1 기본 다지기
1.1 틀 잡기
1.1.1 실재와 인식
우리가 알고 있는 세상은 세상 그 자체가 아니라 우리 마음 속에 비친 그림자다. 아래 사진을 보자. 그림자예술가 Triantafyllos Vaitsis의 "시작의 끝과 끝의 시작(The beginning of the end and the end of the beginning)이다.

The Beginning of the End and the End of the Beginning by Triantafyllos Vaitsis
조형물은 하나이나, 빛을 비추는 방향에 따라 그림자는 전혀 다른 모습이다. 왼쪽에서 오른쪽으로 비춘 그림자는 아기형상이고, 오른쪽에서 왼쪽으로 비춘 그림자는 노인의 모습이다. 조형물은 실재로서의 세상이고, 그림자는 우리가 알고 있는 그림자로서의 세상이다.
실재에 대한 이해의 과정은 위계적 구조를 지니고 있다. 이를 DIKW(Data-Information-Knowledge-Wisdom)위계라고 한다 (Rowley 2007). 인간의 두뇌는 바깥세상을 있는 그대로 기록해 저장하지 않는다. 감지(sensing), 지각(perception) 및 인지(cognition) 등의 과정을 거쳐 해석하고 구성한다 (안도현 2021). 이 과정을 도식화하면 다음과 같다.
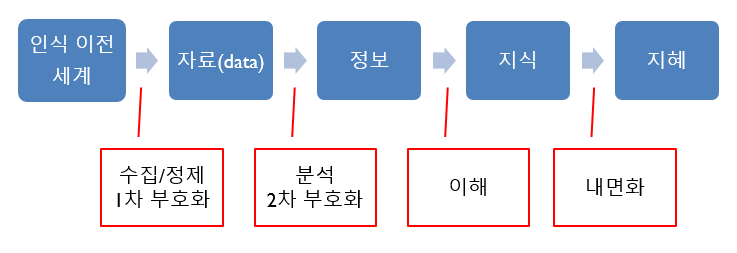
Figure 1.1: DIKW 위계도
1. 인식 이전 세계
사물 영역과 사회 영역에서 나타나는 다양한 자연현상과 사회현상이 실재로서 존재한다. 태양은 매일 뜨고 지며, 사람들은 행동한다. 건물 동영상 컴퓨터 등 사물이 만들어지고 협력, 배신, 평판 등 다양한 상황이 생성된다.
Figure 1.2: DIKW 실재
2. 수집 단계
인식 이전 세계(사물, 사람, 상황 등의 실재)를 인식하기 위해서는 실재에 대한 신호(signal)를 수집해야 한다. 통상적으로는 눈, 귀, 피부 등의 감각기관을 통해 신호를 감지(sense)함으로써 신호를 수집한다. 체계적으로는 설문, 실험, 내용분석 등의 방법을 이용한다. 체계적인 수집을 측정(measurement)이라고 한다.
신호를 감지하거나 측정하는 것은 우리의 뇌가 신호를 처리할 수 있도록 부호화(encoding)하는 것이다. 이렇게 부호화돼 기록된 신호가 자료(data)다. 갓 수집한 자료는 날 것으로서 그대로 이용할 수 없기에 원자료(raw data)라고 한다. 비유하자면, 땅 속의 석유(petroleum)가 인식 이전의 세계라면, 캐낸(수집한) 원유(crude oil)가 원자료(raw data)에 해당한다.
Figure 1.3: DIKW 수집
3. 정제 단계
원유는 여러 불순물을 제거하는 정제해야 휘발유나 경유 등과 같은 석유제품으로 사용할 수 있듯, 원자료도 정제(cleaning) 과정을 거쳐야 사용할 수 있다. 본격적인 분석에 앞서 미리 처리한다고 해서 전처리작업이라고도 한다. 이렇게 신호를 수집하고 정제하는 단계가 1차 부호화 단계다.
Figure 1.4: DIKW 정제
4. 자료(data) 구성
신호를 수집하고 정제하는 1차 부호화 과정을 거치면 자료(data)가 구성된다. 자료는 추상적인 개념이고, 구체적으로 다루는 대상은 데이터셋(data set)이다.
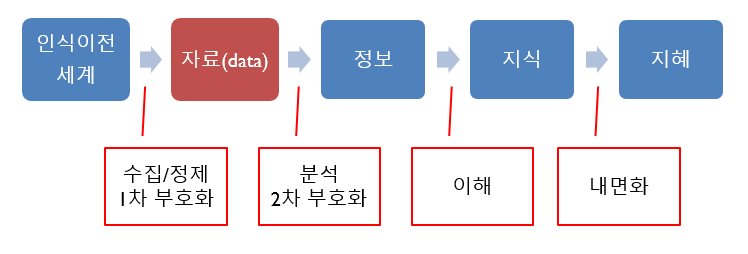
Figure 1.5: DIKW 인식1:자료(data)
5. 분석 단계
정제과정을 거친 석유제품을 가공해 상품화하듯, 정제과정을 거친 자료는 분석과정을 거친다. 분석은 이해할 수 있도록 자료를 식별하고, 조직하고, 해석하는 과정이다. 1차 부호화 다음 단계이므로 2차 부호화 단계다.
