빈도를 계산하거나 혹은 중심경향치와 분산성측정치를 구한다.
자료를 처음 훓어보는데 유용한 함수는 str()함수와 skimr패키지의 skim()함수다.
rio::import("df.xlsx") -> df
df %>%
mutate.(
sex = factor(sex, labels = c("남성", "여성")),
species = factor(species)
) -> df
str(df)## Classes 'tidytable', 'data.table' and 'data.frame': 180 obs. of 6 variables:
## $ id : chr "저그1" "저그2" "저그3" "저그4" ...
## $ sex : Factor w/ 2 levels "남성","여성": 1 1 2 2 2 1 1 1 2 2 ...
## $ species: Factor w/ 3 levels "저그","테란",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ age : num 36 27 22 43 37 23 24 29 35 23 ...
## $ dose : num 40.6 41.9 42.9 38.5 35.9 ...
## $ vigor : num 101.2 103.8 105.8 97.1 91.7 ...
## - attr(*, ".internal.selfref")=<externalptr>skimr::skim(df)| Name | df |
| Number of rows | 180 |
| Number of columns | 6 |
| Key | NULL |
| _______________________ | |
| Column type frequency: | |
| character | 1 |
| factor | 2 |
| numeric | 3 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| id | 0 | 1 | 3 | 6 | 0 | 180 | 0 |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| sex | 0 | 1 | FALSE | 2 | 남성: 97, 여성: 83 |
| species | 0 | 1 | FALSE | 3 | 저그: 60, 테란: 60, 프로토: 60 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| age | 0 | 1 | 35.78 | 8.72 | 21.00 | 29.00 | 36.00 | 44.00 | 49.00 | ▅▆▅▆▇ |
| dose | 0 | 1 | 39.98 | 5.32 | 26.48 | 36.33 | 40.18 | 43.74 | 53.74 | ▂▅▇▅▁ |
| vigor | 0 | 1 | 99.96 | 10.64 | 72.95 | 92.67 | 100.36 | 107.47 | 127.49 | ▂▅▇▅▁ |
psych패키지의 describe()함수는 포괄적인 기술통계치를 간결하게 제공한다. 범주형자료를 숫자형 자료로 변환해 *표시를 한다.
describe(df)## vars n mean sd median trimmed mad min max range skew
## id* 1 180 90.50 52.11 90.50 90.50 66.72 1.00 180.00 179.00 0.00
## sex* 2 180 1.46 0.50 1.00 1.45 0.00 1.00 2.00 1.00 0.15
## species* 3 180 2.00 0.82 2.00 2.00 1.48 1.00 3.00 2.00 0.00
## age 4 180 35.78 8.72 36.00 35.98 11.86 21.00 49.00 28.00 -0.12
## dose 5 180 39.98 5.32 40.18 40.02 5.56 26.48 53.74 27.27 -0.05
## vigor 6 180 99.96 10.64 100.36 100.04 11.12 72.95 127.49 54.53 -0.05
## kurtosis se
## id* -1.22 3.88
## sex* -1.99 0.04
## species* -1.52 0.06
## age -1.28 0.65
## dose -0.43 0.40
## vigor -0.43 0.79범주형 변수의 속성별 기술통계는 describeBy(group = )로 구할 수 있다.
describeBy(df, group = "sex")##
## Descriptive statistics by group
## sex: 남성
## vars n mean sd median trimmed mad min max range skew
## id* 1 97 49.00 28.15 49.00 49.00 35.58 1.00 97.00 96.00 0.00
## sex* 2 97 1.00 0.00 1.00 1.00 0.00 1.00 1.00 0.00 NaN
## species* 3 97 2.06 0.80 2.00 2.08 1.48 1.00 3.00 2.00 -0.11
## age 4 97 36.07 8.83 36.00 36.27 11.86 21.00 49.00 28.00 -0.07
## dose 5 97 40.04 5.28 39.87 39.92 5.74 29.49 53.74 24.26 0.21
## vigor 6 97 100.09 10.56 99.74 99.83 11.48 78.97 127.49 48.51 0.21
## kurtosis se
## id* -1.24 2.86
## sex* NaN 0.00
## species* -1.45 0.08
## age -1.32 0.90
## dose -0.50 0.54
## vigor -0.50 1.07
## ------------------------------------------------------------
## sex: 여성
## vars n mean sd median trimmed mad min max range skew
## id* 1 83 42.00 24.10 42.00 42.00 31.13 1.00 83.00 82.00 0.00
## sex* 2 83 2.00 0.00 2.00 2.00 0.00 2.00 2.00 0.00 NaN
## species* 3 83 1.93 0.84 2.00 1.91 1.48 1.00 3.00 2.00 0.13
## age 4 83 35.43 8.63 37.00 35.64 11.86 21.00 48.00 27.00 -0.18
## dose 5 83 39.91 5.40 40.39 40.11 5.26 26.48 50.97 24.49 -0.33
## vigor 6 83 99.81 10.79 100.78 100.23 10.52 72.95 121.93 48.98 -0.33
## kurtosis se
## id* -1.24 2.65
## sex* NaN 0.00
## species* -1.58 0.09
## age -1.30 0.95
## dose -0.45 0.59
## vigor -0.45 1.183.1.1 빈도
불연속변수의 빈도는 교차표(cross table)로 나타낸다. janitor패키지의 tabyl()함수가 편리하다.
df %>% tabyl(sex, species)## sex 저그 테란 프로토스
## 남성 28 35 34
## 여성 32 25 26adorn_totals()함수로 각 행과 열의 합을 계산한다.
df %>%
tabyl(sex, species) %>%
adorn_totals(where = c("row", "col")) ## sex 저그 테란 프로토스 Total
## 남성 28 35 34 97
## 여성 32 25 26 83
## Total 60 60 60 180표를 출판가능한 형식으로 정리하는 패키지는 gt다. ’gt’는 Grammar of Table로서, ggplot의 그림 생성방식을 표 생성에 적용했다.
df %>%
tabyl(sex, species) %>%
adorn_totals(where = c("row", "col")) %>%
gt() %>%
tab_header("성과 종의 빈도의 교차표")| 성과 종의 빈도의 교차표 | ||||
|---|---|---|---|---|
| sex | 저그 | 테란 | 프로토스 | Total |
| 남성 | 28 | 35 | 34 | 97 |
| 여성 | 32 | 25 | 26 | 83 |
| Total | 60 | 60 | 60 | 180 |
3.1.2 중심경향치
중심성 경향치는 자료를 대표하는 값으로서 평균, 중간값, 최빈값 등이 있다.
3.1.2.1 평균
평균(mean)은 자료의 합을 자료의 개수로 나눈 값
number_v <- c(2, 2, 2, 3, 5, 7, 9000)
sum(number_v)/length(number_v)## [1] 1288.714mean(number_v)## [1] 1288.714평균을 구하는 공식을 이용해 사용자함수를 만들면 다음과 같다.
mean_f <- function(x){
output <- sum(x)/length(x)
return(output)
}3.1.2.2 중간값
중간값(중앙값: median)은 자료를 순서대로 정렬했을 때 가운데 있는 값. 상위 50%와 하위 50% 지점의 값. 짝수인 경우, 중간의 두개 값 평균.
num_odd <- c(1, 2, 3, 4, 5, 600)
num_even <- c(1, 2, 3, 4, 500)
median(num_odd)## [1] 3.5median(num_even)## [1] 33.1.3 분산성측정치
자료가 중심경향치에서 벗어난 정도. 범위, 분산, 표준편차, 사분범위 등이 있다.
3.1.3.1 범위
최대값과 최소값 사이의 거리.
number_v <- c(1, 2, 3, 4, 5, 6, 7, 8, 9)
max(number_v) - min(number_v)## [1] 83.1.3.2 분산
자료가 평균에서 벗어난(deviation) 정도. 분산은 먼저 자료가 평균에서 벗어난 정도(자료의 각 값 (\(x_{i}\)) 빼기 평균값 \(\overline{x}\))를 먼저 구하고, 그 뺀 값을 제곱(\({(x_{i} - \overline{x})^2}\))한 다음(음수와 양수가 있기 때문에 제곱해서 양수로 만든다), 모두 더하고(\(\Sigma\)), \(n\)으로 나눈다. 이를 공식으로 표현하면 다음과 같다. (\(\Sigma\) (시그마)는 ’더하다’는 의미 Sum의 첫 글자 S 그리스 알파벳으로 모두 더한라는 의미다.)
\[ \frac{\Sigma(x_{i} - \overline{x})^2}{n}\]
위 공식을 적용해 분산을 구하는 사용자 함수를 만들어 분산을 계산해보자. (표본에서 실제로 분산을 구할 때 분모에서 n - 1을 한 이유는 n으로 나눌때보다 변이의 정도가 더 정확하게 나오기 때문이다.)
var_f <- function(x){
m <- sum(x)/length(x)
output <- sum((x - m)^2)/(length(x) - 1)
return(output)
}
var_f(2:7)## [1] 3.5변이를 달리한 벡터를 만들어 분산을 비교해보자. R의 기본함수는 var()
var_big <- c(1, 4, 9, 16, 25, 36, 49, 81)
var_small <- c(1, 2, 3, 4, 5, 6, 7, 8, 9)
var_f(var_big)## [1] 733.125var_f(var_small)## [1] 7.53.1.3.3 표준편차
자료가 평균에서 벗어난(deviation) 정도. 분산의 제곱근(square root: sqrt())이다.
사용자함수를 만들어 표준편차를 계산해보자.
sd_f <- function(x){
m <- sum(x)/length(x)
s <- sum((x - m)^2)/(length(x) - 1)
output <- sqrt(s)
return(output)
}
sd_f(2:7)## [1] 1.8708293.1.3.4 사분범위
4분범위(IQR: InterQuartile Range)는 3사분위수(Q3)에서 1사분위수(Q1) 사이의 범위. (4분위수는 전체 자료를 순서대로 4등분해 각 지점에 해당하는 값.)
1사분위(Q1): 1/4 지점
2사분위(Q2): 2/4 지점 == 중간값
3사분위(Q3): 3/4 지점
4분범위(Q3 - Q1)는 IQR()함수로 구할 수 있다.
number_v <- c(1, 2, 3, 4, 5, 6, 7, 8, 9)
IQR(number_v)## [1] 4평균에서 벗어난 정도는 표준편차를 이용한다. 평균에서 표준편차의 n배 떨어진 정도를 ’n표준편차’라고 한다. 예를 들어, 평균에서 표준편차의 2배 떨어져 있으면 ’2표준편차’라고 표현한다.
중간값에서 벗어난 정도는 IQR를 이용한다.
평균과 표준편차를 구할 수 있는 변수는 등간척도 혹은 비율척도로 측정한 변수다. 서열척도로 측정한 변수는 중간값과 사분범위를 계산한다.
이제 갑돌이가 수집한 자료에서 연속변수(나이, 복용량, 기력)의 개수, 평균 및 표준편차를 구해보자. dplyr패키지의 summarise()함수를 이용한다. (아래 코드의 summarise.()는 처리속도가 빠른 tidytable()함수).
df %>%
summarize.(mean_age = mean(age), sd_age = sd(age),
mean_dose = mean(dose), sd_dose = sd(dose),
mean_vigor = mean(vigor), sd_vigor = sd(vigor),
n = n()) %>% round(2) %>%
gt() %>% tab_header("나이, 복용량, 기력의 평균과 표준편차")| 나이, 복용량, 기력의 평균과 표준편차 | ||||||
|---|---|---|---|---|---|---|
| mean_age | sd_age | mean_dose | sd_dose | mean_vigor | sd_vigor | n |
| 35.78 | 8.72 | 39.98 | 5.32 | 99.96 | 10.64 | 180 |
성별 그리고 종별 복용량과 기력을 구해보자. .by =인자를 추가하면 된다.
df %>%
summarise.(mean_dose = mean(dose), sd_dose = sd(dose),
mean_vigor = mean(vigor), sd_vigor = sd(vigor),
n = n(),
.by = c(sex, species)
) %>%
gt() %>%
tab_header("성과 종별 나이, 복용량, 기력의 평균과 표준편차") %>%
fmt_number(contains("_"), decimals = 2) # "_"이 포함된 열형식 지정| 성과 종별 나이, 복용량, 기력의 평균과 표준편차 | ||||||
|---|---|---|---|---|---|---|
| sex | species | mean_dose | sd_dose | mean_vigor | sd_vigor | n |
| 남성 | 저그 | 40.26 | 4.12 | 100.51 | 8.23 | 28 |
| 여성 | 저그 | 39.38 | 5.82 | 98.76 | 11.65 | 32 |
| 여성 | 테란 | 39.97 | 5.40 | 99.93 | 10.81 | 25 |
| 남성 | 테란 | 40.33 | 5.72 | 100.66 | 11.44 | 35 |
| 남성 | 프로토스 | 39.57 | 5.76 | 99.15 | 11.52 | 34 |
| 여성 | 프로토스 | 40.49 | 4.97 | 100.99 | 9.94 | 26 |
3.1.4 시각화
숫자로 된 기술통계치만으로는 자료의 특성을 파악하기 어렵다. 시각화를 통해 확인해볼 필요가 있다. 가장 많이 쓰이는 도표가 상자도(box plot), 산점도(scatter plot), 바이올린 플롯, 시나플롯(sina plot), 점도표(dot plot) 등이 있다.
상자도는 손으로 도표를 그려야 하던 시절에 개발된 방식으로 가장 많이 쓰이는 도표이나 자료를 지나치에 단순화하는 단점이 있다. 산점도와 바이올린플롯이 그 단점을 보완해주지만 여전히 장단점이 있다. 이상적인 도표는 산점도와 바이올린 플롯의 장점을 모두 취한 시나플롯(sina plot)이다.
3.1.4.1 상자도
가상의 자료를 만들어 상자도(box plot)를 그려보자. 상자수염도(box-and-whisker plot)이라고도 한다. 상자 아래위로 그은 선이 수염에 해당.
v <- c(1,2,3,4,5,6,7,8,14)
quantile(v)## 0% 25% 50% 75% 100%
## 1 3 5 7 14data.table(v = v) %>%
ggplot(aes(x = v)) +
geom_boxplot() +
labs(title = "상자도")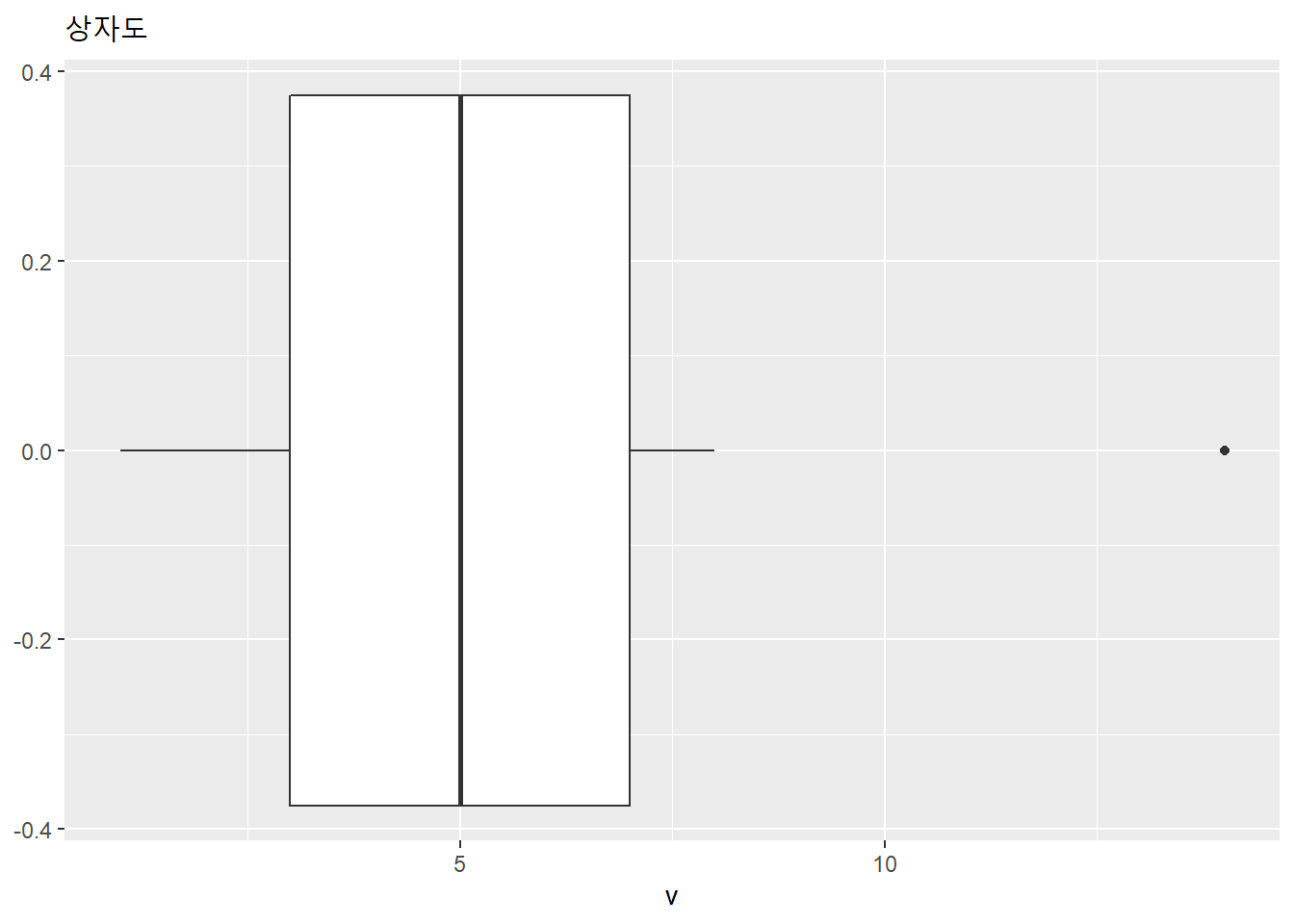
y축에 기력의 값이 나오도록 바꿔보자.
v <- c(1,2,3,4,5,6,7,8,14)
data.table(v = v) %>%
ggplot(aes(y = v)) +
geom_boxplot() +
labs(title = "상자도")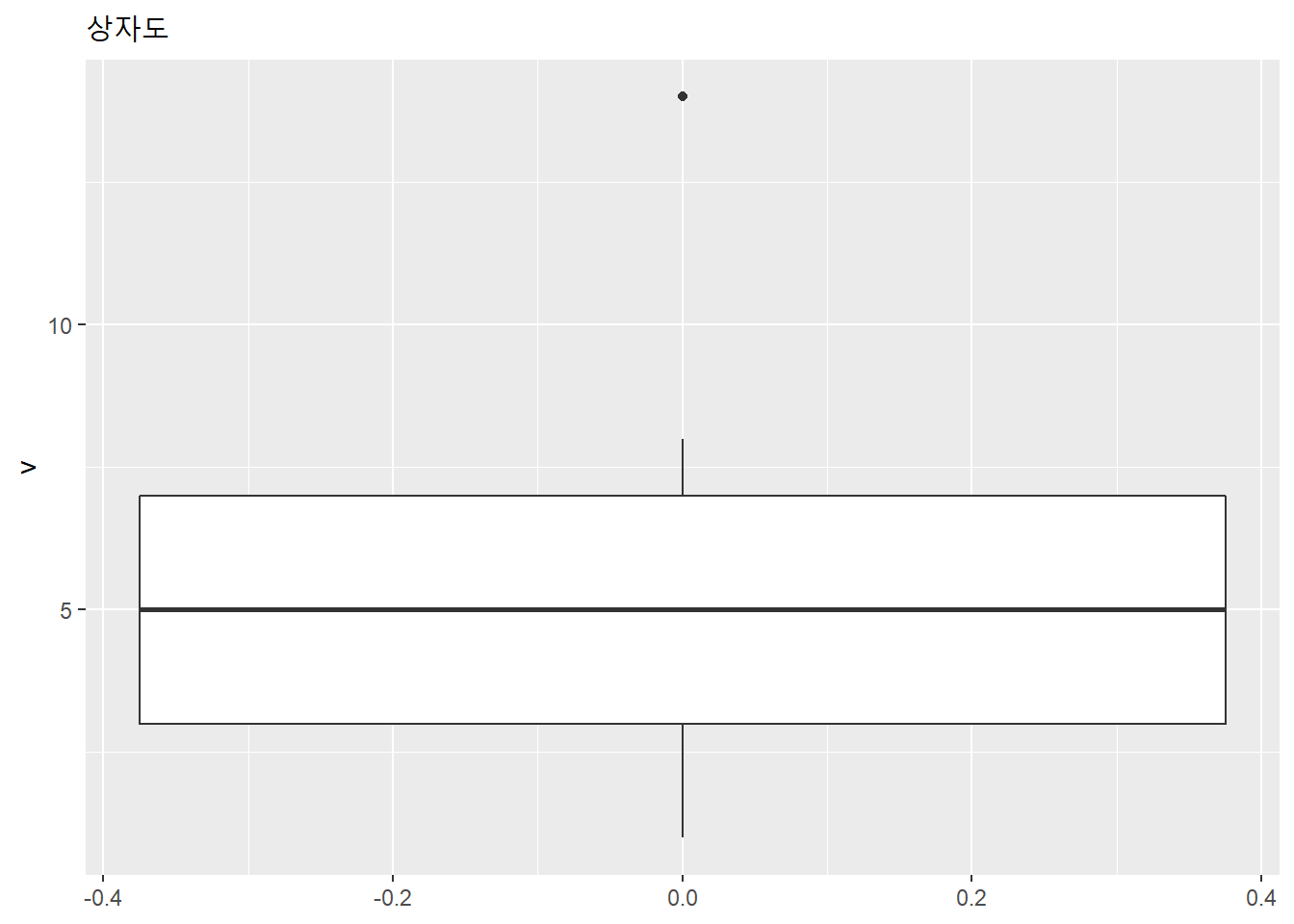
상자도의 상자는 사분위수를 나타낸다.