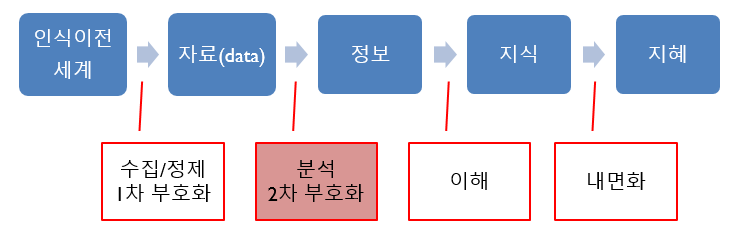
Figure 1.6: DIKW 분석
6. 정보 구성
분석과정을 거치면 정보(information)가 생성된다. 이 정보를 이해하면 지식이 되고, 지식을 내면화함으로써 지혜가 된다. 데이터분석 과정은 자료를 수집하고 정제한 다음 분석함으로써 정보를 구성하는 작업이라고 요약할 수 있다.
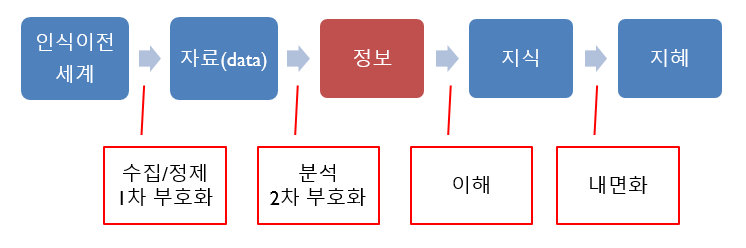
Figure 1.7: DIKW 인식2:정보
인식의 과정을 데이터분석의 틀로 재구성하면 아래와 같다 (Figure 1.8).
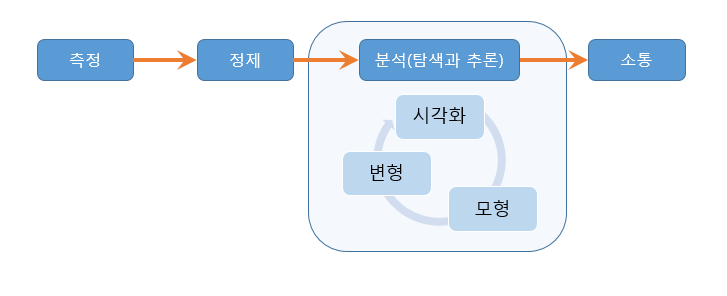
Figure 1.8: 자료(data)분석의 절차
1. 측정
신호의 수집에 해당한다. 관찰, 설문, 실험, 내용분석 등의 방법으로 자료를 수집하거나 가상으로 자료를 생성하는 작업이다. 측정단계의 자료를 원자료(raw data)라고 한다.
2. 정제(전처리)
원자료를 자료를 R환경(작업공간) 안으로 탑재해 분석할 수 있도록 가공하는 단계다. 결측값을 처리하거나 데이터구조를 바꾸는 등의 과정를 거친다.
3. 분석(탐색과 추론)
정체한 자료의 내용에 대해 다양한 방법으로 탐색하고 의미를 추론하는 단계다. 탐색적으로 자료를 변형하고, 시각화하고, 모형을 만드는 과정을 반복한 다음, 최종적인 모형을 구성해 자료의 의미를 추론한다. 추론과정을 완료함으로써 자료가 정보로 가공된다.
- 변형(transform)
- 시각화(visualise)
- 모형(model)
4. 소통(communication) 분석 결과를 자신 및 다른 사람들이 이해할 수 있게 만들어 소통함으로서 데이터분석의 절차가 마무리된다. 정보를 소통한다는 것은 발신자와 수신자가 의미를 공유하는 것이다. 소통되는 정보를 메시지라고 한다.
1.2 R시작하기
기초 지식
컴퓨터
컴퓨터는 범용계산기계다. ’범용’이란 수행할 수 있는 과제가 특정 영역에 국한되지 않는다는 의미다. 즉, 컴퓨터는 인간처럼 모든 영역의 과제를 수행할 수 있다. 컴퓨터는 인간과 달리 수행해야 하는 과제를 인간이 지정해야 한다. 인간은 해결해야 하는 문제를 스스로 설정한다.
컴퓨터는 하드웨어와 소프트웨어로 이뤄져 있다.
하드웨어 중앙처리장치(CPU), 저장장치, 입출력기기, 통신장치 등으로 이뤄져 있다.
하드웨어
범용계산기계(컴퓨터)를 작동하도록 하는 기계부품이다.
- 중앙처리장치: 과제 수행에 필요한 계산 수행
- 저장장치: 계산에 필요한 자료를 임시로 저장하는 내장메모리(예: RAM)와 자료를 장기간 저장하는 저장장치(예: HDD)로 구분한다. 내장메모리는 과제 수행에 필요한 자료를 임시로 올려 놓는 작업대에 해당한다. HDD 등 저장창치는 자료를 장기간 저장하는 일종의 창고로서 도서관의 서고에 해당한다.
- 입출력기기: 키보드 마우스 모니터 등 입력과 출력을 처리하는 기기다.
- 통신장치: 인터넷 등에 연결하는 기기
소프트웨어
범용계산기계(컴퓨터)의 작동에 필요한 신호체계다. 알고리듬과 자료(data)구조로 이뤄져 있다.
알고리듬(algorithm): 문제를 푸는 방도. 기계가 수행해야 할 특정 과제를 순서대로 알려주는 구체적인 지시의 집합이다. 알고리즘이라고도 하지만, 알고리듬이 더 정확한 표현이다. algorism은 페르시아의 수학자 알-콰리즈미의 이름에서 유래한 용어로서 ’숫자를 이용한 연산’이란 의미다.
자료구조: 데이터를 조직하는 특정한 방법. 예를 들어, 벡터(vector)는 자료의 값(value)을 1차원공간에 저장한 자료구조고, 데이터프레임(data frame)은 자료의 값을 행(row)과 열(column)의 2차원구조(테이블 구조)에 저장하는 자료구조다.
프로그래밍 언어
알고리듬을 표현하는 방식. 컴퓨터언어라고도 한다. 기계어, C, 자바, 파이썬, R 등이 있다. 프로그래밍은 알고리듬대로 소프트웨어를 만드는 작업이다.
기계어: 컴퓨터가 직접적으로 이해할 수 있는 언어.
- 가장 “낮은” 수준. 0과 1로만 이뤄짐
Fortran: 최초의 높은 수준의 범용 프로그래밍 언어. 인간의 언어에 유사
- 1954년 IBM의 John Backus 개발
C: 1970년대 개발이후 가장 널리 사용됐던 언어. compiled 언어
Java: 컴파일 한번만 하면 모든 플래폼에서 실행. compiled 언어
컴파일드(Compiled)언어 소스코드를 기계어로 미리, 한번에 번역한다.
예를 들어, C언어의 경우 소스코드(예: sample.c)를 실행프로그램(예: sample.exe)으로 컴파일해 사용한다.
- 소스코드
sample.c
#include(studio.h)
int main()
{
print("Hello World!"\n)
return 0;
}컴파일
gcc sample.c-o sample.exe기계어:
sample.exe
0001111100000111110000000000111000000000000000000000000C나 Java 등 컴파일드 언어(complied language)는 코드를 한번에 기계어로 변환한다. 한번에 변환하므로 실행이 빠르고 간편하다. 독립 소프트웨어 개발에 유리하다.
인터프리티드(interpreted)언어 프로그래밍 코드를 한줄씩 해석(기계어로 번역)해 실행한다. 한줄씩 해석하므로 코드 수정이 용이하다. 명령프롬프트 ( > )에 명령어를 한번에 하나씩 입력해서 실행한다. 바로 실행하므로 데이터분석에 편리하다.
JavaScript: 웹페이지 개발 등에 널리 사용. Java와 다른 언어
Python: 높은 수준의 범용, 인터프리티드 언어
R: 데이터분석에 특화된 높은 수준의 인터프리티드 언어
- 인간의 언어에 가까울수록 높은 수준, 기계어에 가까울수록 낮은 수준의 언어라고 한다. R와 파이썬은 C/C++, Java보다 인간의 언어에 더 가깝기 때문에 높은 수준의 언어라고 한다.
외국인과 소통할 때 영어나 중국어 등 그 나라 사람의 언어를 이용하듯, 컴퓨터에게 일을 시키기 위해서는 적절한 컴퓨터의 언어를 사용해야 한다. R은 통계학자에 의해 개발된 데이터분석에 특화된 오픈소스 컴퓨터프로그래밍언어다.
1.2.1 R 약사
- 1976년 John Chambers, R 전신인 S언어 발표
- Bell Labs
- Bell Labs
- 1994년 Ross Ihaka & Robert Gentleman R 발표
- 뉴질랜드 오클랜드 대학
- 뉴질랜드 오클랜드 대학
- 1997년 GNU project에 포함
- 현재 R Development Core Team이 개발 및 유지
1.2.2 R의 장점
정제, 분석 및 소통에 필요한 모든 기법 구현 가능
최신 통계 기법 신속 반영
뛰어난 그래픽 처리
탐색과 추론에 용이
다양한 플래폼에서 작동(윈도, 리눅스, 유닉스, 맥 등)
다양한 자료의 출처에 접근 가능
- 텍스트파일부터 데이터베이스관리시스템, 통계패키지 등
- 웹페이지, 소셜미디어 사이트 등 다양한 온라인 데이터 서비스에 직접 접근
R을 이용하는 방법에는 로컬컴퓨터(자신의 컴퓨터)와 클라우드를 이용하는 방법 2가지가 있다. R은 프로그래밍언어이고, 이 언어를 사용할 수 있도록 그래픽사용자인터페이스(Graphic User Interface: GUI)를 구성한 것인 RGui다.