v <- c(1,2,3,4,5,6,7,8,14)
data.table(v = v) %>%
ggplot(aes(y = v)) + xlim(-1.5, .65) + ylim(-2.5, 16) +
geom_boxplot() +
annotate("text", x = -1, y = 7+1,
label = "Q3: 75%", size = 5) +
geom_segment(aes(x = -.75, xend = -.4, y = 7+1, yend = 7),
size = 1.3, col = "#DC143C", arrow = arrow()) +
annotate("text", x = -1, y = 5,
label = "Q2: 중간값", size = 5) +
geom_segment(aes(x = -.75, xend = -.4, y = 5, yend = 5),
size = 1.3, col = "#DC143C", arrow = arrow()) +
annotate("text", x = -1, y = 3-1,
label = "Q1: 25%", size = 5) +
geom_segment(aes(x = -.75, xend = -.4, y = 3-1, yend = 3),
size = 1.3, col = "#DC143C", arrow = arrow()) +
annotate("text", x = -.7, y = 14+1,
label = "이상치(outlier)", size = 5) +
geom_segment(aes(x = -.4, xend = -.05, y = 14+1, yend = 14),
size = 1.3, col = "#DC143C", arrow = arrow()) +
annotate("text", x = -.7, y = 11.5,
label = "1.5 IQR 이내 최대값", size = 5) +
geom_segment(aes(x = -.3, xend = 0, y = 11, yend = 8),
size = 1.3, col = "#DC143C", arrow = arrow()) +
annotate("text", x = -.7, y = -1,
label = "1.5 IQR 이내 최소값", size = 5) +
geom_segment(aes(x = -.3, xend = 0, y = -1, yend = 1),
size = 1.3, col = "#DC143C", arrow = arrow()) +
annotate("text", x = .6, y = 5,
label = "IQR", size = 5) +
geom_curve(aes(x = .4, xend = .4, y = 3, yend = 7),
size = 1.3, col = "#DC143C") +
labs(title = "상자도") +
theme(title = element_text(size = 15))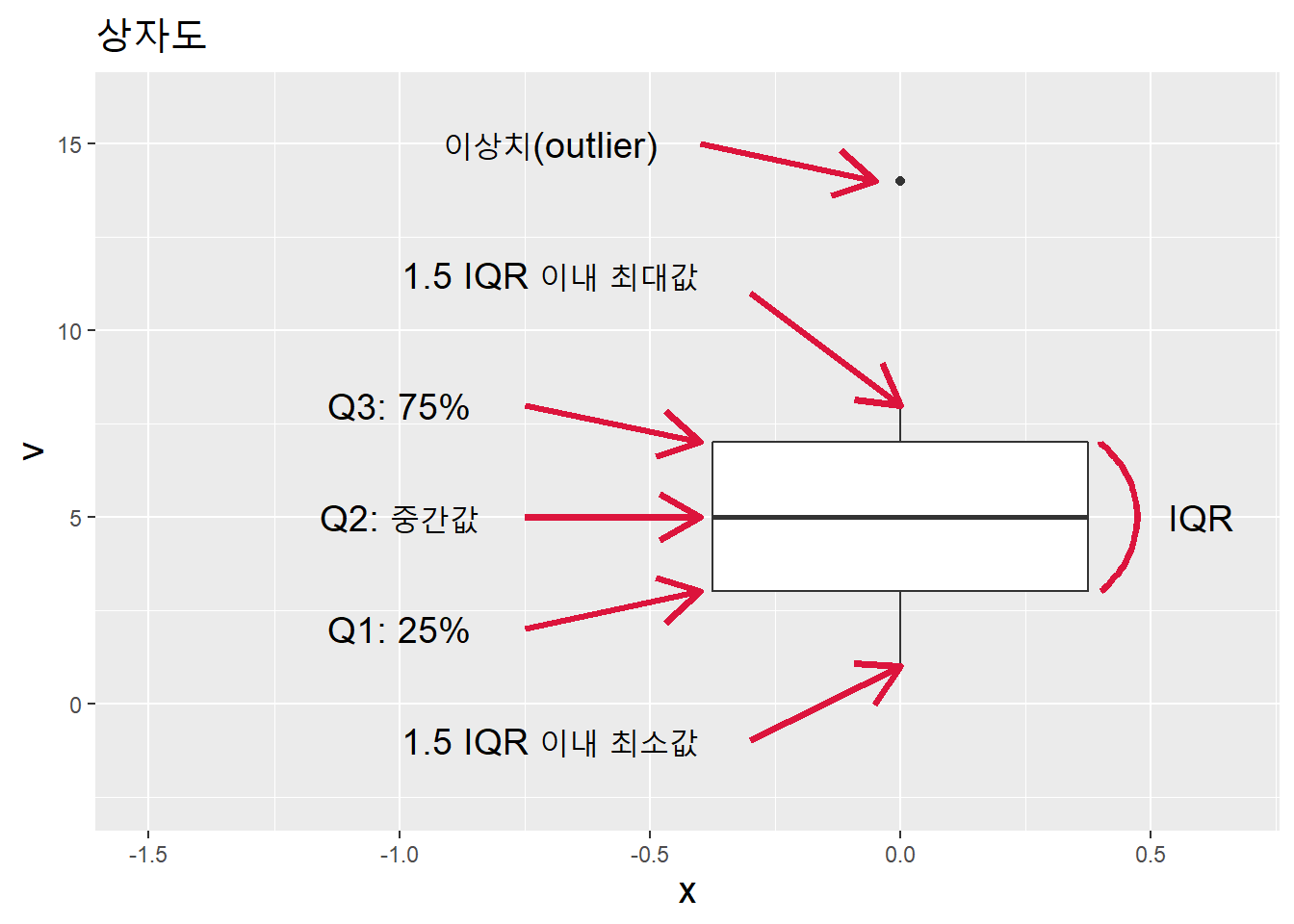
기력을 성별로 구분해 상자도로 그려보자.
df %>%
ggplot(aes(x = sex, y = vigor)) +
geom_boxplot() +
labs(title = "상자도: 성별 기력")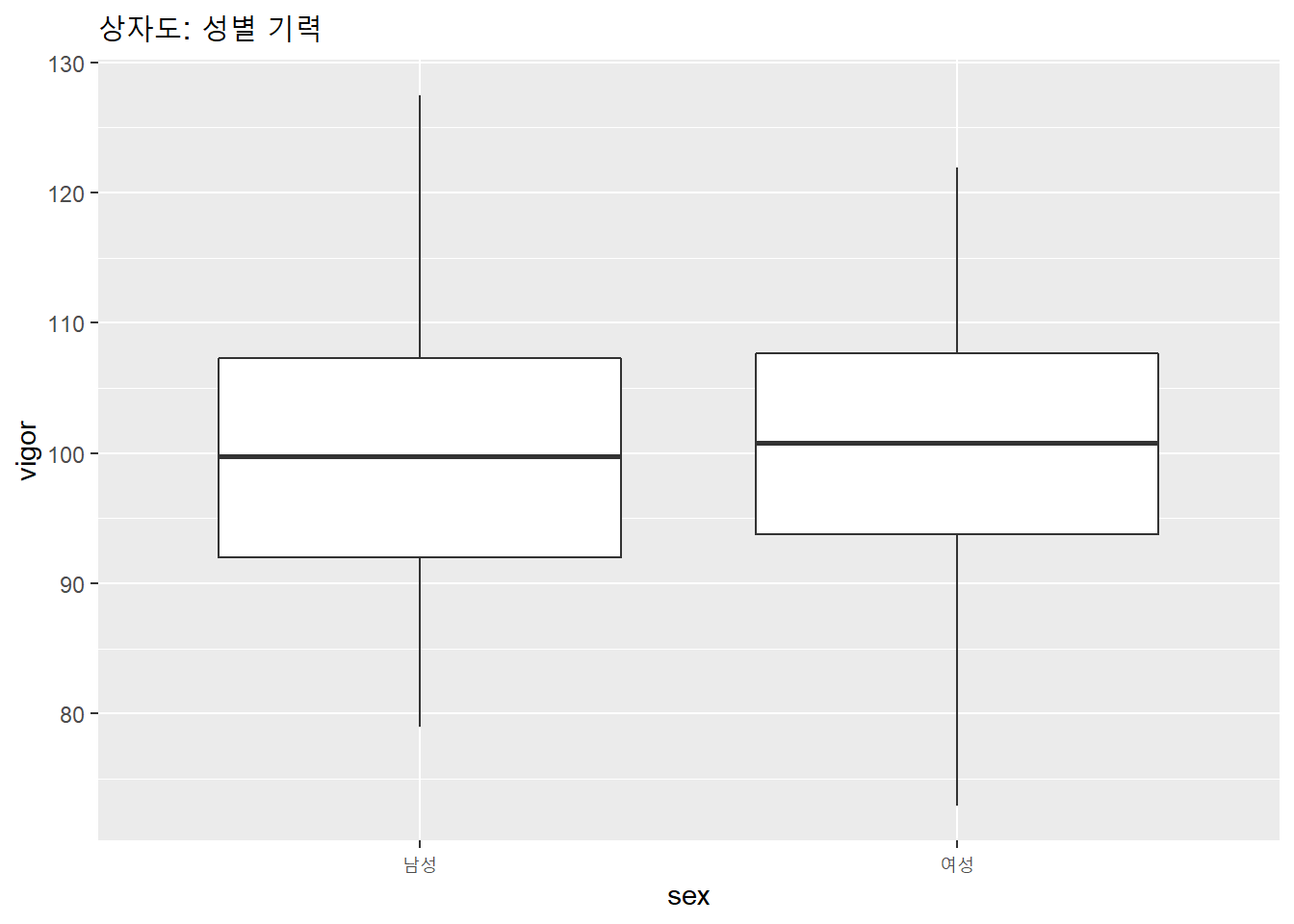
3.1.4.2 바이올린 플롯
상자도가 과도하게 단순화한 단점을 극복하기 위해 고안된 도표다.
df %>%
ggplot(aes(x = sex, y = vigor, fill = sex)) +
geom_violin(width = .5) +
labs(title = "바이올린플롯: 성별 기력")
3.1.4.3 산점도
산점도(scatter plot)는 각 값의 구체적인 분포를 제시하는 장점이 있다. 산점도위에 결합해 그릴 수 있다.
df %>%
ggplot(aes(x = sex, y = vigor, fill = sex)) +
geom_violin(width = .5) +
geom_point() +
labs(title = "바이올린플롯&산점도: 성별 기력")
각 값의 분포가 제대로 나타나지 않는다. 값의 위치가 같으면 동일한 위치에 표시하는 것이 기본값이기 때문이다(position = "identity). position =인자에 "jitter"를 투입하면 값들의 겹치지 않게 표시된다.
df %>%
ggplot(aes(x = sex, y = vigor, fill = sex)) +
geom_violin(width = .5) +
geom_point(position = "jitter", alpha = .4) +
labs(title = "바이올린플롯: 성별 기력")기본값이 "jitter"인 geom_jitter()로 산점도를 그리면 더 간단하다.
df %>%
ggplot(aes(x = sex, y = vigor, fill = sex)) +
geom_violin(width = .5) +
geom_jitter(alpha = .4) +
labs(title = "바이올린플롯: 성별 기력")
3.1.4.4 시나플롯
ggforce패키지의 시나플롯은 산점도와 바이올린플롯의 장점을 결합해 각 값의 분포를 바이올린플롯처럼 보여준다.
if(!require(ggforce)) install.packages("ggforce")
library(ggforce)
df %>%
ggplot(aes(x = sex, y = vigor, color = sex)) +
geom_sina() +
labs(title = "시나플롯: 성별 기력")
상자도의 상자가 통계치를 표시하므로 시나플롯과 함께 사용하면 더 풍부한 시각화를 할 수 있다.
df %>%
ggplot(aes(x = sex, y = vigor, color = sex)) +
geom_boxplot() +
geom_sina(alpha = .4) +
labs(title = "상자도&시나플롯: 성별 기력")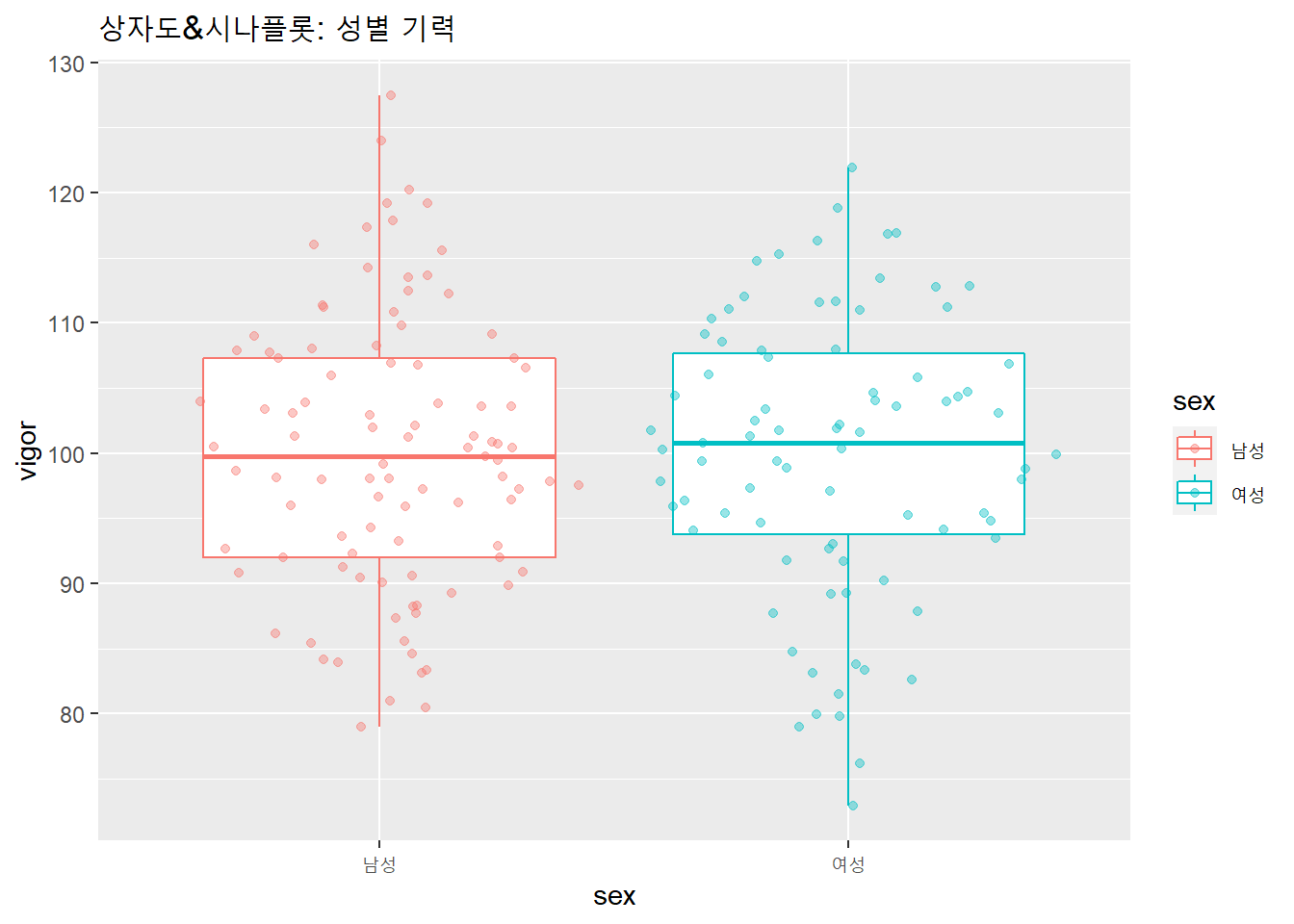
값의 수가 많지 않을 때는 점도표(dotplot)을 이용할 수 있다.
df %>%
ggplot(aes(x = sex, y = vigor, color = sex)) +
geom_dotplot(binaxis = "y", stackdir = "center") +
labs(title = "점도표: 성별 기력")## Bin width defaults to 1/30 of the range of the data. Pick better value with `binwidth`.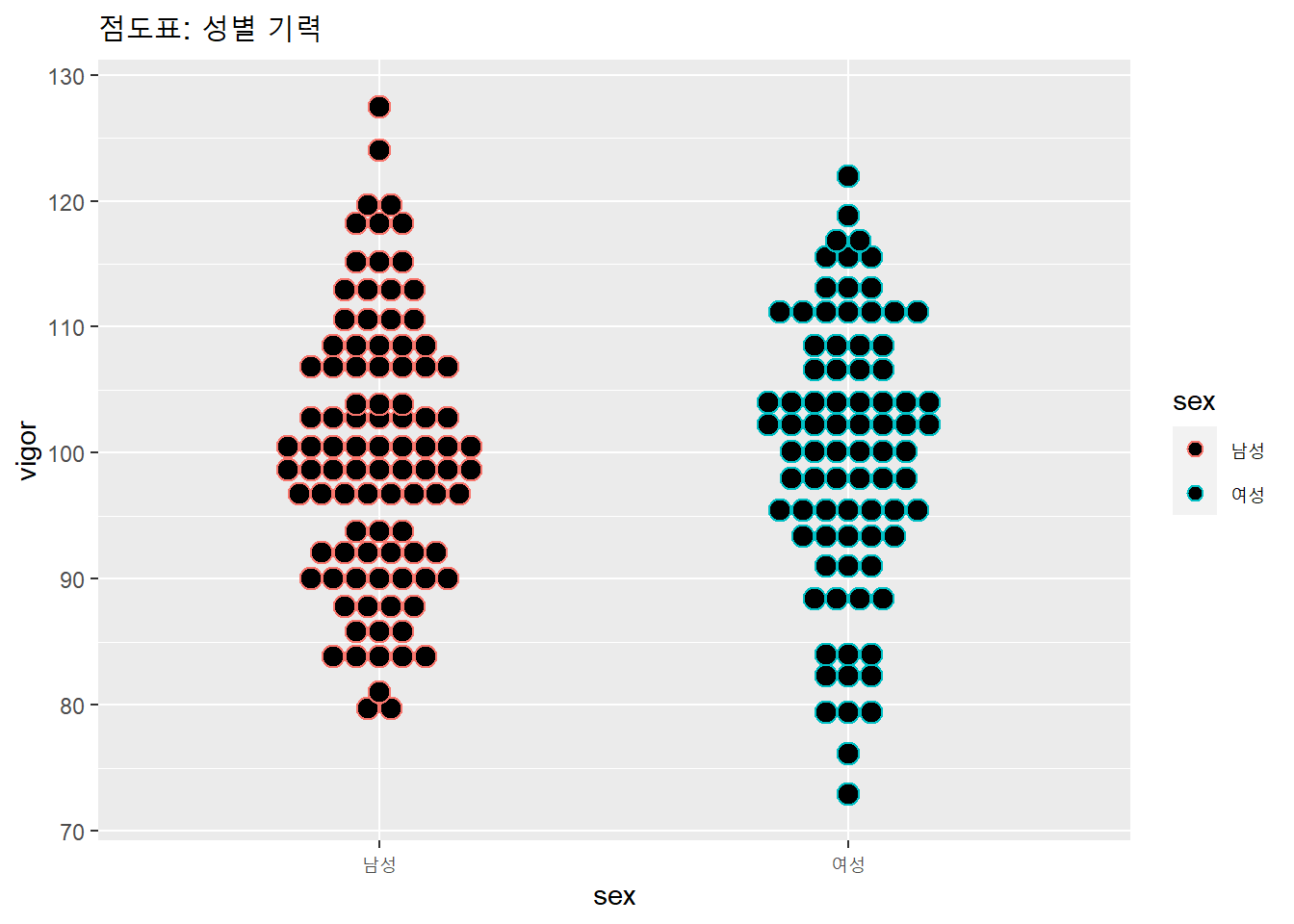
값이 너무 많은 자료를 점도표로 그리면 아래처럼 한 화면에 제대로 표시할 수 없게 된다.