- 컴퓨터에 RGui 설치해 이용
- 장점: 내 컴퓨터에서 사용하므로 편의성이 높다.
- 단점: 컴퓨터 사양이 낮으면 매우 불편하다.
- 클라우드에서 R 이용
- 장점: 컴퓨터 사양이 낮아도 브라우저만 있으면 된다.
- 단점: 매번 패키지를 설치해야 한다.
R Studio 클라우드와 구글 코랩 등이 R클라우드다. 구글 코랩의 기본값은 파이썬이지만, 이 주소로 연결하면 R이 사용언어로 설정된다.
여기서는 컴퓨터에 R을 설치해 사용한다.
1.2.3 컴퓨터에 설치하기
R project사이트에서 접속 이 주소(https://cloud.r-project.org)로 직접 접속하거나, 구글에서 “r project” 검색
본인의 운영체제에 맞는 R다운로드 후 설치. R을 설치하고 실행하면 콘솔 창이 열린다.
>프롬프트가 뜨면 정상이다 (Figure: 1.9).
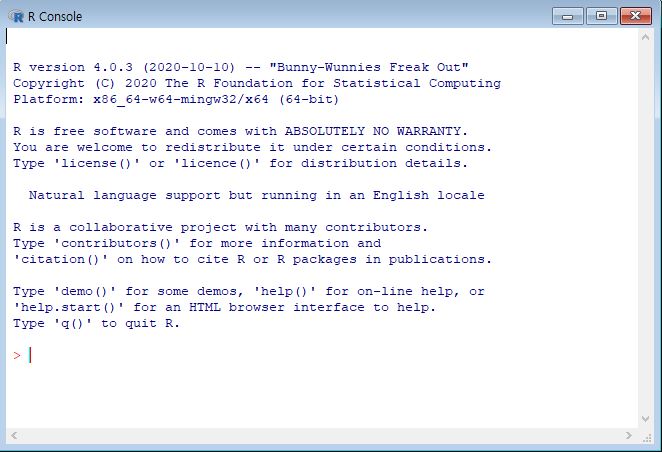
Figure 1.9: R 콘솔
1.2.4 활용해 보기: 연산
R을 설치했으니 활용해 보자. 컴퓨터는 말 그대로 계산(compute)하는 기기이므로 먼저 숫자를 계산해보자.
먼저, 프롬프트>에 숫자 두개와 +연산자(operator)를 이용해 더하는 계산을 해보자. (입력한 다음 엔터키.)
(아래 화면에서는 프롬프트가 ##로 표시됐다. ##프롬프트 앞의 숫자 [1]은 화면의 첫번째 줄이란 의미다.)
37 + 73## [1] 110R에서는 값을 객체(object)에 저장해 사용할 수 있다.
37과 73을 각각 x와 y에 저장(할당)해 보자. (할당기호 <- 를 이용한다.)
저장한 x와 y를 이용해 덧셈을 하자. (sum()처럼 컴퓨터에 일을 시키는 명령어를 함수(function)라고 한다. 뒤에서 자세하게 다룬다.)
x <- 37
y <- 73
x + y## [1] 110sum(x, y)## [1] 110곱셈도 해보자. 연산자 *를 이용하거나 prod()함수를 이용한다.
37 * 3## [1] 111prod(37, 3)## [1] 111뺄셈- 나눗셈 / 등 다양한 계산을 할수 있다.
37 - 7
37 / 7제곱 계산도 해보자. 두 가지 방법이 있다.
37 ^ 2
37 ** 3제곱근을 구하려면 어떻게 해야할까?
1369 ^ .5
1369 ** .5
sqrt(1369)이번에는 특별한 나눗셈%/%을 해보자. 즉, 나눗셈을 한 다음 나머지는 버리고 몫만 정수(integer)로 산출한다. 13을 2로 나누면 6.2인데, 나머지는 버리고 몫마 취하므로 13%/%2는 6이 된다.
13 %/% 2 복합 연산인 모둘로(modulo)%%를 해보자. 나눗셈을 하고 남는 값을 산출한다. 모둘로%%는 주로 짝수와 홀수를 구분할 때 사용한다. 2로 모둘로 계산한 결과가 1이면 홀수, 0이면 짝수.
37 %% 2 ## [1] 138 %% 2 ## [1] 0c() 함수를 이용해 값을 여러개 저장할 수도 있다. “1000, 2000, 3000, 4000”을 저장해 x에 할당(저장)하고, “3, 7”을 y에 할당(저장)하자.
x <- c(1000, 2000, 3000, 4000)
y <- c(3, 7)이렇게 저장된 객체를 벡터(vector)라고 한다.