data.frame(x = factor(rbinom(10000, 1, .5)),
y = rnorm(10000, 10, 5)) %>%
ggplot(aes(x = x, y = y, fill = x)) +
geom_dotplot(binaxis = "y", stackdir = "center")## Bin width defaults to 1/30 of the range of the data. Pick better value with `binwidth`.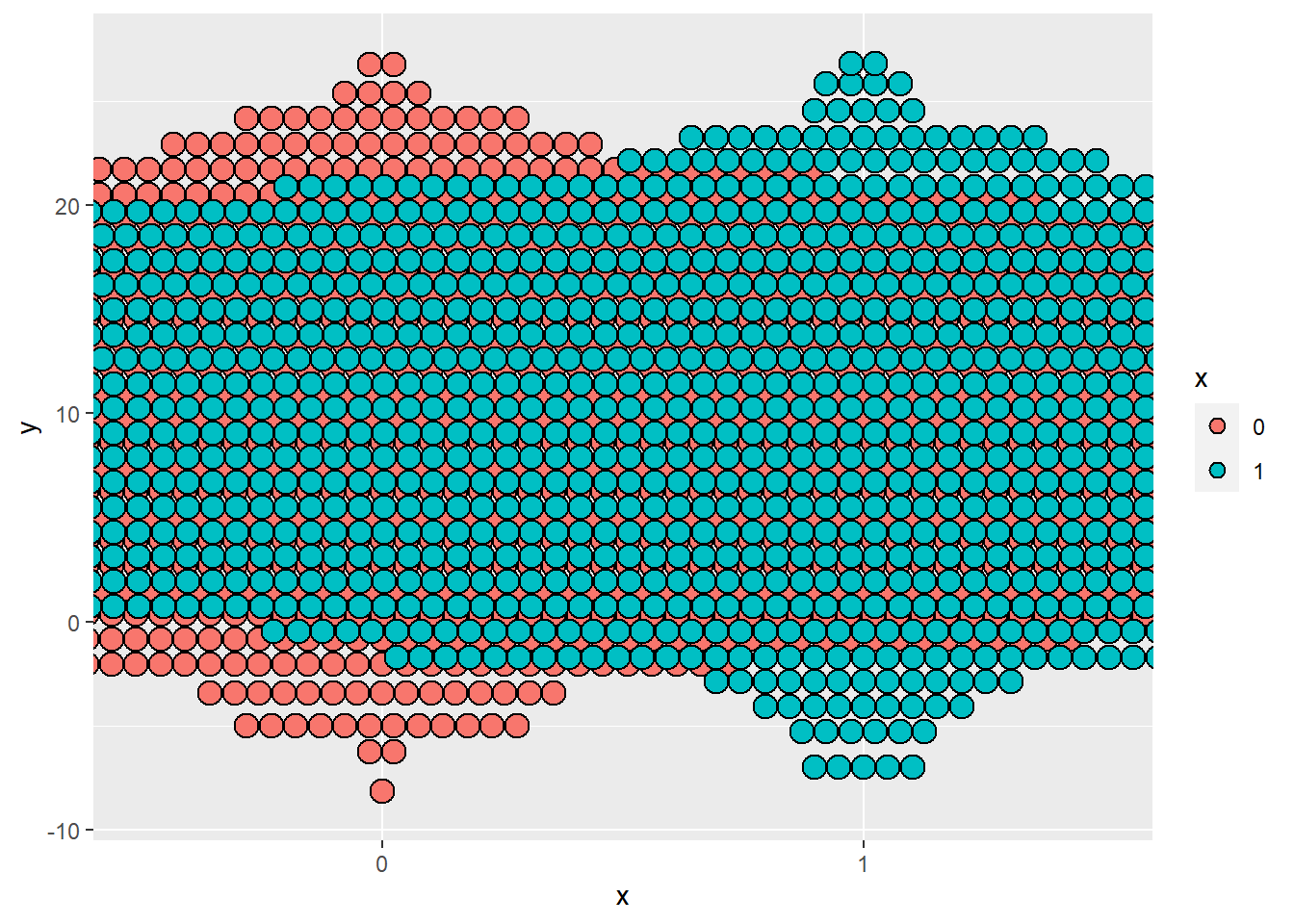
3.1.4.5 자료구조변형
연속변수는 나이, 복용량, 기력 등 3개다. 이 3개 변수의 기술통계를 상자도와 시나플롯으로 표시하려면 어떻게 해야 할까?
3개의 열로 있는 나이, 복용량, 기력 등 3개 변수를 하나의 열로 바꿔야 한다. 열방향으로 길게 구성한다고 해서 롱폼(long-form)이라고 한다. tidyr패키지의 pivot_longer()함수를 이용한다. (실제 이용 함수는 tidytable패키지의 pivotlonger.())
자료구조를 열의 상하방향 혹은 좌우방향으로 바꾸는 것을 피보팅(pivoting)이라고 한다.
결합할 열을 cols =인자로 지정하면, name열과 value열이 생성된다. name열에는 기존 열의 이름이 값으로 투입되고, value열에는 기존 열에 있던 값이 투입된다.
df %>% pivot_longer.(cols = c(age, dose, vigor)) %>% str()## Classes 'tidytable', 'data.table' and 'data.frame': 540 obs. of 5 variables:
## $ id : chr "저그1" "저그2" "저그3" "저그4" ...
## $ sex : Factor w/ 2 levels "남성","여성": 1 1 2 2 2 1 1 1 2 2 ...
## $ species: Factor w/ 3 levels "저그","테란",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ name : chr "age" "age" "age" "age" ...
## $ value : num 36 27 22 43 37 23 24 29 35 23 ...
## - attr(*, ".internal.selfref")=<externalptr>새로 생기는 열의 이름을 지정할 수 있다.
df %>% pivot_longer.(
cols = c(age, dose, vigor),
names_to = "변수명",
values_to = "값"
) %>% str()## Classes 'tidytable', 'data.table' and 'data.frame': 540 obs. of 5 variables:
## $ id : chr "저그1" "저그2" "저그3" "저그4" ...
## $ sex : Factor w/ 2 levels "남성","여성": 1 1 2 2 2 1 1 1 2 2 ...
## $ species: Factor w/ 3 levels "저그","테란",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ 변수명 : chr "age" "age" "age" "age" ...
## $ 값 : num 36 27 22 43 37 23 24 29 35 23 ...
## - attr(*, ".internal.selfref")=<externalptr>롱폼으로 만든 도표는 다음과 같다.
df %>% pivot_longer.(cols = c(age, dose, vigor)) %>%
ggplot(aes(x = name, y = value, color = name)) +
geom_boxplot() +
geom_sina(alpha = .4) +
labs(title = "상자도&시나플롯: 나이, 복용량, 기력") +
theme(title = element_text(size = 15))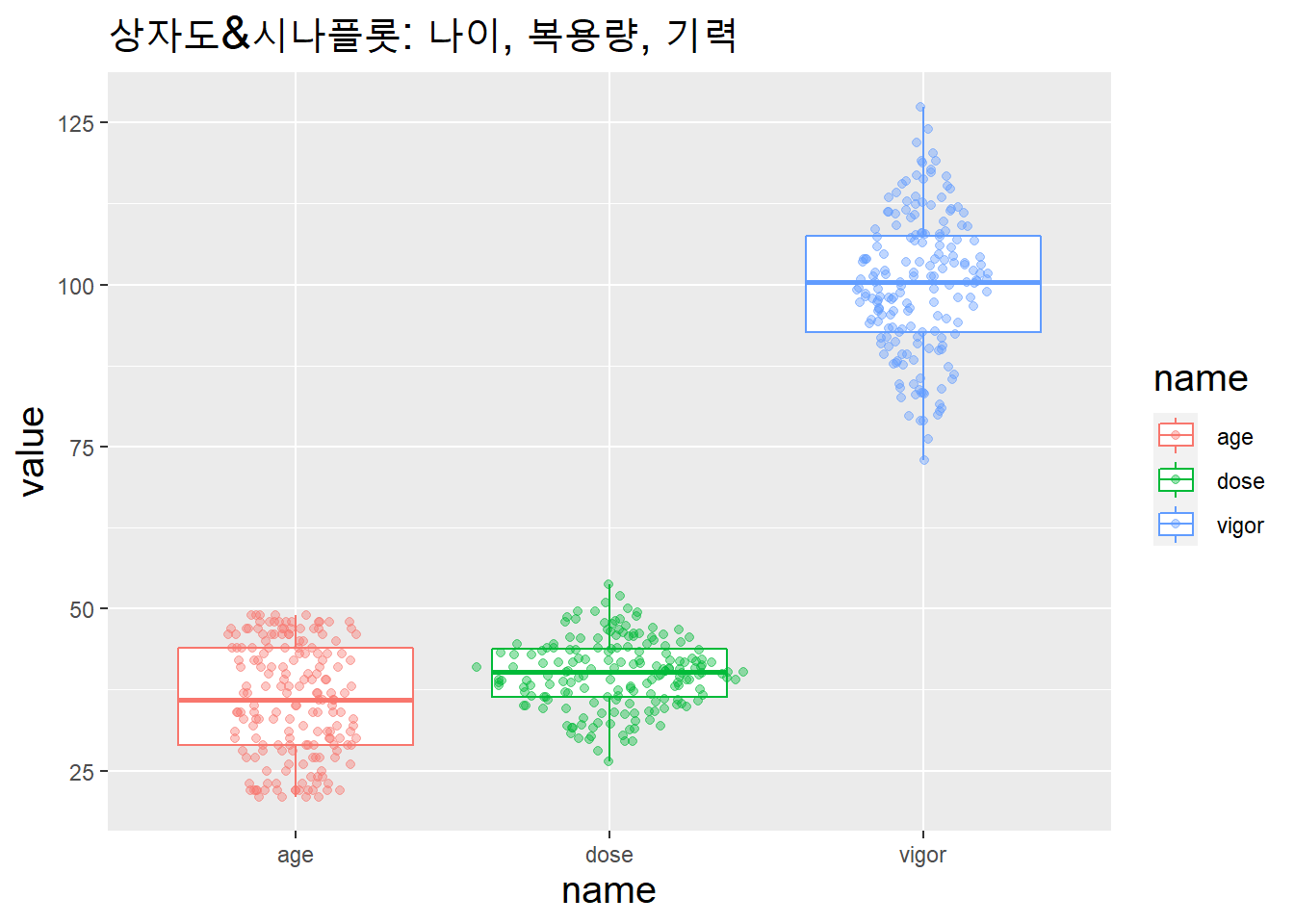
3.2 상관분석
탐색분석에서 한 변수에 대한 기술과 함께 여러 변수 사이의 관계에 대해서도 살펴보게 된다. 변수들 사이의 관계는 불연속변수와 불연속변수, 불연속변수와 연속변수, 연속변수와 연속변수 사이의 관계로 구분해 접근한다.
불연속변수와 불연속변수의 관계는 앞서 교차표를 통해 살펴보는 방법에 대해 학습했다.
불연속변수와 연속변수의 관계는 시나플롯 등을 통해 살펴보는 방법에 대해 학습했다.
연속변수와 연속변수의 관계는 상관도표(correlogram)을 통해 파악할수 있다.
먼저 상관관계에 대해 살펴보자.
상관관계(correlation)는 두 변수가 서로 관련돼 있는 정도다. 양의 상관성은 한 변수가 증가하면 다른 한 변수도 같은 방향으로 증가하고,반대로 음의 상관성은 두 변수의 방향이 반대다. 어떤 사건이 발생하면 다른 사건이 함께 발생하고, 반대로 특정 사건이 발생하면 어떤 현상이 사라진다. 상호 관련성이 있어 상관관계라고 한다.
상관관계의 정도는 상관계수(correlation coefficient) \(r\)로 나타낸다. 두 변수가 평균적으로 각각의 평균을 기준으로 함께 변하는 정도를 나타난다.
- 상관관계의 범위는 -1에서 1까지이다.
- 상관계수가 -1 혹은 1이면 상관성이 완전한 관계이고, 0이면 상관성이 없다. 상관계수가 0.6 이상은 높은 수준의 상관성을 나타낸다. 0.3 이하는 낮은 수준의 상관성.
상관계수 \(r\)로 나타내는 상관관계는 피어슨(Pearson) 상관관계다. 피어슨 상관관계는 등간척도로 측정한 변수의 관계에 사용한다. 서열척도로 측정한 변수는 스피어만(Spearman)이나 켄달(Kendall) 상관관계를 사용한다.
상관계수의 종류는 cor()함수에서 method = 인자로 선택. 피어슨 상관관계는 기본값.
cor(x, ..., method = c("pearson", "kendall", "spearman"))관계의 개념
독립성(indepdence): X와 Y의 두 변수의 관계에서 X변수의 값이 Y변수의 값에 대해 어떤 정보도 제공하지 않는 관계.
연관성(association or dependence): X변수의 값이 Y변수의 값에 유의미한 정보를 제공하는 관계. Y변수가 X 변수에 대해 독립적이지 않다(즉, 종속적이다.). ’X변수의 변이가 Y변수의 변이를 설명한다’고도 표현하다.
상관성(correlation): 상관성은 보다 연관성보다 더 구체적이어서 두 변수의 증가 혹은 감소의 경향을 나타낸다. 즉, 연관성은 상관성보다 더 일반적인 관계를 나타낸다. 범주형 변수와 연속형 변수 사이에는 연관성은 있을 수 있어도, 상관성은 있을 수 없다. 범주형 변수에는 증감이 없기 때문이다(Altman and Krzywinski 2015).
인과성(causality): X변수가 Y변수의 변화를 초래하는 관계. X변수의 정보가 Y변수에 대한 정보를 제공한다(연관성) 해서 반드시 X변수가Y변수의 변화를 초래(인과성)하는 것은 아니다.
다양한 상관관계에 대해 가상의 데이터셋을 만들어 cor()함수로 상관계수를 계산하고, ggplot2로 시각화해보자.
3.2.1 완전한 양(+)의 상관성
한 변수가 평균보다 높을 때 다른 모든 변수도 그 변수의 평균보다 높다.
# 난수 초기값을 73로 지정해 rnorm()으로 생성하는 수 고정
set.seed(73)
# 두 변수로 이뤄진 데이터프레임 생성
var_x <- 1:100 + rnorm(1000, mean = 50, sd = 1)
var_y <- 1:100 + rnorm(1000, mean = 50, sd = 1)
data.table(X = var_x, Y = var_y) -> df
# 상관계수 계산. str_glue로 도표제목에 투입
cor(df$X, df$Y) %>% round(2) -> title_r
# 두 변수로 산점도 구성
ggplot(df, aes(X, Y)) + ylim(50, 170) +
geom_point(col = "deep pink") +
# 마크다운(markdown) 문법으로 문자(이탤릭 등) 꾸미기.
labs(title = str_glue("*r* = {title_r}")) +
mdthemes::md_theme_gray()## Warning: Removed 1 rows containing missing values (geom_point).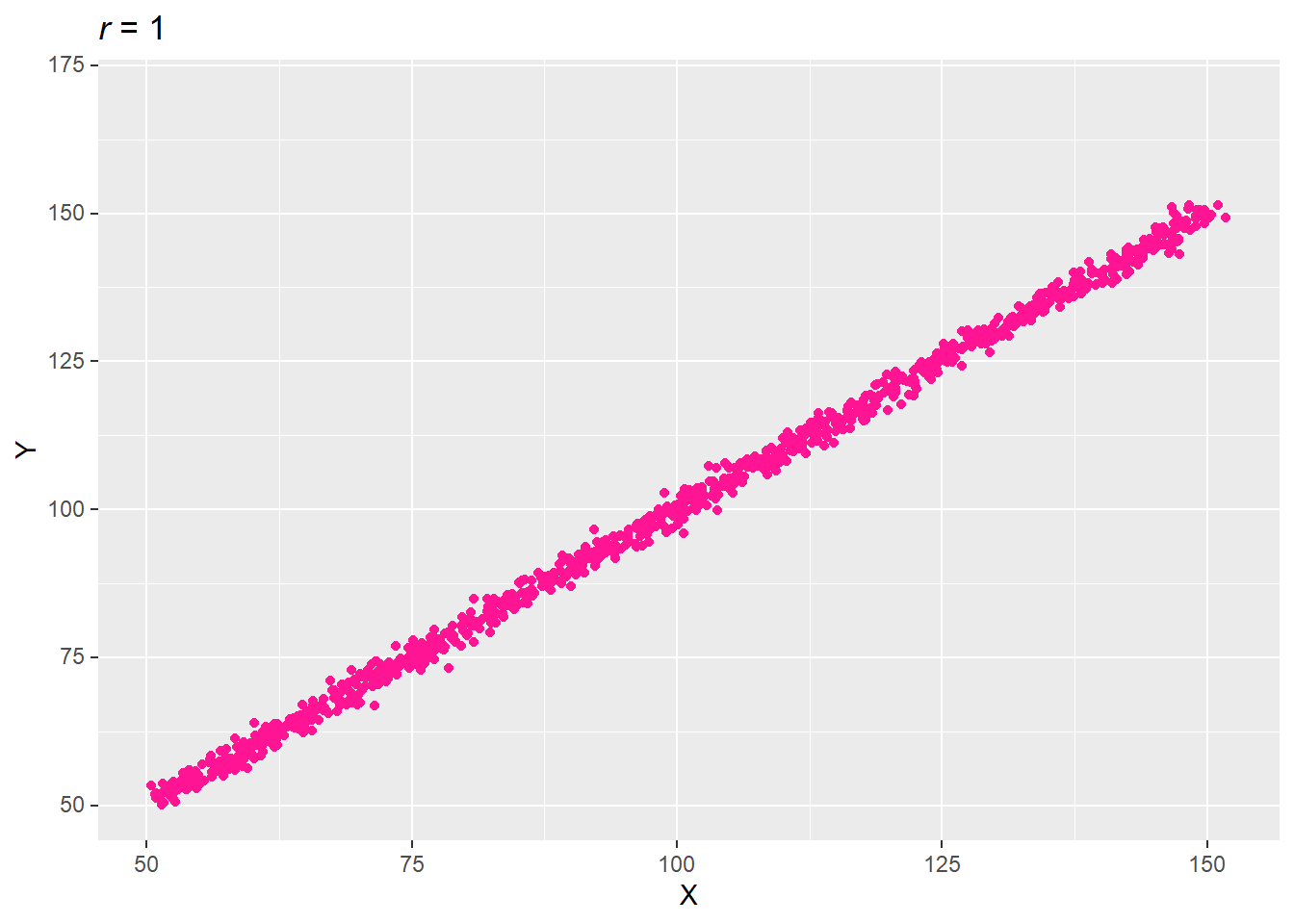
상관성의 정도(상관계수)는 기울기와 무관하다. 상관성의 기울기는 방향성(양의 방향성 vs. 음의 방향성)을 나타낸다.
set.seed(73)
var_x <- seq(1, by = 1, length.out = 100) + rnorm(1000, 50, 1)
var_y <- seq(50, by = .5, length.out = 100) + rnorm(1000, 50, 1)
data.table(X = var_x, Y = var_y) -> df
cor(df$X, df$Y) %>% round(2) -> title_r
ggplot(df, aes(X, Y)) + ylim(50, 170) +
geom_point(col = "deep pink") +
labs(title = str_glue("*r* = {title_r}")) +
mdthemes::md_theme_gray()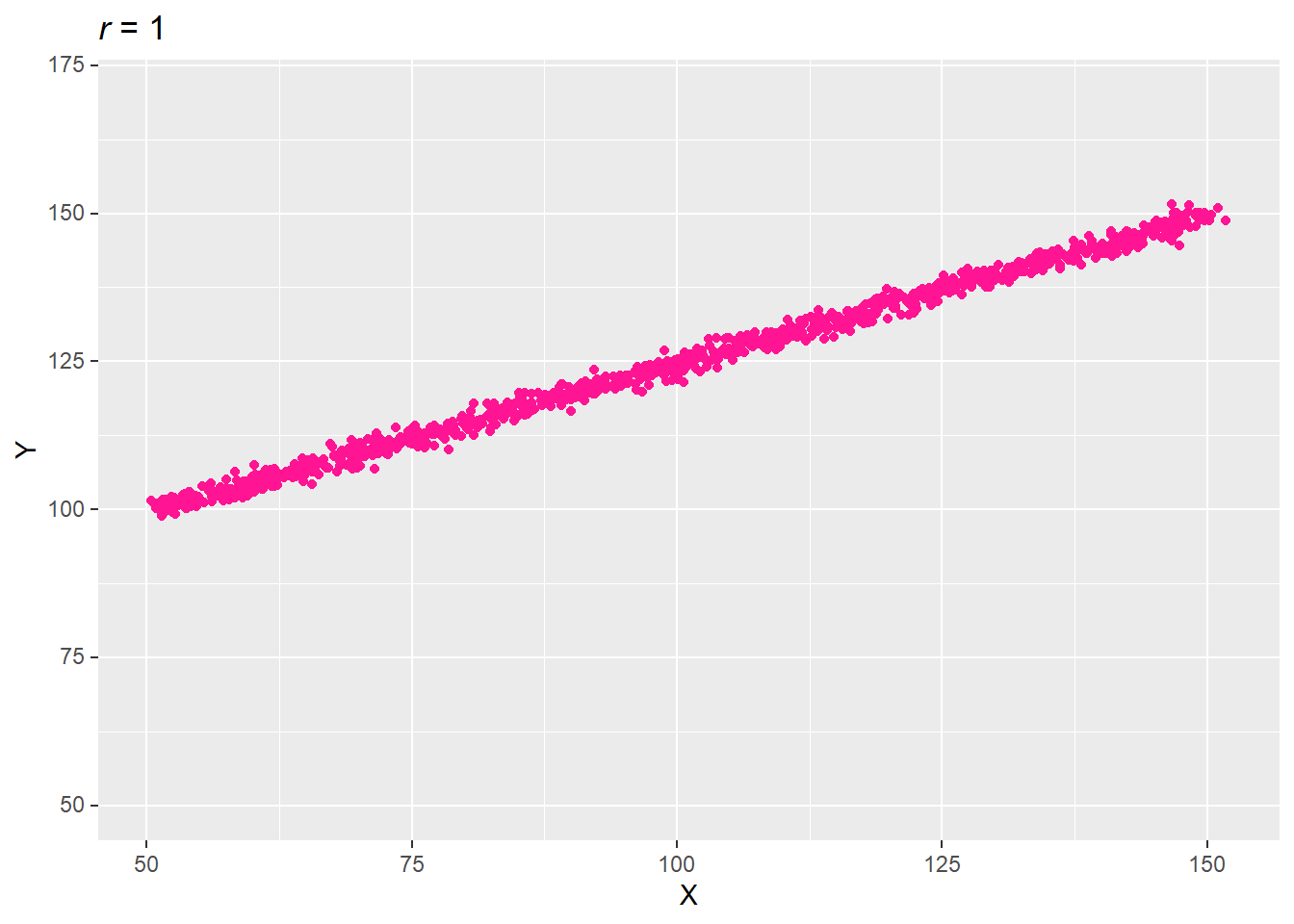
y변수의 증가분(by =)을 .5로 줄이면 기울기가 반으로 줄었지만, 상관계수는 여전히 1이다.
3.2.2 완전한 음(-)의 상관성
한 변수가 평균보다 높을 때 다른 모든 변수는 그 변수의 평균보다 낮은 경우.
set.seed(73)
var_x = 1:100 + rnorm(1000, 50, 1)
var_y = 100:1 + rnorm(1000, 50, 1)
data.table(X = var_x, Y = var_y) -> df
cor(df$X, df$Y) %>% round(2) -> title_r
ggplot(df, aes(X, Y)) + ylim(50, 170) +
geom_point(col = "deep pink") +
labs(title = str_glue("*r* = {title_r}")) +
mdthemes::md_theme_gray()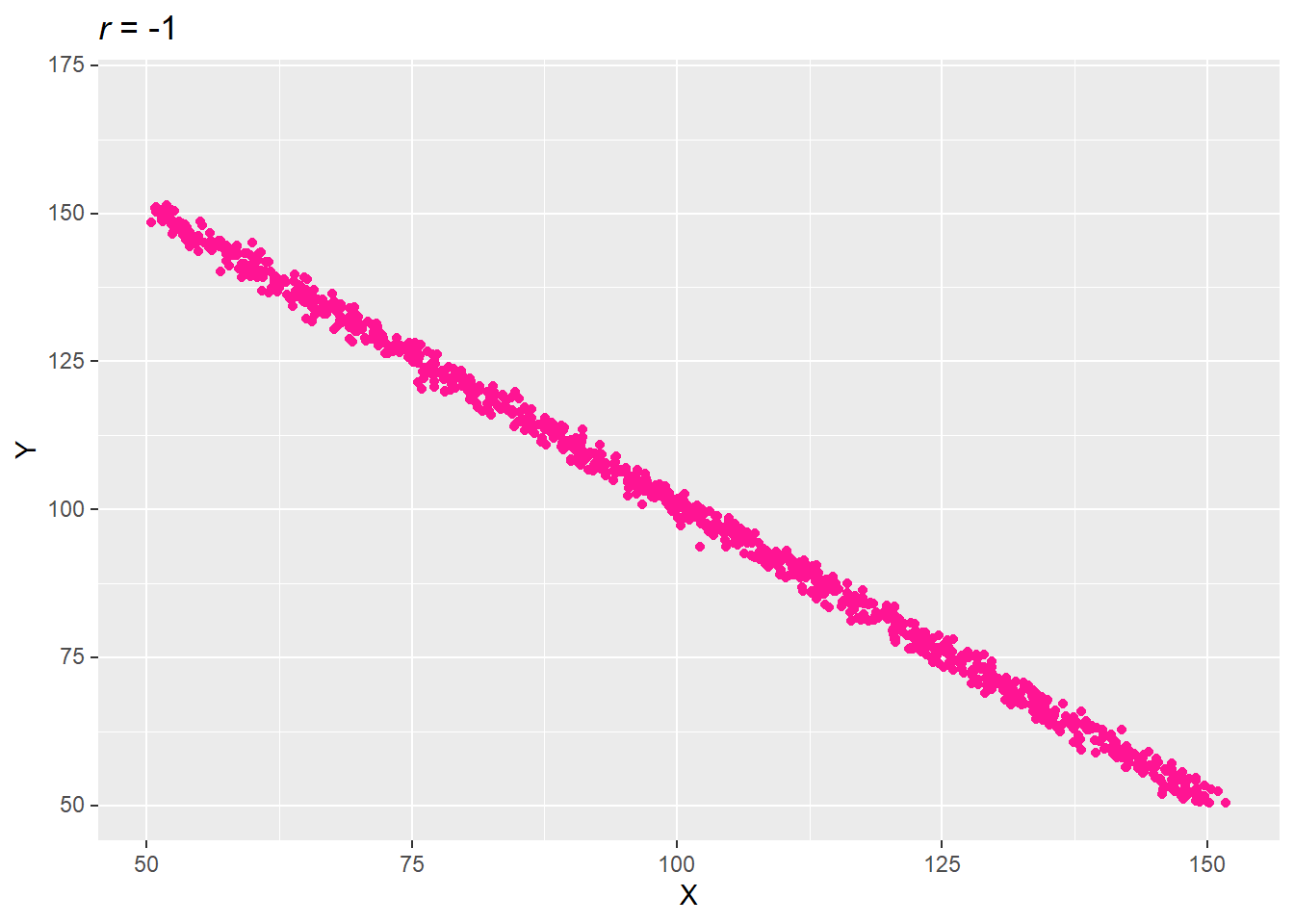
3.2.3 높은 수준의 양의 상관성
상관성의 정도는 분포과 관련돼 있다. 따라서, 가상의 데이터셋에서 분포의 정도인 표준편차를 조정함으로써 상관성의 정도를 바꿀 수 있다.
set.seed(73)
var_x <- 1:100 + rnorm(1000, 50, 20)
var_y <- 1:100 + rnorm(1000, 50, 20)
data.table(X = var_x, Y = var_y) -> df
cor(df$X, df$Y) %>% round(2) -> title_r
ggplot(df, aes(X, Y)) +
geom_point(col = "deep pink") +
labs(title = str_glue("*r* = {title_r}")) +
mdthemes::md_theme_gray()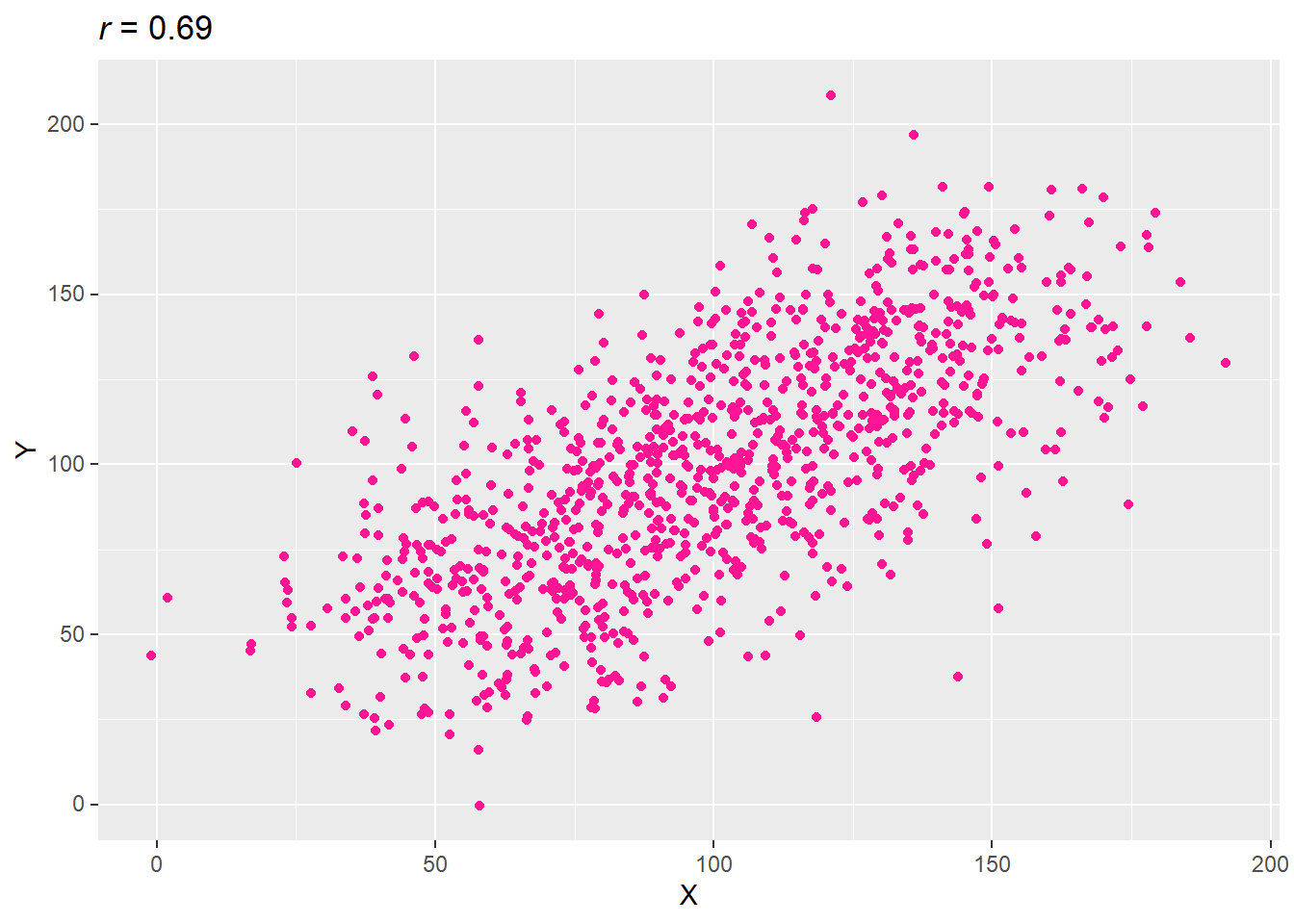
3.2.4 낮은 수준의 양의 상관성
표준편차를 크게 하면 즉 분포를 넓히면 상관성이 낮아진다.
set.seed(73)
var_x = 1:100 + rnorm(1000, 500, 45)
var_y = 1:100 + rnorm(1000, 500, 45)
data.table(X = var_x, Y = var_y) -> df
cor(df$X, df$Y) %>% round(2) -> title_r
ggplot(df, aes(X, Y)) +
geom_point(col = "deep pink") +
labs(title = str_glue("*r* = {title_r}")) +
mdthemes::md_theme_gray()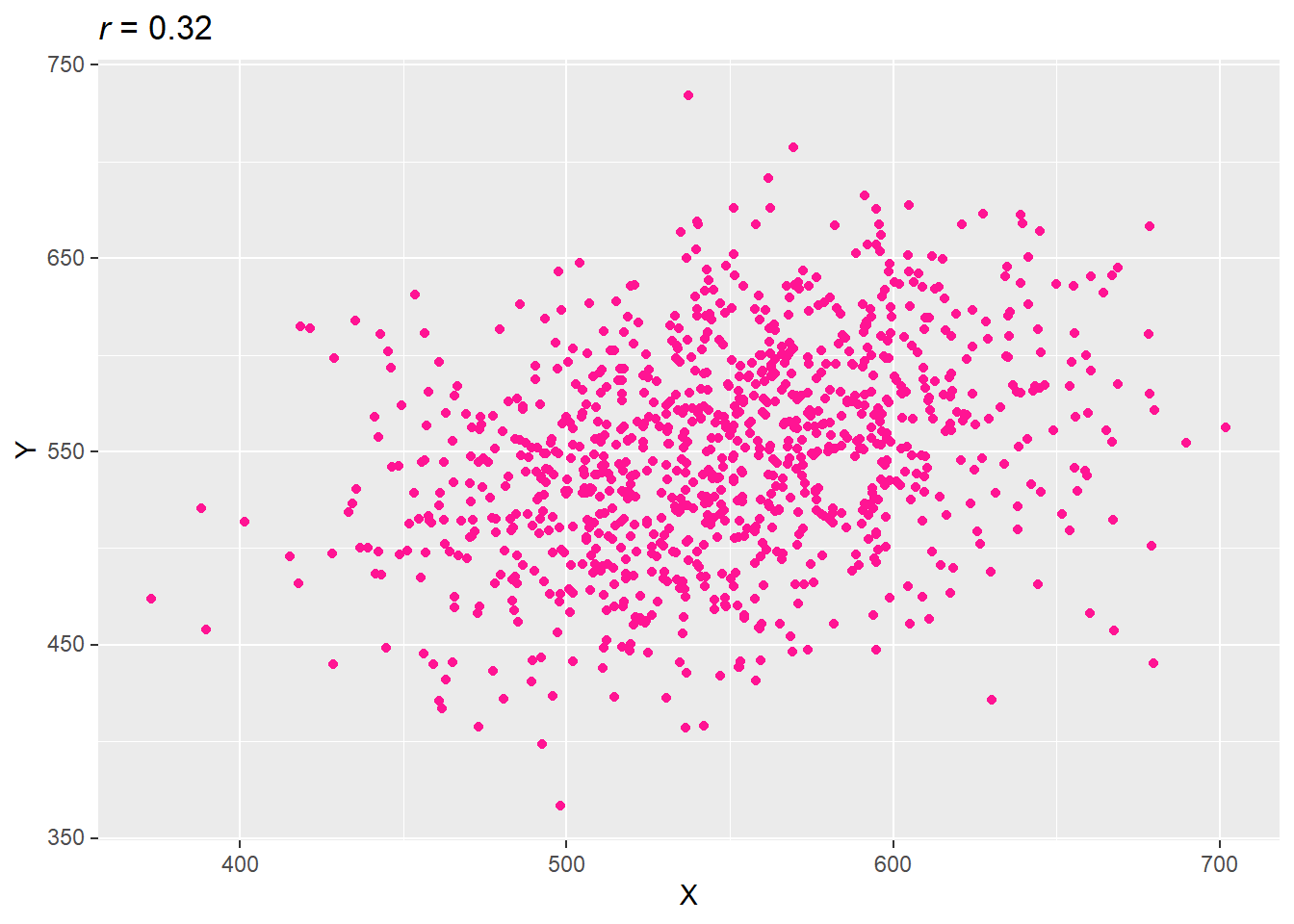
3.2.5 상관성이 없는 경우
방향성이 반대인 두 벡터를 더해 변수를 생성함으로서 상관관계가 0인 데이터셋을 만들었다. (중요: 상관성이 없다고 두 변수의 관계가 없는 것은 아니다. 실질적인 관계가 상관성으로 관측되지 않았을 가능성도 있다.)
set.seed(73)
var_x <- rnorm(1000, 50, 50) + 1000 - rnorm(1000, 50, 50)
var_y <- rnorm(1000, 50, 50) + 1000 - rnorm(1000, 50, 50)
data.table(X = var_x, Y = var_y) -> df
cor(df$X, df$Y) %>% round(2) -> title_r
ggplot(df, aes(X, Y)) +
geom_point(col = "deep pink") +
labs(title = str_glue("*r* = {title_r}")) +
mdthemes::md_theme_gray()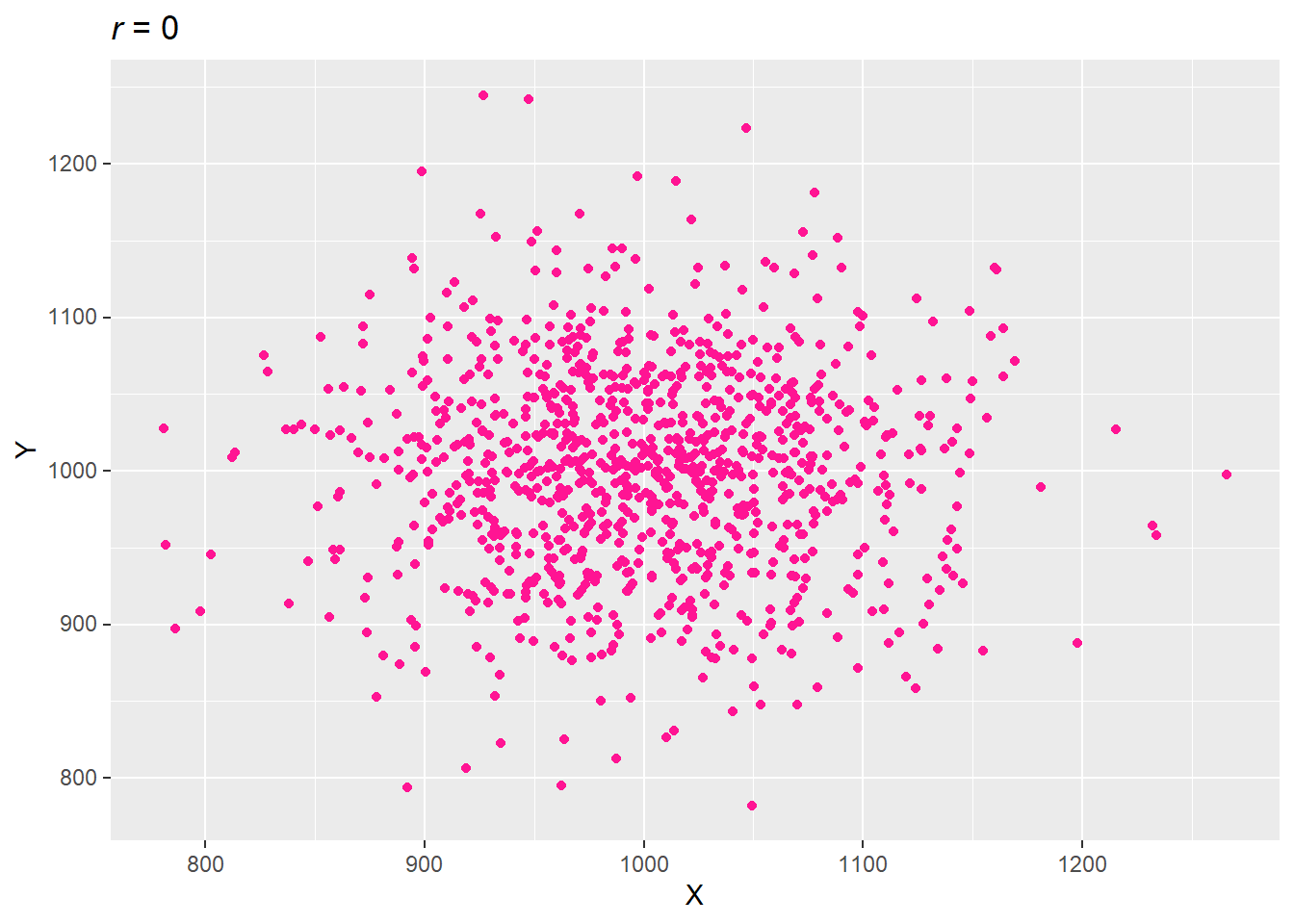
3.2.6 상관도표(correlogram)
상관도표(correlogram) 또는 상관행렬(correlation matrix)을 이용해 두개 이상의 변수들 사이의 관계를 한눈에 볼수 있다. 다양한 패키지가 나와 있다. 이중 GGally패키지가 뛰어나다. 연속변수 뿐 아니라 불연속변수 사이의 연관성도 함께 나타낸다. GGally 매뉴얼.