저장된 객체는 입력하면 그 내용을 볼수 있다.
x## [1] 1000 2000 3000 4000y## [1] 3 7유용
값을 객체에 할당하면, 할당한 내용이 화면에 표시되지 않는다. 할당과 함께 할당 내용을 화면에 표시하고 싶으면 ( )를 이용한다.
( x <- 3 + 100 )## [1] 103두 객체를 두 줄이 아닌 한줄에 기술하고 싶은면 ;를 이용한다.
x; y## [1] 103## [1] 3 7print()함수를 이용해도 화면에 객체의 내용 출력
print(x)## [1] 103print(y)## [1] 3 7방금 만든 x와 y를 더해보자. 계산 결과를 보고, 덧셈의 순서가 어떻게 이뤄졌는지 추론하자.
x + y## [1] 106 110저장된 값은 [ ]를 이용해 일부만 부분선택(subset)할 수 있다. 방금 만든 벡터 x에서 두번째 값을 부분선택해보자.
x[2]## [1] NA-를 이용하면 부분선택해 제외한다.
x[-2]## [1] 103여러개를 부분선택하려면 선택하려는 값을 벡터로 만들어 투입한다. 두번째와 세번째 요소를 부분선택해 보자.
x[c(2,3)]## [1] NA NA반대로 두번째 요소와 세번째 요소를 제외하고 부분선택하자.
x[-c(2,3)]## [1] 103유용
- 키보드의 control키와 L키를 함께 누르면 콘솔 화면이 정리된다.
- 키보드의 상하 방향키를 이용하면 이전에 입력했던 명령어를 다시 사용할 수 있다.
컴퓨터는 숫자만 계산하지 않는다. 문자도 “계산”한다. 우선, print()함수를 이용해 글자를 화면에 표시해 보자. (R은 대문자와 소문자를 구분한다. 예를 들어, print()와 Print()를 구분한다.)
print("Hello World!")## [1] "Hello World!"중요!!! 따옴표와 괄호는 짝이 맞아야 한다. 특히, 괄호의 짝을 맞추는 것이 매우 중요하다.
아래처럼 콘솔에서 괄호를 닫지 않고 실행하면 어떻게 될까?
> print("Hello World!"계산결과가 나오지 않고 아래와 같이 프롬프트에 +표시가 나타난다. 계산이 완료되지 않아, 컴퓨터가 사용자의 입력을 기다리고 있다는 의미다. 엔터키를 누르면 +프롬프트만 나올뿐이다.
> print("Hello World!"
+
+
+해결 방법은? 마무리다. 연 괄호가 1개( 있으니, 닫을 괄호를 +프롬프트에 1개 ) 입력해 괄호의 수를 맞춰준다.
> print("Hello World!"
+
+
+ )
[1] "Hello World!"1.3 IDE(통합개발환경)
콘솔의 프롬프트에서 작업하면 한줄씩 입력해야 하므로 불편하다. 메모장 같은 텍스트 편집기를 이용해 코드를 작성해 붙여 넣기도 하고, 프로그래밍을 위한 전용 편집기(Notepad++, Atom 등)를 이용하기도 한다.
프로그래밍을 효율적으로 할 수 있도록 해주는 도구가 IDE(Integrated Development Environment)다. 코드 편집기 외에 다양한 부가기능이 있다. R을 위해 가장 널리 쓰이는 IDE가 RStudio다. (다양한 IDE가 있는데, 프로그래밍 언어 별로 특화한 IDE가 있고, 범용 IDE가 있다. RStudio는 R에 특화한 IDE이고, 파이참(PyCharm)은 파이썬 언어에 특화한 IDE다. 여러 프로그래밍 언어에서 사용할 수 있는 범용 IDE로는 이클립스(eclipse)가 있다.)
1.3.1 RStudio 설치
구글 등 검색엔진에서 ’rstudio’를 검색하거나 이 링크 R Studio Desktop Free에서 다운로드 받아 설치한다.
설치한 다음 아래처럼 실행되면 설치에 성공한 것이다 (Figure 1.10). 화면에 3개의 창틀이 열려 있는데, 각 창을 pane(창틀)이라고 한다.
왼쪽에 보이는 ’Console’이라고 된 창이 R을 실행했을 때 코드를 입력했던 콘솔 창이다. R의 콘솔과 동일하므로 사용법도 같다.
오른쪽 위의 창이 작업공간(Workspace)이다. 작업한 내용이 임시로 메모리(RAM)에 생성되는 작업 환경(Environment).
오른쪽 아래 창은 작업디렉토리. 파일이 저장돼 있는 하드디스크의 내용 표시.