rio::import("df.xlsx") -> df
df %>%
mutate.(
sex = factor(sex, labels = c("남성", "여성")),
species = factor(species)
) -> df
df %>% select.(-id) %>% ggpairs()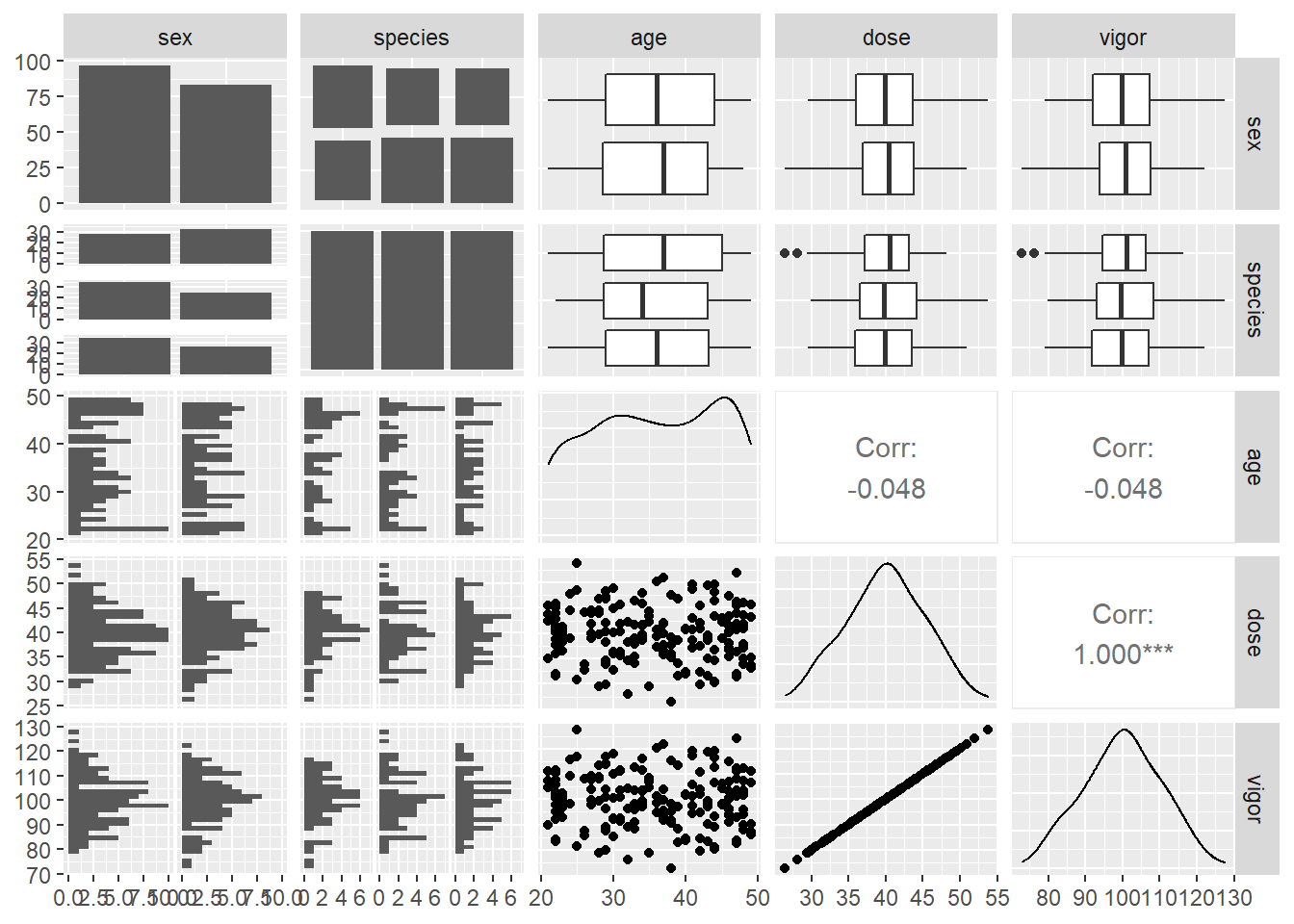
범주별로 색을 구분하면 다음과 같다.
df %>% select(-id) %>%
ggpairs(aes(color = sex))## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.
## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.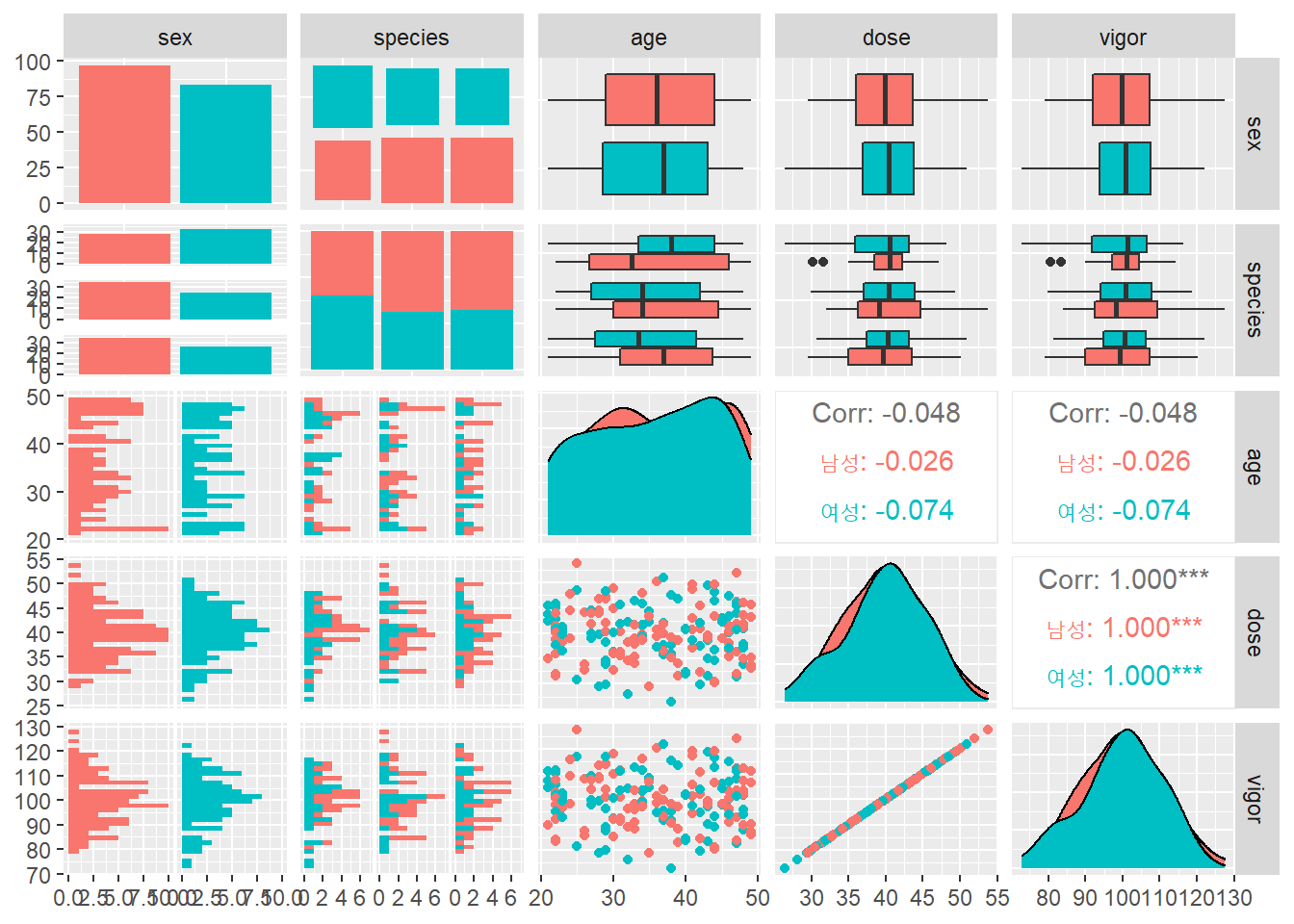
이번에는 실제로 측정한 자료를 이용해 상관도표를 만들어보자.
psychTools패키지의 affect데이터셋은 330명에게 공포, 코미디, 자연다큐, 역사다큐 등 4편의 동영상(9분 길이)을 보게 한 다음 다양한 심리변수(긍정각성, 부정각성, 긍정감정, 부정감정 등)를 측정했다.
data(affect)
affect %>% select.(Film, EA1:NA1) %>%
mutate(Film = factor(Film)) %>%
ggpairs()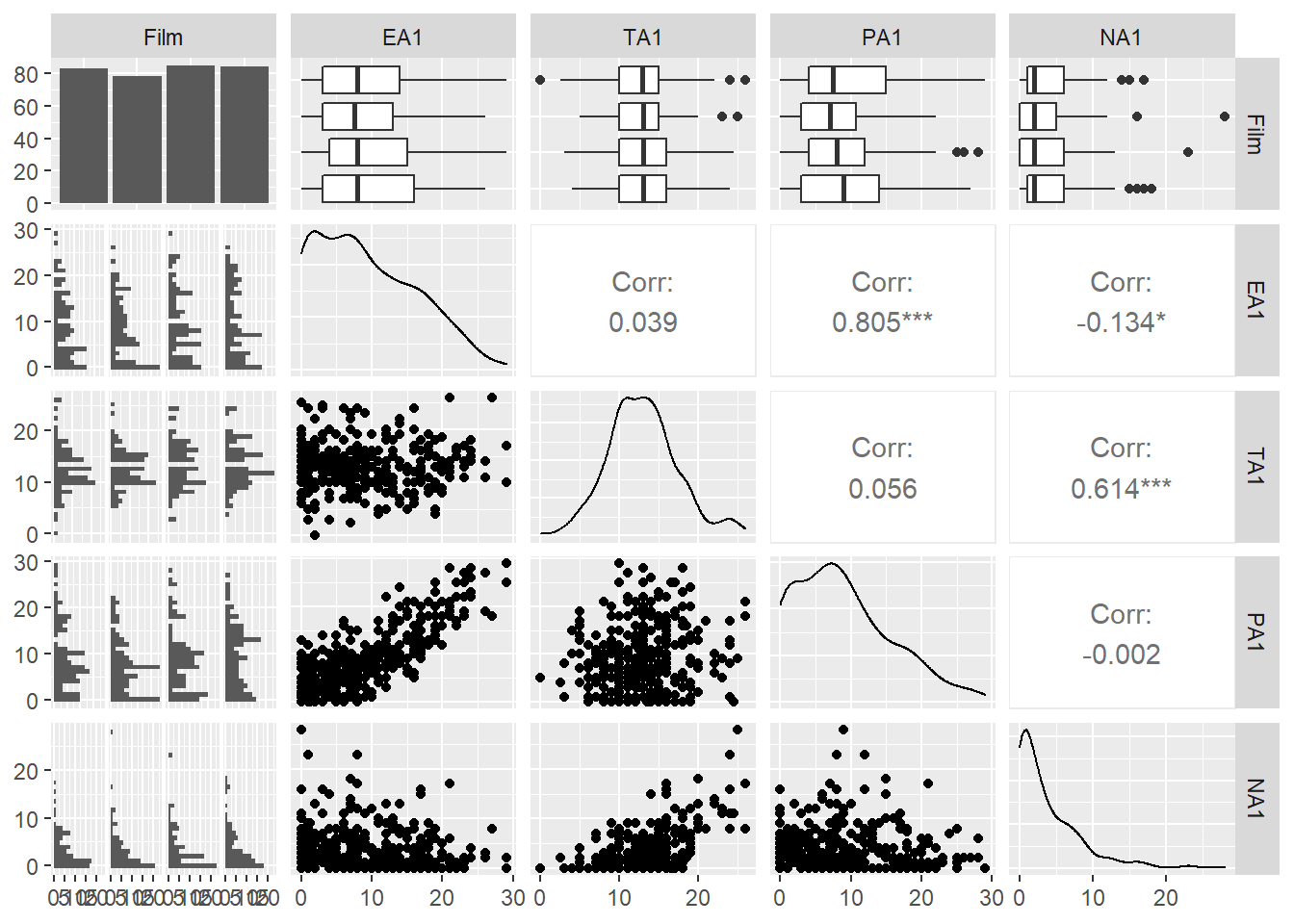
affect %>% select.(Film, EA1:NA1) %>%
mutate(Film = factor(Film)) %>%
ggpairs(aes(color = Film))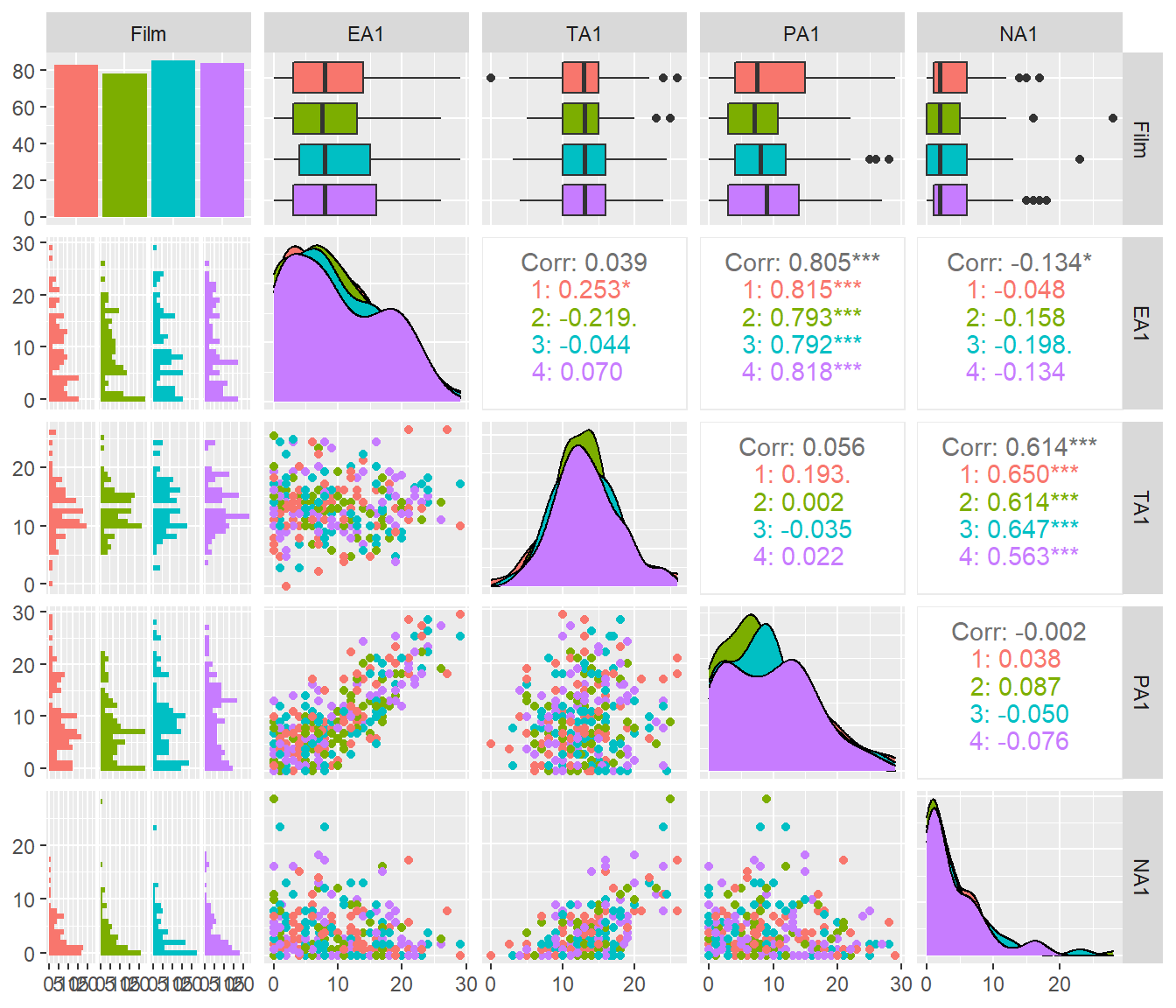
3.3 적용
저그마을에서 모의자료 분석을 하던 갑돌이에게 테란본부에서 연락이 왔다. 이웃 은하계의 지구라는 행성에서 지구인들의 행복에 대해 조사한 자료 분석을 요청하기 위해서다.
갑돌이는 세계행복보고서2021 자료를 받았다. 매년 지구에 있는 거의 모든 나라 주민들의 행복 및 행복관련 변수를 조사한 자료다.
갑돌이는 우선 탐색분석부터 하기로 했다.
3.3.1 수집 및 정제
먼저 분석에 필요한 자료를 가져온 다음, 분석에 필요한 열만 선택한다.
url <- "https://raw.githubusercontent.com/dataminds/art/main/whr/DataForFigure2.1WHR2021C2.xls"
rio::import(url) -> whr_df
dim(whr_df)## [1] 149 20149행 20열의 데이터프레임이다.
names(whr_df)## [1] "Country name"
## [2] "Regional indicator"
## [3] "Ladder score"
## [4] "Standard error of ladder score"
## [5] "upperwhisker"
## [6] "lowerwhisker"
## [7] "Logged GDP per capita"
## [8] "Social support"
## [9] "Healthy life expectancy"
## [10] "Freedom to make life choices"
## [11] "Generosity"
## [12] "Perceptions of corruption"
## [13] "Ladder score in Dystopia"
## [14] "Explained by: Log GDP per capita"
## [15] "Explained by: Social support"
## [16] "Explained by: Healthy life expectancy"
## [17] "Explained by: Freedom to make life choices"
## [18] "Explained by: Generosity"
## [19] "Explained by: Perceptions of corruption"
## [20] "Dystopia + residual"갑돌이가 분석하기로 한 변수는 다음과 같다.
[1] "Country name"
[2] "Regional indicator"
[3] "Ladder score" (Happiness)
[7] "Logged GDP per capita"
[8] "Social support"
[10] "Freedom to make life choices"
[12] "Perceptions of corruption" 먼저 분석에 필요한 열을 부분선택한 다음, 열의 이름을 변경했다. 열 이름이 너무 길고 띄어쓰기가 돼 있기 때문이다.
whr_df %>% select.(1:3, 7, 8, 10, 12) -> df
c("나라", "지역", "행복", "GDP", "사회지지", "자율성", "부패지각") -> colnames(df)
names(df)## [1] "나라" "지역" "행복" "GDP" "사회지지" "자율성" "부패지각"3.3.2 기술통계
그 다음에 자료를 훑어봤다.
str(df)## Classes 'tidytable', 'data.table' and 'data.frame': 149 obs. of 7 variables:
## $ 나라 : chr "Finland" "Denmark" "Switzerland" "Iceland" ...
## $ 지역 : chr "Western Europe" "Western Europe" "Western Europe" "Western Europe" ...
## $ 행복 : num 7.84 7.62 7.57 7.55 7.46 ...
## $ GDP : num 10.8 10.9 11.1 10.9 10.9 ...
## $ 사회지지: num 0.954 0.954 0.942 0.983 0.942 ...
## $ 자율성 : num 0.949 0.946 0.919 0.955 0.913 ...
## $ 부패지각: num 0.186 0.179 0.292 0.673 0.338 ...
## - attr(*, ".internal.selfref")=<externalptr>skim(df)| Name | df |
| Number of rows | 149 |
| Number of columns | 7 |
| Key | NULL |
| _______________________ | |
| Column type frequency: | |
| character | 2 |
| numeric | 5 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| 나라 | 0 | 1 | 4 | 25 | 0 | 149 | 0 |
| 지역 | 0 | 1 | 9 | 34 | 0 | 10 | 0 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| 행복 | 0 | 1 | 5.53 | 1.07 | 2.52 | 4.85 | 5.53 | 6.26 | 7.84 | ▁▅▇▇▃ |
| GDP | 0 | 1 | 9.43 | 1.16 | 6.64 | 8.54 | 9.57 | 10.42 | 11.65 | ▂▆▇▇▅ |
| 사회지지 | 0 | 1 | 0.81 | 0.11 | 0.46 | 0.75 | 0.83 | 0.90 | 0.98 | ▁▂▅▇▇ |
| 자율성 | 0 | 1 | 0.79 | 0.11 | 0.38 | 0.72 | 0.80 | 0.88 | 0.97 | ▁▂▅▇▇ |
| 부패지각 | 0 | 1 | 0.73 | 0.18 | 0.08 | 0.67 | 0.78 | 0.84 | 0.94 | ▁▁▁▅▇ |
describe(df)## vars n mean sd median trimmed mad min max range skew
## 나라* 1 149 75.00 43.16 75.00 75.00 54.86 1.00 149.00 148.00 0.00
## 지역* 2 149 6.06 3.15 6.00 6.19 4.45 1.00 10.00 9.00 -0.24
## 행복 3 149 5.53 1.07 5.53 5.54 1.04 2.52 7.84 5.32 -0.10
## GDP 4 149 9.43 1.16 9.57 9.48 1.46 6.64 11.65 5.01 -0.35
## 사회지지 5 149 0.81 0.11 0.83 0.83 0.11 0.46 0.98 0.52 -0.92
## 자율성 6 149 0.79 0.11 0.80 0.80 0.12 0.38 0.97 0.59 -0.74
## 부패지각 7 149 0.73 0.18 0.78 0.76 0.12 0.08 0.94 0.86 -1.55
## kurtosis se
## 나라* -1.22 3.54
## 지역* -1.42 0.26
## 행복 -0.43 0.09
## GDP -0.86 0.09
## 사회지지 0.30 0.01
## 자율성 0.31 0.01
## 부패지각 2.07 0.01149행 7열 데이터프레임이다. 나라와 지역이 문자형이다. 나라는 149개의 고유한 값이 있고, 지역은 10개의 고유한 값이 있다. 즉, 지역은 범주형변수다.
지역별 빈도를 구했다.
df %>%
tabyl(지역) %>%
adorn_totals()## 지역 n percent
## Central and Eastern Europe 17 0.11409396
## Commonwealth of Independent States 12 0.08053691
## East Asia 6 0.04026846
## Latin America and Caribbean 20 0.13422819
## Middle East and North Africa 17 0.11409396
## North America and ANZ 4 0.02684564
## South Asia 7 0.04697987
## Southeast Asia 9 0.06040268
## Sub-Saharan Africa 36 0.24161074
## Western Europe 21 0.14093960
## Total 149 1.0000000010개 지역을 4개 대륙으로 줄이자. 대륙 열을 만들어 지역 열의 값을 해당 대륙의 값으로 바꿔주면 된다. dplyr패키지의 recode()함수를 이용하는 방법과 stringr패키지의 str_replace()함수를 이용하는 방법이 있다.(두 패키지 모두 tidyverse함께 R환경에 탑재된다.)
두 함수 모두 벡터를 처리하므로, 데이터프레임은 mutate()함수와 함께 사용한다.
df %>% mutate(new_col = recode(old_col, 바꿀대상 = 바꾼결과)
df %>%
mutate.(대륙 = recode(
지역,
`Western Europe` = "유럽",
`North America and ANZ` = "아메리카",
`Middle East and North Africa` = "아프리카",
`Latin America and Caribbean` = "아메리카",
`Central and Eastern Europe` = "유럽",
`East Asia` = "아시아",
`Southeast Asia` = "아시아",
`Commonwealth of Independent States` = "유럽",
`Sub-Saharan Africa` = "아프리카",
`South Asia` = "아시아")) -> df
tabyl(df, 대륙) ## 대륙 n percent
## 아메리카 24 0.1610738
## 아시아 22 0.1476510
## 아프리카 53 0.3557047
## 유럽 50 0.3355705df %>% mutate(new_col = str_replace(old_col, pattern, replacement)
패턴을 찾아 해당 패턴이 들어있는 문자열을 교체한다. 정규표현식으로 복잡한 패턴을 만들어 보다 정교하게 사용할 수 있다.
정규표현식에서 |은 또는. .은 문자, 기호, 숫자 등 임의의 값 하나. *은 선행요소가 0회 또는 그 이상(zero or more) 반복. .*은 문자, 기호, 숫자 등 임의 값이 0회 혹은 1회 반복되는 패턴을 지정하는 정규표현식이 된다.
df %>%
mutate.(대륙 = str_replace(지역, ".*Euro.*|.*Comm.*", "유럽")) %>%
mutate.(대륙 = str_replace(대륙, ".*Amer.*", "아메리카")) %>%
mutate.(대륙 = str_replace(대륙, ".*Afri.*", "아프리카")) %>%
mutate.(대륙 = str_replace(대륙, ".*Asia.*", "아시아")) -> df
tabyl(df, 대륙) ## 대륙 n percent
## 아메리카 24 0.1610738
## 아시아 22 0.1476510
## 아프리카 53 0.3557047
## 유럽 50 0.3355705행복, GDP, 사회지지, 자율성, 부패지각이 연속변수다. 모든 변수에 결측값은 없다. 각 변수별로 평균과 표준편차를 표로 정리했다.
df %>%
describe() %>%
rownames_to_column(var = "V") %>% # 열이름을 열로 변경
select.(V, mean, sd) %>%
gt() %>%
tab_header(str_glue("변수별 평균과 표준편차(n = {nrow(df)})")) %>% # nrow()는 행의 개수
fmt_number(mean:sd, decimals = 2)| 변수별 평균과 표준편차(n = 149) | ||
|---|---|---|
| V | mean | sd |
| 나라* | 75.00 | 43.16 |
| 지역* | 6.06 | 3.15 |
| 행복 | 5.53 | 1.07 |
| GDP | 9.43 | 1.16 |
| 사회지지 | 0.81 | 0.11 |
| 자율성 | 0.79 | 0.11 |
| 부패지각 | 0.73 | 0.18 |
| 대륙* | 2.87 | 1.06 |
범주형 변수를 제외하고 표를 만들어보자. V열에 범주형 변수는 *표시가 있으므로, 정규표현식으로 *표시가 있는 값만 걸러내면 된다. *은 기능문자이기 때문에, 이스케이프 문자 \와 함께 사용해야 기능문자가 아니라 일반문자로 처리하게 된다.
df %>%
describe() %>%
rownames_to_column(var = "V") %>%
filter(!str_detect(V, "\\*")) %>% # *이 포함안된 행 필터
select.(V, mean, sd) %>%
gt() %>%
tab_header(str_glue("변수별 평균과 표준편차(n = {nrow(df)})")) %>% # nrow()는 행의 개수
fmt_number(mean:sd, decimals = 2)| 변수별 평균과 표준편차(n = 149) | ||
|---|---|---|
| V | mean | sd |
| 행복 | 5.53 | 1.07 |
| GDP | 9.43 | 1.16 |
| 사회지지 | 0.81 | 0.11 |
| 자율성 | 0.79 | 0.11 |
| 부패지각 | 0.73 | 0.18 |
3.3.3 시각화
상관도표로 상관관계를 훑어봤다.
df %>% select.(-c(나라, 지역)) %>% ggpairs()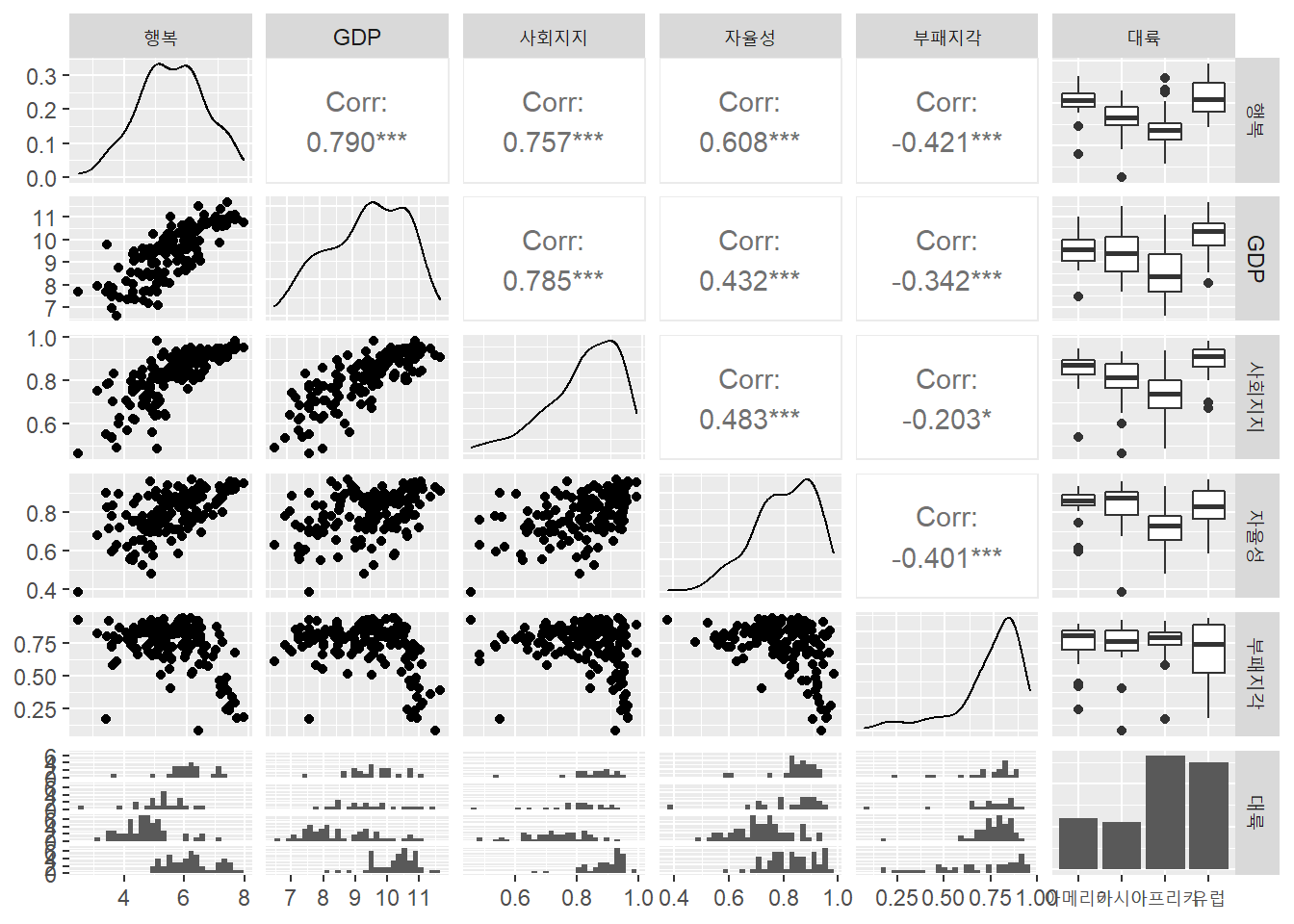
각 나라의 행복수준은 GDP, 사회지지, 자율성과 양상관이 있었고, 부패지각과 음상관이 있다. 분포를 보면, 행복과 GDP는 대체로 좌우 대칭의 정규분포의 모양을 하고 있다. 사회지지, 자율성, 부패지각은 오른쪽으로 다소 치우친 모양이다.
GDP와 행복이 양상관이 있는데, 이를 빈국과 부국으로 구분해 시각화 했다. 이를 위해 먼저 경제력 변수를 범주형으로 추가했다.
df %>%
mutate(경제력 = ifelse(GDP > mean(GDP), "부국", "빈국")) %>%
ggplot(aes(factor(경제력), 행복)) +
geom_boxplot() +
geom_sina(alpha = .4) +
labs(title = "부국과 빈국의 행복 수준",
x = "경제력") +
theme(title = element_text(size = 15))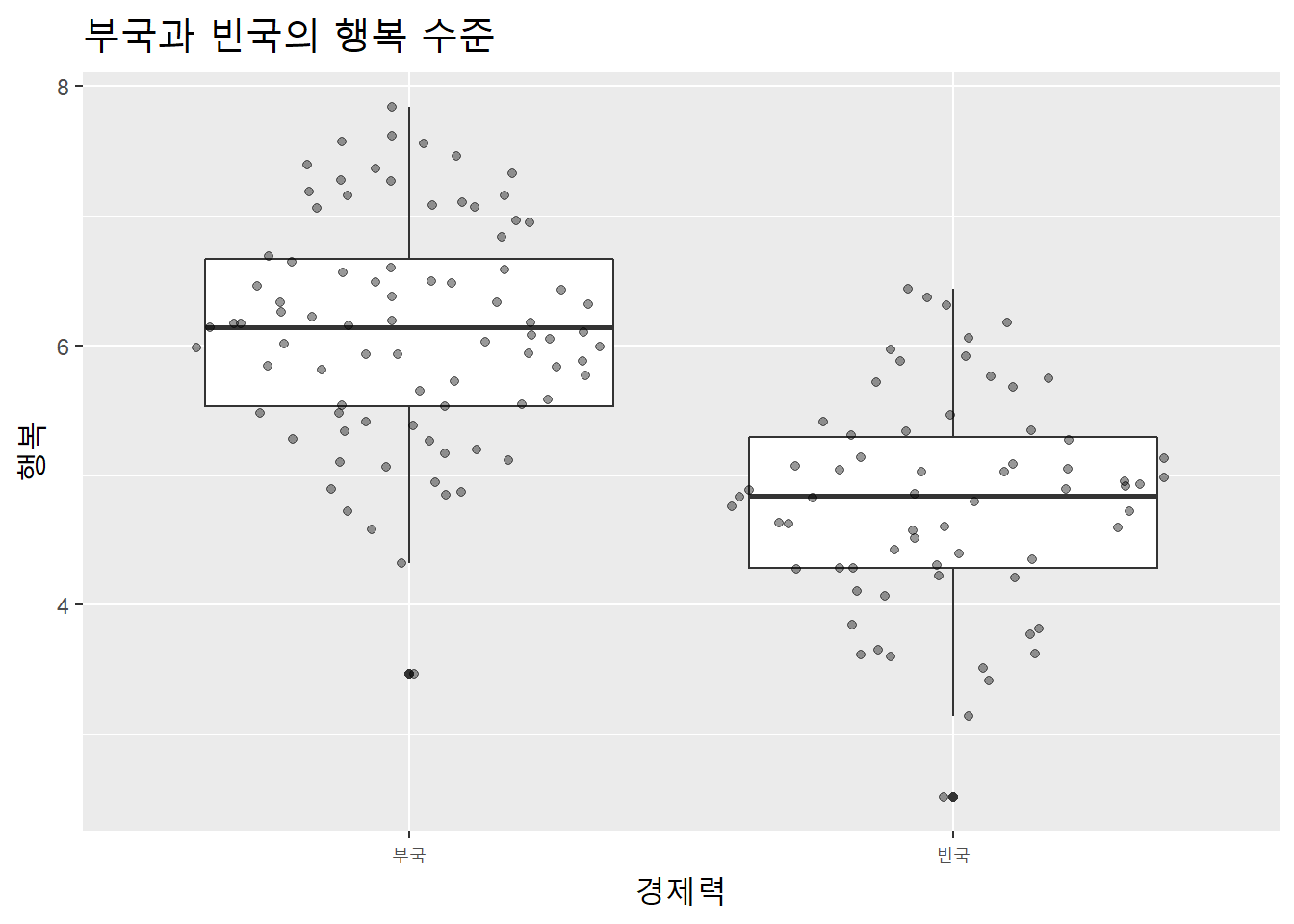
대체로 부국일수록 행복도가 높았다. 경제력이 평균 이상임에도 행복수준이 낮은 이상치가 있다. 어느 나라인지 확인해보자.
ifelse(test, yes, no):test =인자의 논리값이TRUE면 yes자리에,FALSE면 no자리에 원하는 값을 투입한다.
df %>%
mutate(경제력 = ifelse(GDP > mean(GDP), "부국", "빈국")) %>%
ggplot(aes(factor(경제력), 행복)) +
geom_boxplot() +
geom_sina(alpha = .4) +
geom_text(aes(label = 나라), position = "jitter") +
labs(title = "부국과 빈국의 행복 수준",
x = "경제력") +
theme(title = element_text(size = 15))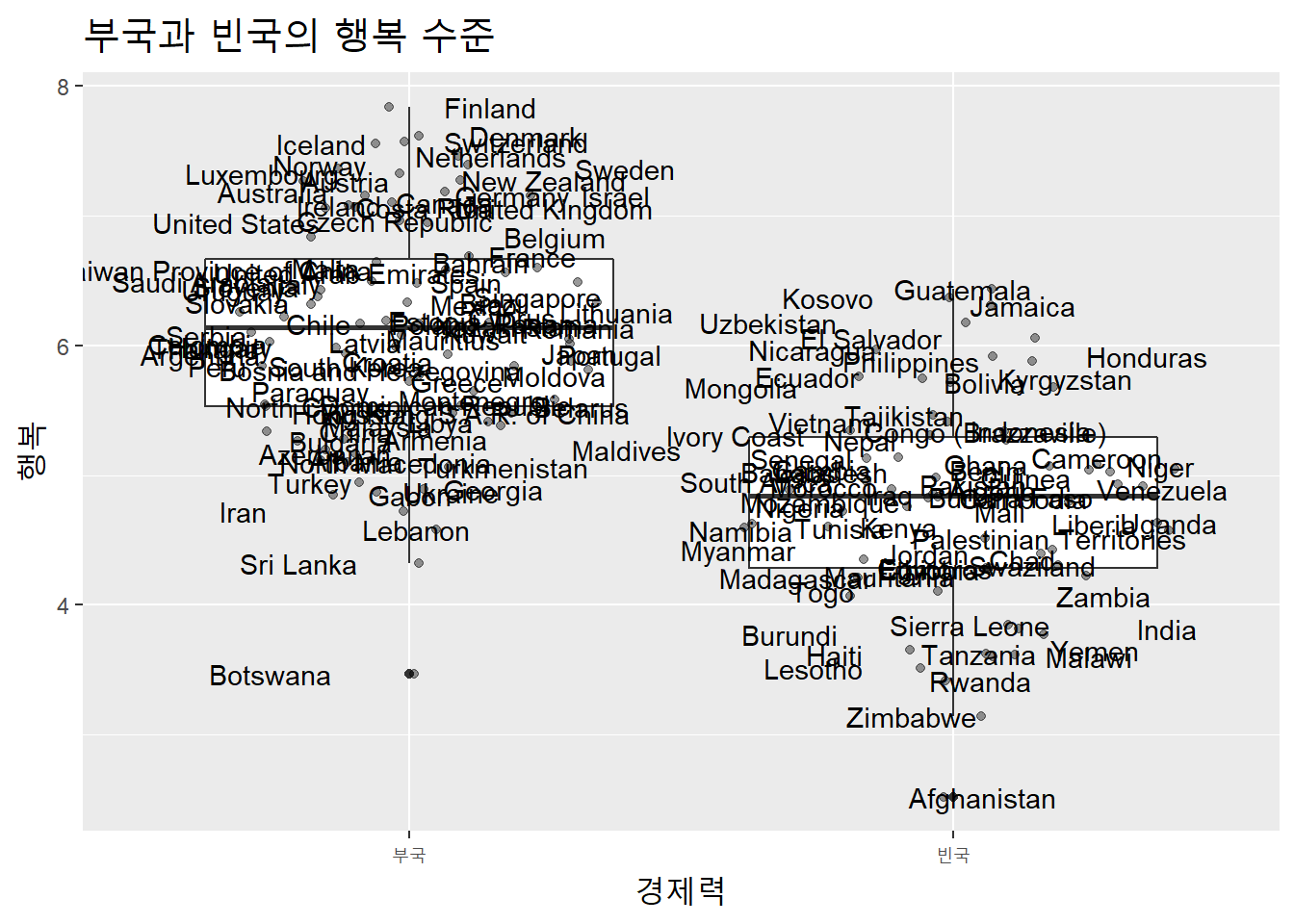
중복을 허용해 일부라도 나라 이름을 볼수 있도록 하자.