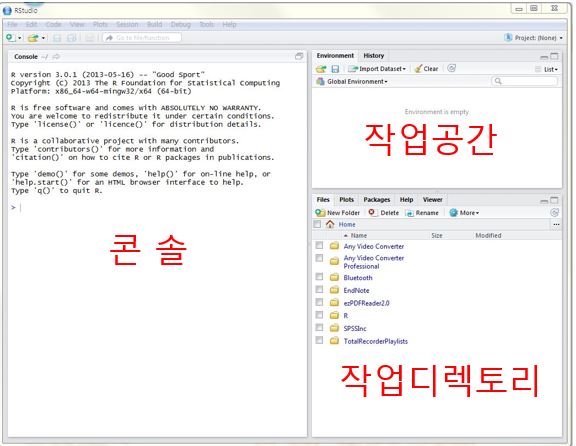
Figure 1.10: R스튜디오 화면 구성
1.3.2 한글사용 설정
R스튜디오는 영어 알파벳을 기반으로 만들어 졌기 때문에 언어구성이 다른
한글을 사용하기 위해서는 부호변환(encoding) 설정이 필요하다. 부호변환 방식은 운영체제(OS)에 따라 다르다. 리눅스와 애플을 맥OS는 UTF-8를 이용하고, 한글윈도는 CP949를 쓴다. (중국어 아랍어 등 각 언어별로 고유의 인코딩 방식이 있다.)
한글윈도에서 사용하는 CP949는 마이크로소프트 고유의 확장완성형 인코딩이다. R스튜디오에서 한글을 이용하기 위해서는 이를 UTF-8로 변경해야 한다.
- RStudio 상단메뉴
Tools를 클릭 - 드롭다운 메뉴가 열리면
Global options선택. Options창이 열리면 화면에서Code메뉴에서Saving탭을 클릭 (Figure 1.11)Default text encoding:에서UTF-8으로 설정한다 (R스튜디오 1.42기준. 버전에 따라 화면이 조금 다르지만 기본적인 구성은 같다.)
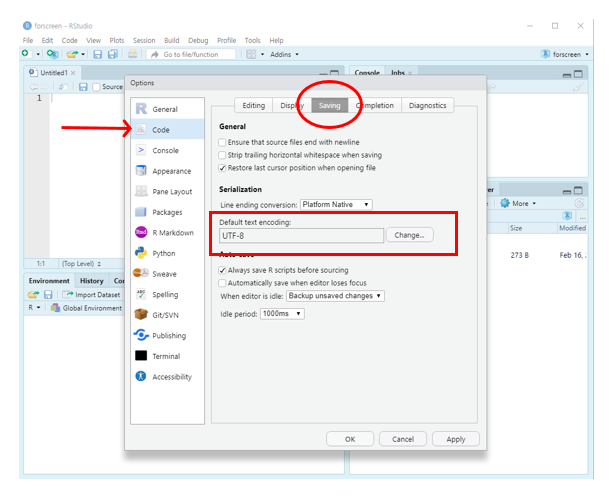
Figure 1.11: R스튜디오 인코딩 설정
1.3.3 프로젝트 만들기
R작업을 할때 프로젝트로 만들어 작업을 관리하는 것이 상당히 유용하고 편리하다. (물론, 반드시 프로젝트로 관리해야 하는 것은 아니다.)
- R스튜디오 화면 상단 왼쪽 위에 있는
File을 클릭하면 드롭다운 메뉴가 열린다.New Project를 클릭하면 아래 창이 열린다 (Figure 1.12).
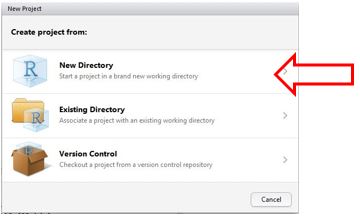
Figure 1.12: R 프로젝트 만들기
위 그림에서 New Directory를 클릭하면 열리는 창에서 Empty Project를 선택하면 아래 창이 열린다. Browse... 버튼 클릭해 프로젝트 파일 설치할 디렉토리 선택하고, 그 아래에 생성할 디렉토리 명을 Directory name:에 입력한다. 아래 그림은 “K:/data”폴더를 선택한 화면이다 (Figure 1.13).
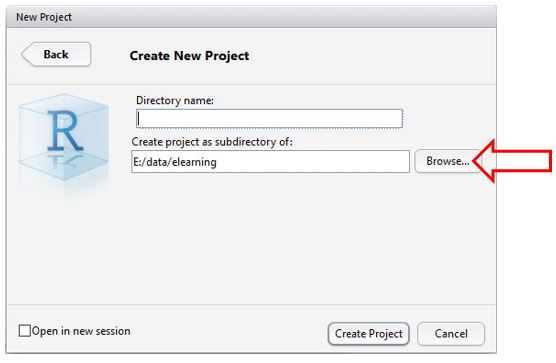
Figure 1.13: 디렉토리 이름 정하기
예를 들어, Directory name:에 ’git2015’라고 입력하고, 아래 Create Project 버튼을 클릭하면, “K:/data”아래 ’git2015’란 폴더가 생성되면서 “K:/data/git2015”가 작업디렉토리가 된다 (Figure 1.14).