df %>%
mutate(경제력 = ifelse(GDP > mean(GDP), "부국", "빈국")) %>%
ggplot(aes(factor(경제력), 행복)) +
geom_boxplot() +
geom_sina(alpha = .4) +
geom_text(aes(label = 나라), position = "jitter",
check_overlap = T) + # 중복허용
labs(title = "부국과 빈국의 행복 수준",
x = "경제력") +
theme(title = element_text(size = 15))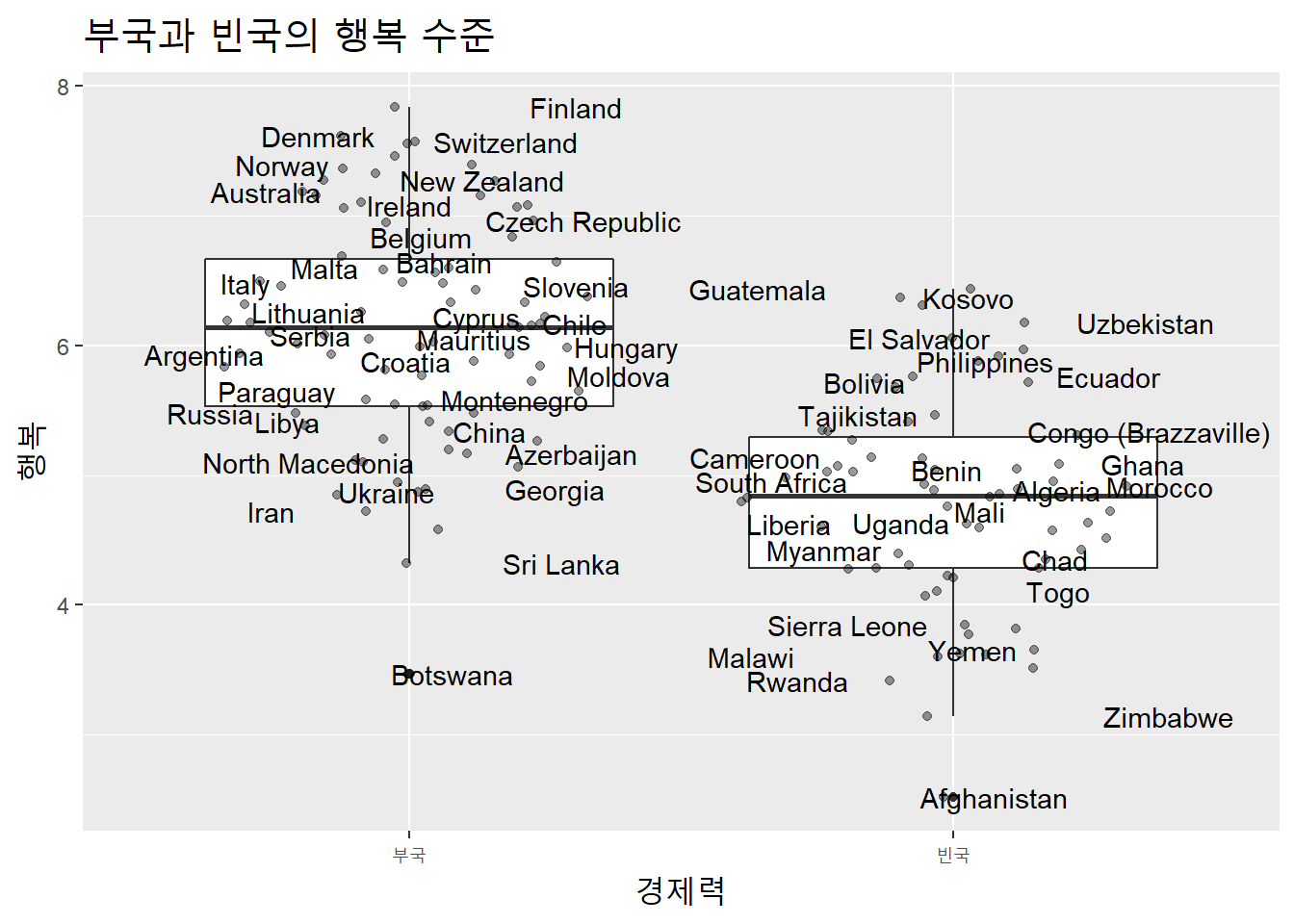
GDP와 행복의 관계를 산점도로 표시해보자.
df %>%
ggplot(aes(GDP, 행복)) +
geom_point() +
labs(title = "GDP와 행복의 관계") +
theme(title = element_text(size = 15))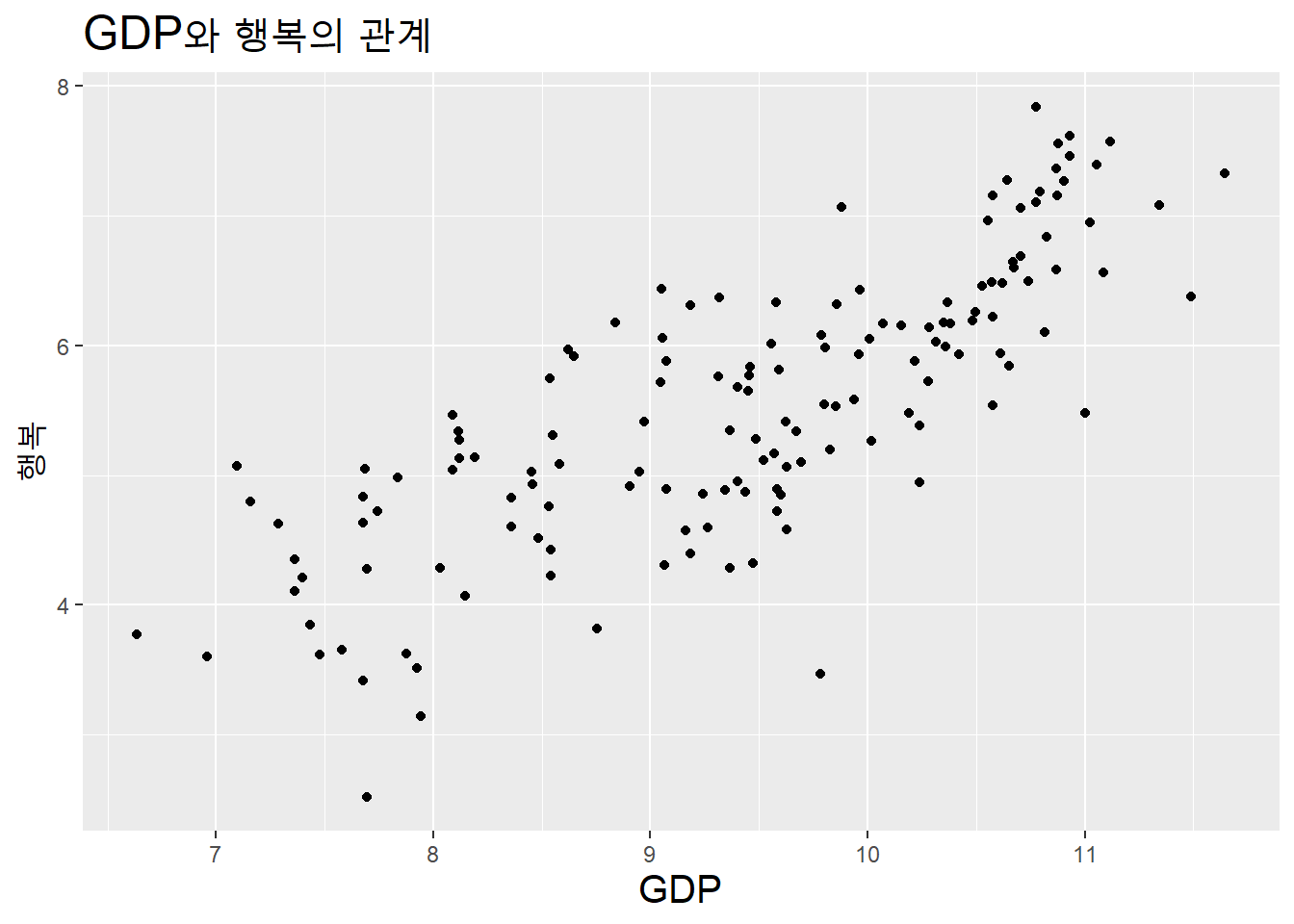
GDP와 행복의 관계를 대륙별로 구분해 표시해보자.
df %>%
ggplot(aes(GDP, 행복, color = 대륙)) +
geom_point() +
labs(title = "대륙별 GDP와 행복의 관계") +
theme(title = element_text(size = 15))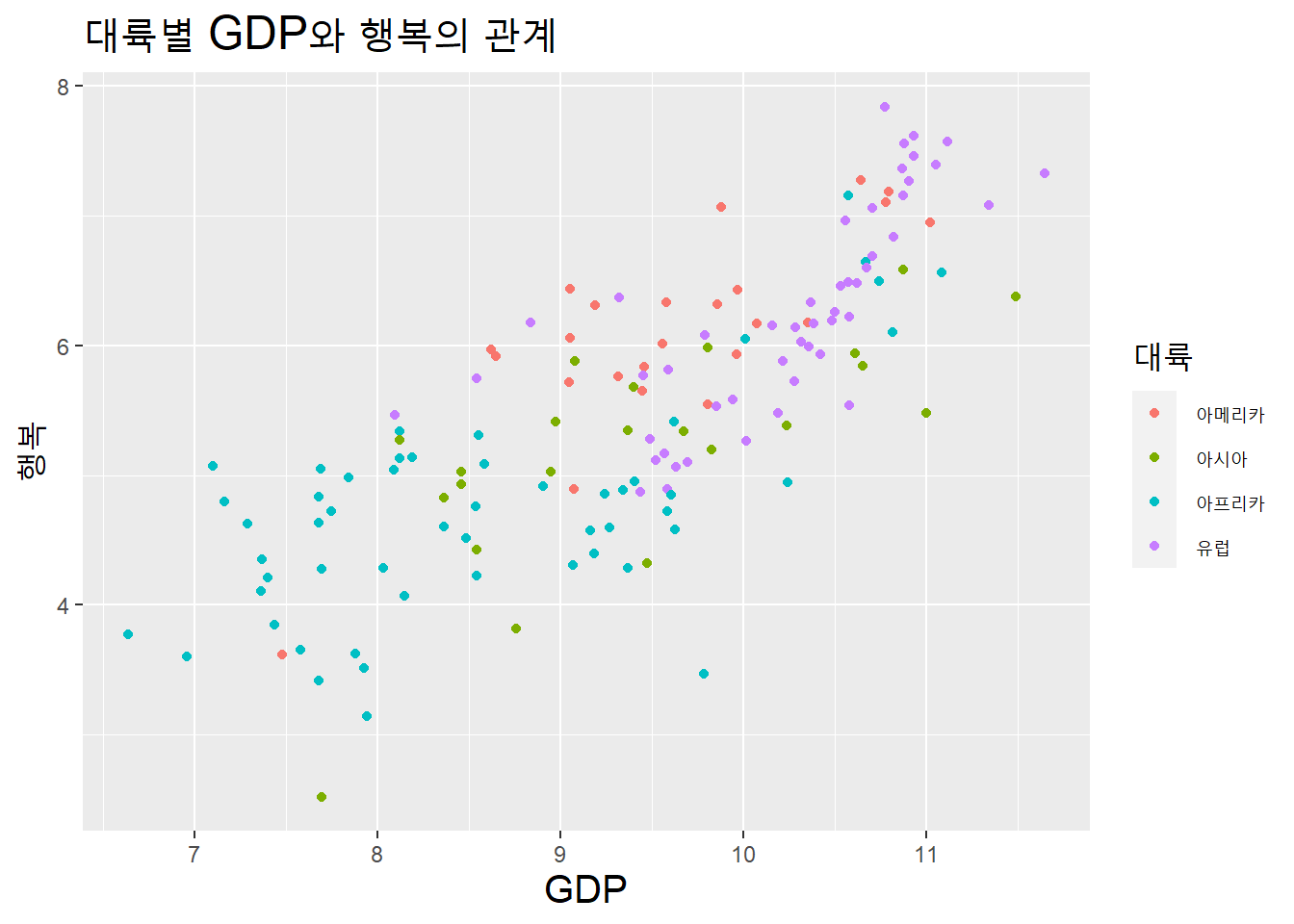
대륙별 색 구분이 명확하지 않다. colorbrewer색상표를 이용하자. 색상표와 팔레트이름은 다음과 같다. colorbrewer2에서 색상표를 선택한다. 대륙의 속성은 질적으로 구분되므로 qualitative를 선택하고, 속성이 4개이므로 data class의 수를 4개로 지정한다. 팔레트의 이름은 ’Paired’다.
Colorbrewer2사이트에서 팔레트의 이름은 화면 왼쪽 중간에 있다 (Figure 3.1).
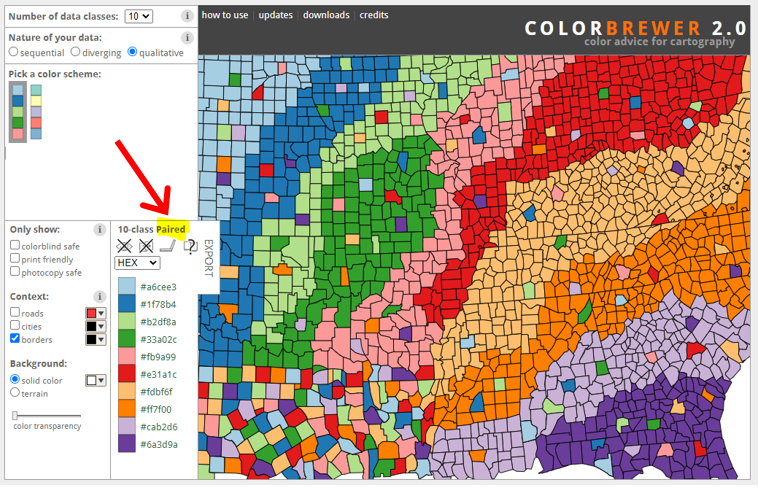
Figure 3.1: ColorBrewer 색상표
df %>%
ggplot(aes(GDP, 행복, color = 대륙)) +
geom_point() +
scale_color_brewer(palette = "Paired") +
labs(title = "대륙별 GDP와 행복의 관계") +
theme(title = element_text(size = 15))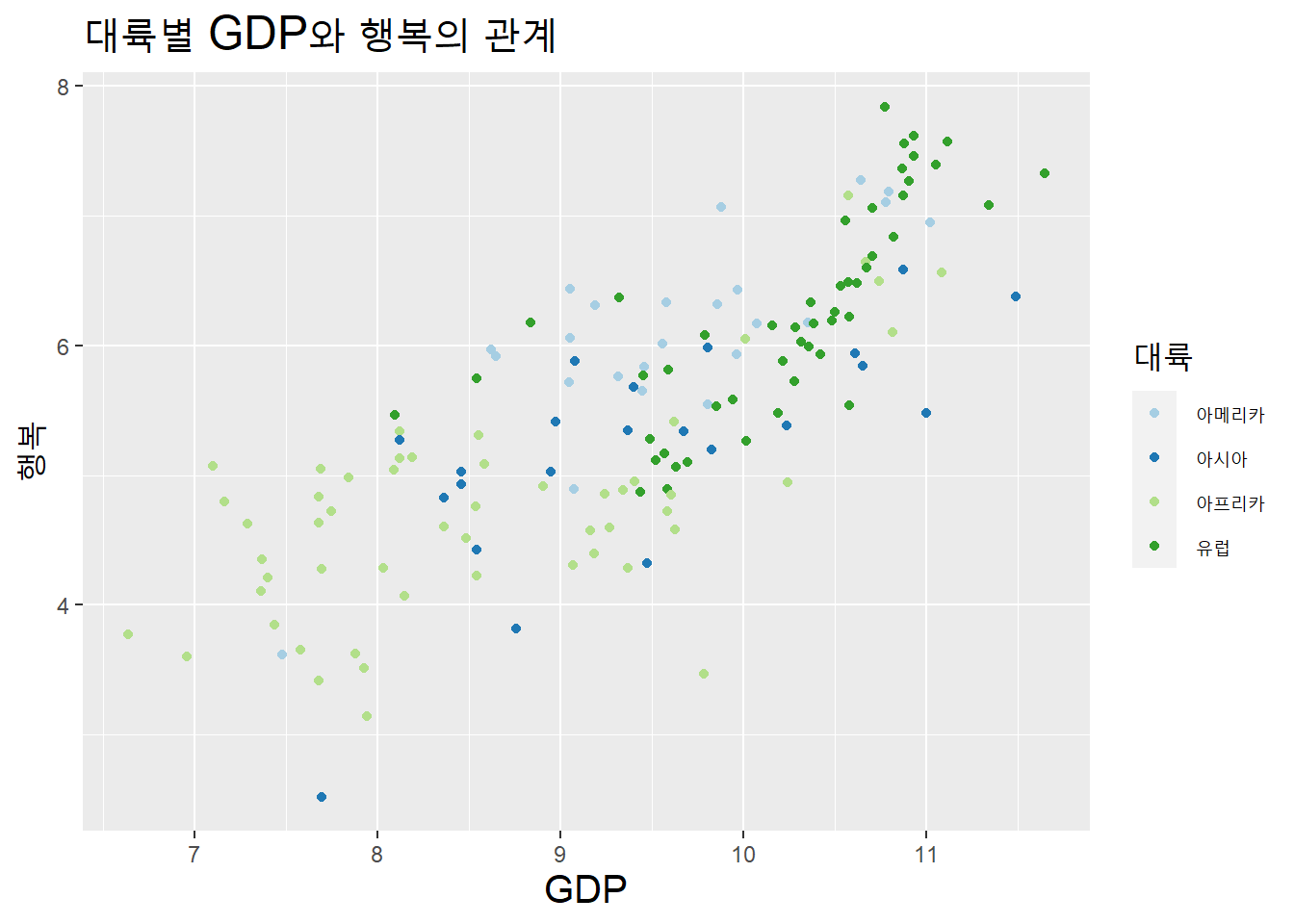
색상표를 Set1으로 바꿔보자.
df %>%
ggplot(aes(GDP, 행복, color = 대륙)) +
geom_point() +
scale_color_brewer(palette = "Set1") +
labs(title = "대륙별 GDP와 행복의 관계") +
theme(title = element_text(size = 15))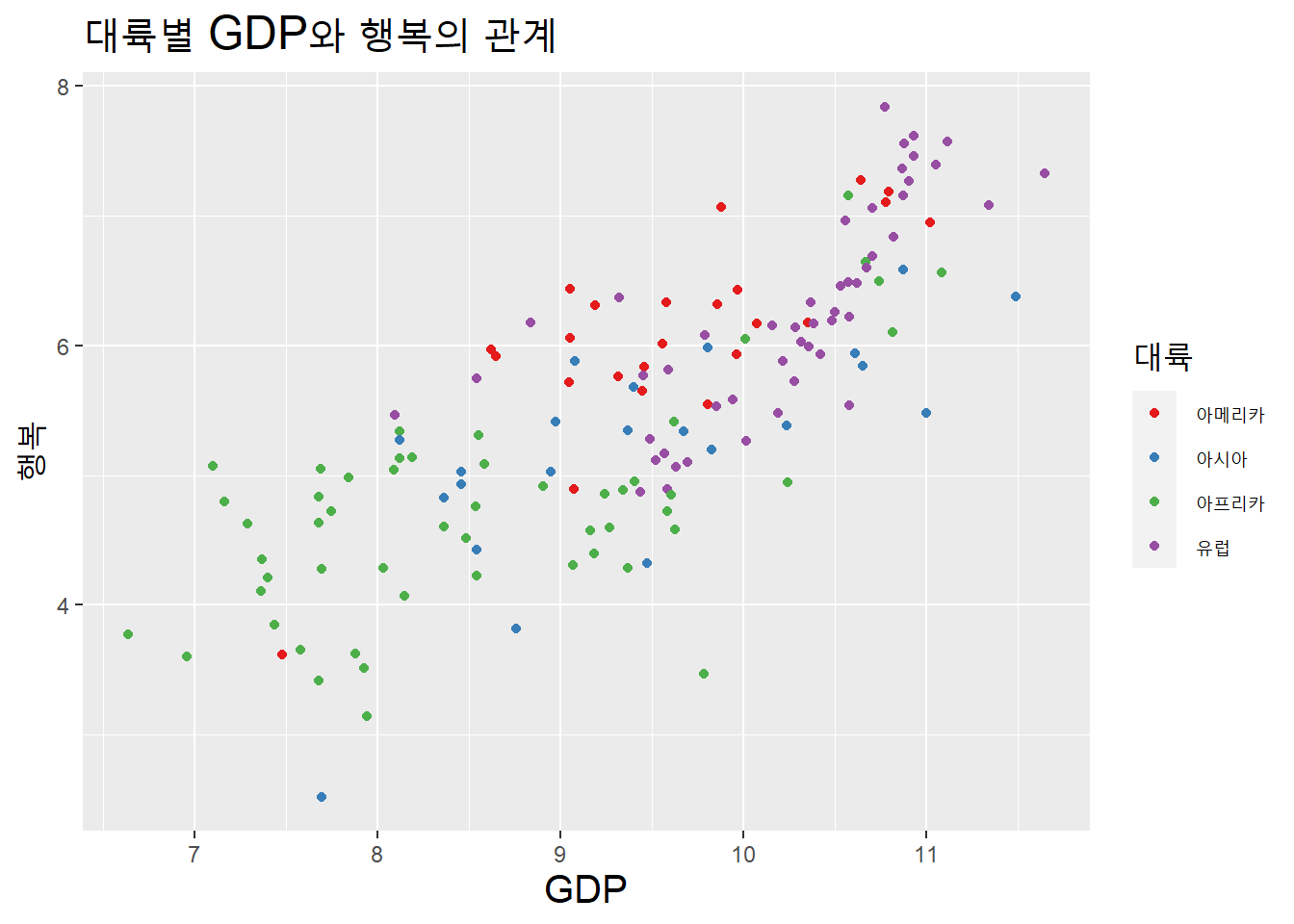
대륙별 부패지각과 행복과의 관계를 살펴보자.