아래 화면을 보면:
- 왼쪽 위의 콘솔 창에 작업디렉토리(K:/data/git2015)가 표시돼 있다.
- 오른쪽 위의 작업공간 위에 새로 만든 프로젝명(git2015)이 보인다.
- 오른쪽 아래 작업디렉토리에 새로 만든 프로젝트 파일(확장자가 .Rproj)이 생성돼 있다.
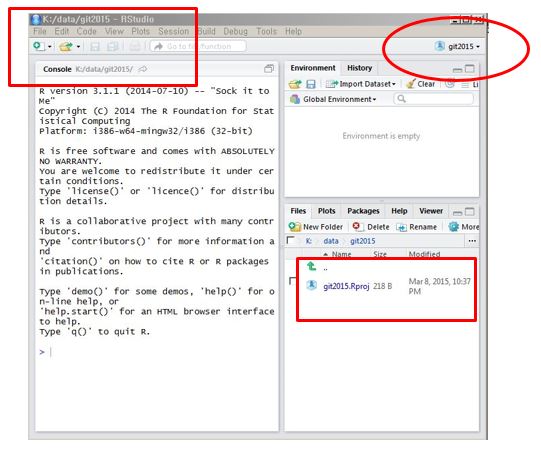
Figure 1.14: R 프로젝트 생성
1.3.4 편집창 열기
IDE를 사용하는 하는 이유 중 하나가 편집기(Editor)를 사용하기 위해서다. 콘솔에서는 한번에 한줄만 입력해 실행하지만, 편집창에서는 코드를 여러줄 입력해 실행할 수 있다 (Figure 1.15).
- 아래 그림의 화살표가 가리키는 아이콘을 클릭하면 열리는 창에서
R Script를 선택
또는
- 단축키로
Ctrl + Shift + N입력
또는
- 상단메뉴
File을 클릭하면 열리는 드롭다운 메뉴에서New File선택
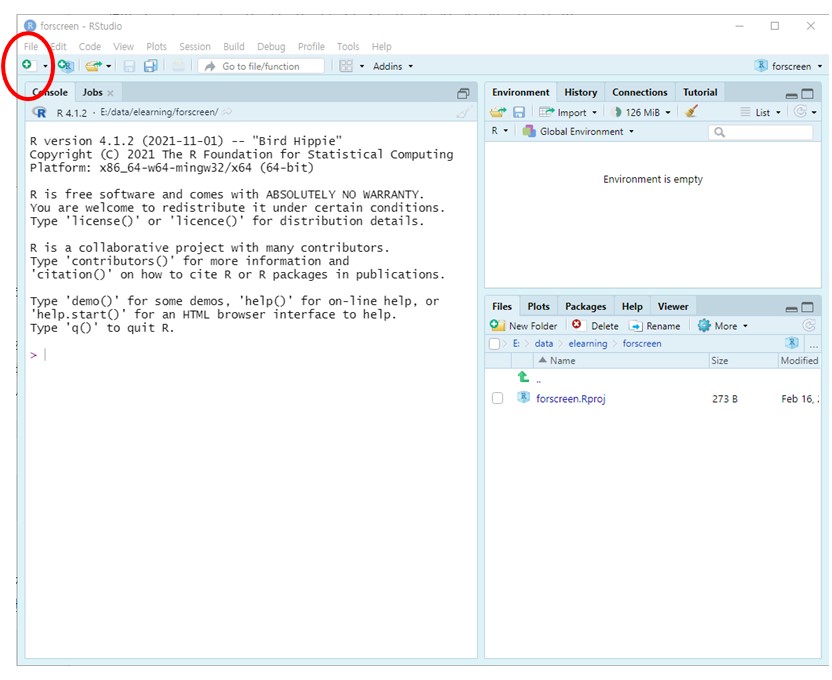
Figure 1.15: R 편집창 열기
아래처럼 편집창이 열리면 RStudio를 이용한 코딩 준비가 된 것이다 (Figure 1.16).