df %>%
ggplot(aes(부패지각, 행복, color = 대륙)) +
geom_point() +
scale_color_brewer(palette = "Set1") +
labs(title = "대륙별 부패지각과 행복의 관계") +
theme(title = element_text(size = 15))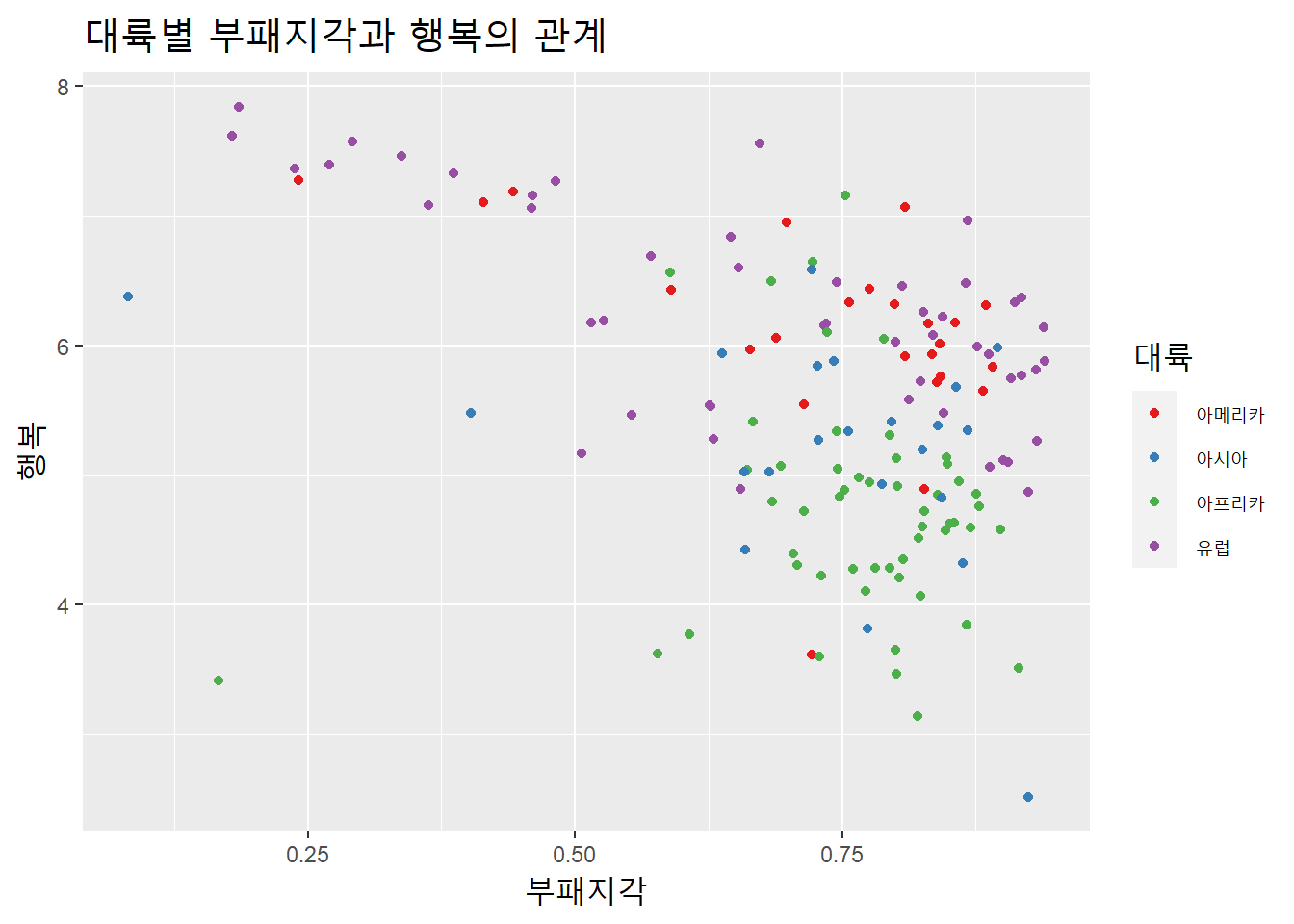
부패지각과 행복은 음상관이나, 대체로 유럽과 아메리카 대륙 나라들은 부패지각이 높아도 행복수준이 낮지는 않다.
대륙별 부패지각과 행복과의 관계에 GDP를 추가해서 살펴보자. 추가하는 변수는 크기로 나타낼수 있다.
df %>%
ggplot(aes(부패지각, 행복, color = 대륙)) +
geom_point(aes(size = GDP)) +
scale_color_brewer(palette = "Set1") +
labs(title = "대륙별 GDP 및 부패지각과 행복의 관계") +
theme(title = element_text(size = 15))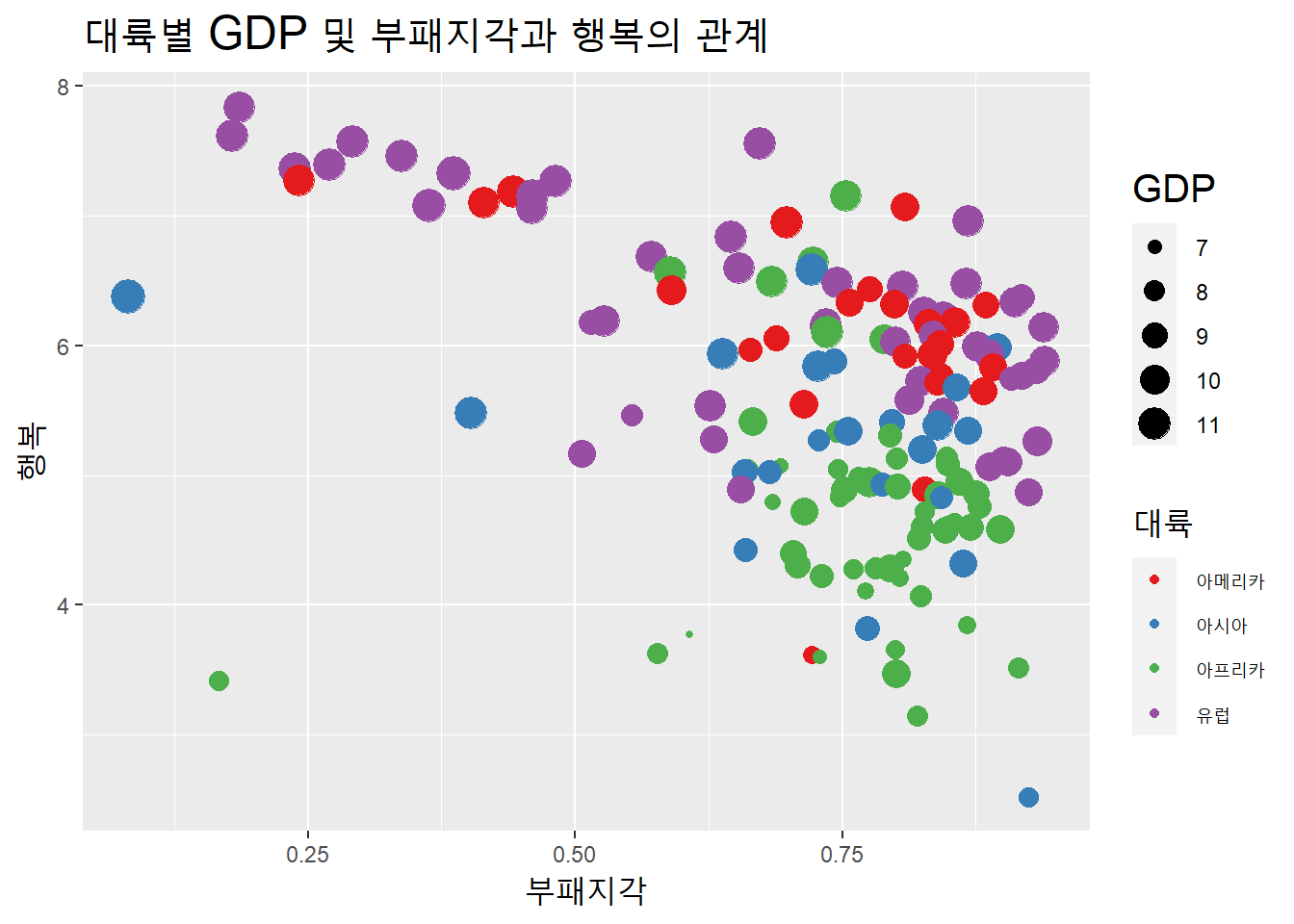
나라 이름을 표시해보자.
df %>%
ggplot(aes(부패지각, 행복, color = 대륙)) +
geom_point(aes(size = GDP)) +
geom_text(aes(label = 나라)) +
scale_color_brewer(palette = "Set1") +
labs(title = "대륙별 GDP 및 부패지각과 행복의 관계") +
theme(title = element_text(size = 15),
legend.position = "none") # 범례 표시 제거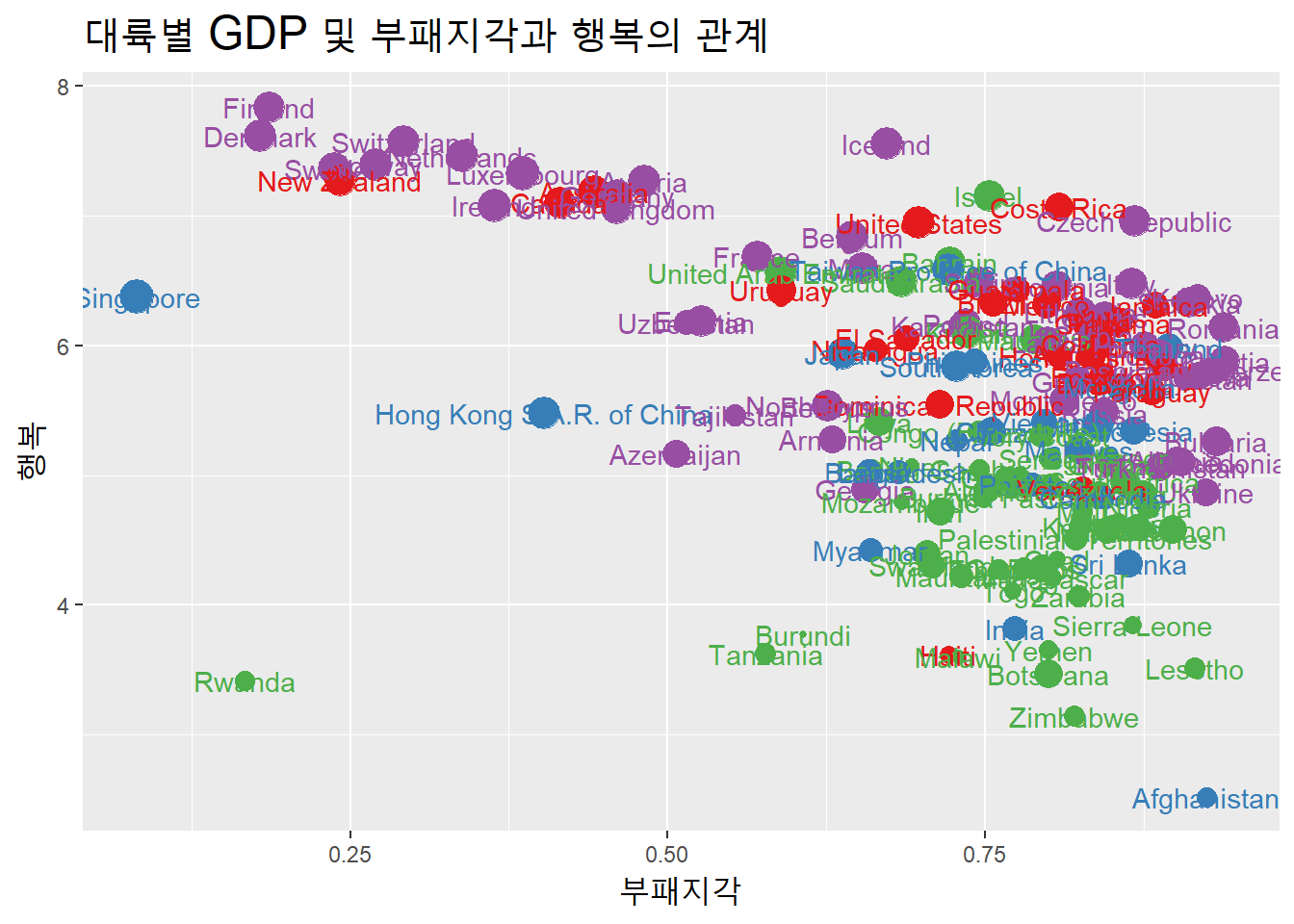
3.4 유용
위 코드는 여러 패키지를 한번에 설치하고 탑재하는 코드다. 이 코드에 대해 하나씩 살펴보자.
3.4.1 여러 패키지 한번에 탑재
여러 패키지를 설치하는 가장 간단한 방법은 다음과 같이 install.packages()함수를 두번 입력한다. (자료 가져오기에 이용하는 rio패키지와 tidyverse패키지를 한번에 설치는 상황을 설정해보자.)
install.packages("rio")
install.packages("tidyverse")만일 패키지 10개를 설치한다면 같은 문자를 10번 반복해야 한다. 코딩을 하는 이유는 반복적인 작업을 하지 않기 위해서다. 아래와 같이 설치할 패키지를 벡터(여기서는 pkg)에 지정해 install.packages(pkg)를 실행하면 한번에 패키지를 설치할 수 있다.
c("rio", "tidyverse") -> pkg
install.packages(pkg)R에서는 객체를 할당할 때 ->를 이용하면 객체를 오른쪽에 놓을 수 있다. 파이핑 코드처럼 사고의 흐름과 일치하는 장점이 있다.
그런데, 이 방법은 단점이 있다. 이미 설치된 패키지를 반복해서 설치하도록 하기 때문이다. 아래 코드는 설치돼 있는 패키지는 설치를 피하고, 새로운 패키지만 골라서 동시에 설치한다.
c("rio", "tidyverse") -> pkg
pkg %in% installed.packages()[,"Package"] -> pkg_installed
pkg[!pkg_installed] -> pkg_new
if(length(pkg_new)) install.packages(pkg_new)코드의 의미를 하나씩 살펴보자.
- 컴퓨터에 설치할 패키지 목록
c("rio", "tidyverse") -> pkg - 컴퓨터에 이미 설치된 패키지 목록
pkg %in% installed.packages()[,"Package"] -> pkg_installed installed.packages()함수는 “installed”라는 과거형 동사가 의미하듯, 이미 설치된 패키지의 목록을 보여준다. 자료구조는 매트릭스다. 설치된 패키지 목록은 “Package”이름의 열에 있다. 따라서 installed.packages()[, "Package"]로 부분선택하면 설치된 패키지목록을 벡터로 구할 수 있다.
%in%함수는 “~이 포함된(is_in)”이란 의미의 연산자이다. TRUE FALSE논리값을 산출한다.
fruits_v <- c("Apple", "Banana", "Orange")
"Apple" %in% fruits_v## [1] TRUEf1_v <- c("Apple", "Grape")
f2_v <- c("Apple", "Banana", "Orange")
f1_v %in% f2_v## [1] TRUE FALSE논리값을 산출하므로 조건문에 이용할 수 있다.
target_v <- "Apple"
fruit_v <- c("Apple", "Banana", "Orange")
if(target_v %in% fruit_v) {
print("Eat!")
} else {
print("Do not Eat!")
}## [1] "Eat!"target_v <- "Stone"
fruit_v <- c("Apple", "Banana", "Orange")
if(target_v %in% fruit_v) {
print("Eat!")
} else {
print("Do not Eat!")
}## [1] "Do not Eat!"- 설치되지 않은 패키지 목록
pkg[!pkg_installed] -> pkg_new설치된 패키지 목록을 벡터로 저장했으므로, 부정 연산자인 !를 이용하면 설치되지 않은 패키지만 부분선택해 벡터로 저장할 수 있다.
객체에 할당한 다음에도 기술문 앞뒤로 ( )로 묶어주면 산출 결과를 화면에 표시한다. 이렇게 하면 새로 설치할 패키지가 무엇인지 알수 있다.
(pkg[!pkg_installed] -> pkg_new)- 설치되지 않은 패키지만 선택적으로 설치
if(length(pkg_new)) install.packages(pkg_new)length()함수는 객체에 포함된 값의 갯수를 계산하는 함수다. pkg_new객체에 값이 하나도 없으면(즉, 설치되지 않는 패키지가 없으면) 0이 산출되고, pkg_new객체에 값이 하나라고 있으면(즉, 설치되지 않은 패키지가 하나라고 있으면) 1이상이 산출된다.
if() 조건문에서 0은 FALSE다.
따라서, pkg_new객체에 새로 설치할 패키지가 하나도 없는 경우. if(length(pkg_new))조건문은 FALSE를 산출해 install.packages(pkg_new)를 실행하지 않는다.
반면, pkg_new객체에 새로 설치할 패키지가 하나라도 있는 경우. if(length(pkg_new))조건문은 TRUE를 산출해 install.packages(pkg_new)를 실행한다.
위의 코드를 종합하면 다음과 같다.
# 설치할 패키지 목록
c("rio", "tidyverse") -> pkg
# 컴퓨터에 설치된 패키지 목록
pkg %in% installed.packages()[,"Package"] -> pkg_installed
# 설치되지 않은 패키지 보기.
(pkg[!pkg_installed] -> pkg_new)
# 설치되지 않은 패키지만 선택적으로 설치
if(length(pkg_new)) install.packages(pkg_new)3.4.2 여러 패키지 한번에 탑재
설치한 여러 패키지를 R환경에 탑재하려면 다음과 같이 library()함수를 반복해서 입력해야 한다.
library(rio)
library(tidyverse)그런데 이는 좋은 방법이 아니다. library()함수를 반복해서 입력하기 때문이다. sapply()함수를 이용하면, 다른 함수를 반복해서 투입해 반복(iteration)작업을 하도록 코딩할 수 있다.
apply(), lapply(), sapply()처럼 함수가 다른 함수를 실행대상으로 설정하는 작업을 함수형프로그래밍(functional programming)이라고 한다. sapply()의 용법은 다음과 같다.
sapply(X, FUN, ...)
- X : 함수로 실행할 벡터 또는 리스트.
- FUN : 투입한 X인자의 각 요소에 대해 실행할 함수.
- … : 투입한 FUN인자에 사용할 인자.
아래 코드는 탑재할 패키지 목록을 pkg에 저장한 다음, 이 목록에 있는 패키지(“rio,” “tidyverse”)에 대해 sapply()로 library()함수를 character.only = TRUE 인자를 투입해 반복해서 실행하라는 의미다. character.only = TRUE는 library()함수에 투입하는 대상이 문자형으로 투입됐음을 알려주는 역할을 한다. character.only = TRUE는 ch = T로 줄여써도 된다.
c("rio", "tidyverse") -> pkg
sapply(X = pkg, FUN = library, character.only = TRUE)즉, 위의 코드는 다음 두줄의 코드를 실행하도록 한줄로 구현한 것이다. (탑재할 패키지가 10개라면!)
library("rio", character.only = TRUE)
library("tidyverse", character.only = TRUE)sapply()함수는 실행결과를 매트릭스 형식으로 산출한다. 실행결과에 탑재하려는 패키지 뿐 아니라 이미 탑재된 패키지 목록도 보여준다.
c("rio", "tidyverse") -> pkg
sapply(pkg, library, ch = TRUE)함수형프로그래밍을 이용한 반복작업은 많이 사용하는 유용한 방법이므로 사용법을 숙지하도록 하자.
tidyverse와 함께 설치되는 purrr패키지의 map_*계열 함수는 보다 일관되고 체계적인 함수형 프로그래밍을 제공한다. R4DS의 반복 부분 및 사용설명서 요약설명서 참조
3.5 종합
3.5.1 통계
1 기술통계
- 빈도
- 교차표
- 중심경향치
- 평균 mean
- 중간값 median
- 사분위값 qunatile
- 최빈값 mode
- 분산성
- 범위 range
- 분산 var
- 표준편차 sd
- 사분위 IQR
- 상관분석
- 관계
- 독립성(independence)
- 연관성(association/dependence)
- 상관성(correlation)
- 인과성(correlation)
- 상관관계도(correlogram/correlation matrix)
3.5.2 코딩
- 기술통계
- dim()
- str()
- skim()
- describe()
- describeBy()
- table()
- janitor
- tabyl()
- adorn_totals()
- tabyl()
- dplyr / tidytable
- summarise.()
- summarise.()
- mean()
- median()
- quantile()
- min()
- max()
- var()
- sd()
- IQR()
- .by =
- 표
- gt
- gt()
- tab_header()
- fmt_number()
- gt()
- 시각화
- ggplot2
- geom_boxplot()
- geom_violin()
- geom_dotplot()
- geom_point()
- geom_smooth()
- geom_text
- ggforce
- geom_sina()
- geom_sina()
- GGally
- ggpairs()
- ggpairs()
- mdthemes
- md_theme_gray()
- md_theme_gray()
- 연산자
- %in%
- 자료변형
- rownames_to_column()
- dplyr / tidytable
- mutate(new_col = recode(old_col, new = old))
- mutate(new_col = str_replace(old_col, pattern, replacement))
- mutate(new_col = recode(old_col, new = old))
- tidyr
- pivot_longer()
- pivot_wider()
- pivot_longer()
- ifelse(test, yes, no)
- 문자다루기
- tidyverse/stringr
- str_glue()