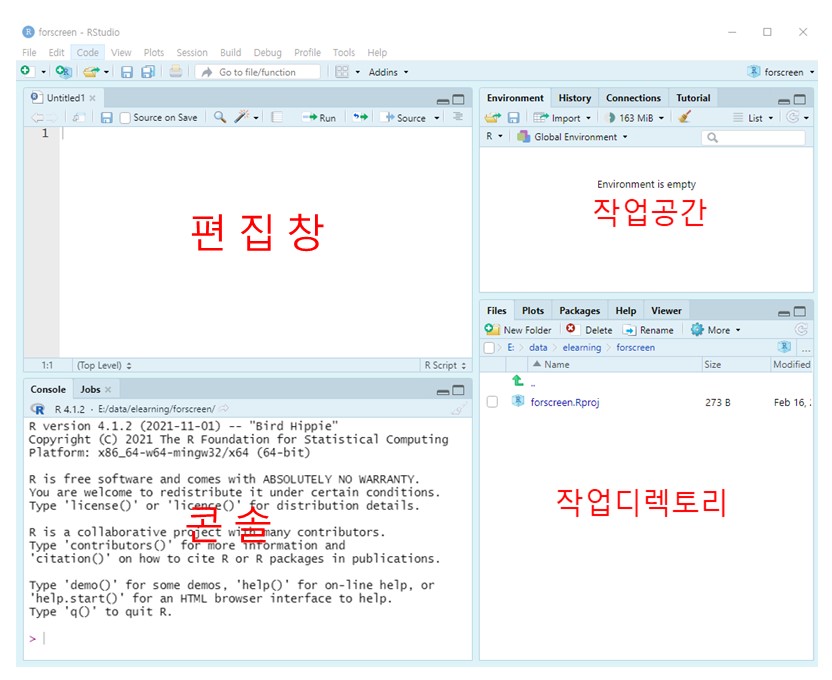
Figure 1.16: R 편집기
편집창에 코드를 입력하면 탭의 Untitled가 빨간색으로 변한다 (Figure 1.17). 편집창에 아래 코드를 입력해보자. (코드의 구체적인 의미는 뒤에서 설명한다.)
var_x <- c(10, 20, 30, 40)
var_y <- c(3, 7)
add_f <- function(x, y){
output <- x + y
return(output)
}
add_f(var_x, var_y)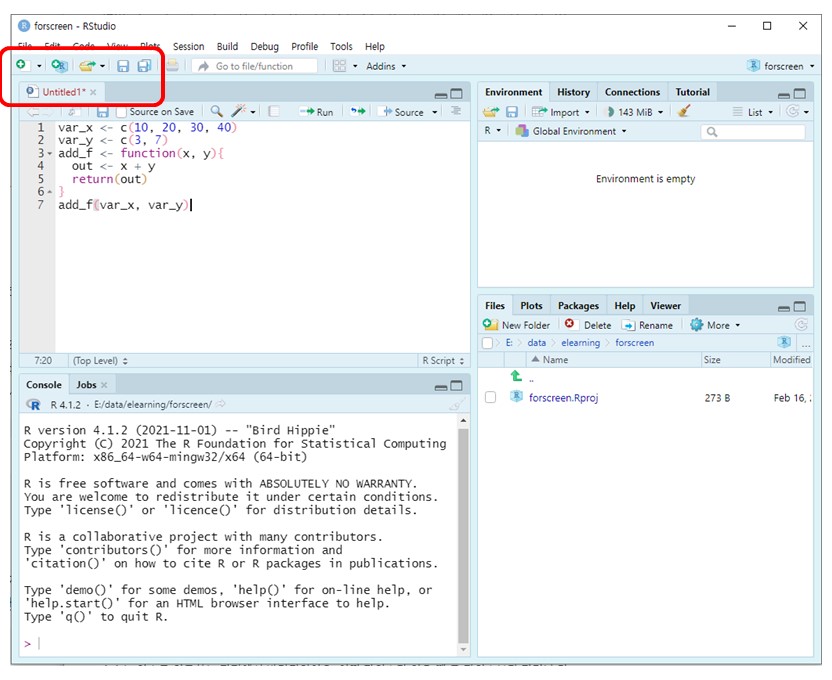
Figure 1.17: R 파일 저장
디스크 모양 아이콘 클릭해 파일 이름을 지정해 저장한다 (혹은 File메뉴 클릭해 열리는 드롭다운 창에서 Save 선택. 또는 단축키
Ctrl + S). 예를 들어, my_first_rfile.R라고 파일명을 지정하면 확장자가 .R인 파일 my_first_rfile.R이 작업디렉토리에 생긴다. 오른쪽 아래 작업디렉토리에서 생성된 파일을 확인할 수 있다
1.3.5 작업디렉토리(working directory)
사용중인 R환경에서 파일을 읽고 저장하는 디렉토리 (또는 폴더)로서 하드디스크 공간이다.
getwd(): 현재의 작업디렉토리를 알려준다. wd는 working directory의 약자. 즉, getwd는 working directory를 get하라는 의미.
자신의 작업디렉토리를 파악해보자.
getwd() 주의!!! 윈도는 드라이브명 다음에 역슬래시C:\를 사용하지만, R에서는 정슬래시 C:/를 이용한다.
setwd(): 지정한 폴더를 작업디렉토리로 설정. working directory를 set하라는 의미다.
만일 작업디렉토리를 설정하고자 하는 폴더가 드라이브에 없으면?
컴퓨터의 탐색기를 열어 해당 폴더를 만들거나, R콘솔에서 폴더 생성 함수dir.create()로 해당 폴더를 만든다.
’newfolder’라는 폴더를 C드라이브에 만들려면 다음과 같이 한다.
dir.create("C:/newfolder")1.3.6 코드 실행
편집창에서 마우스 커서가 있는 줄의 코드를 실행하는 방법은 다음과 같다.
편집창에서
콘트롤+엔터키RStudio 편집창 화면에서
Run아이콘 클릭 (Figure 1.18).
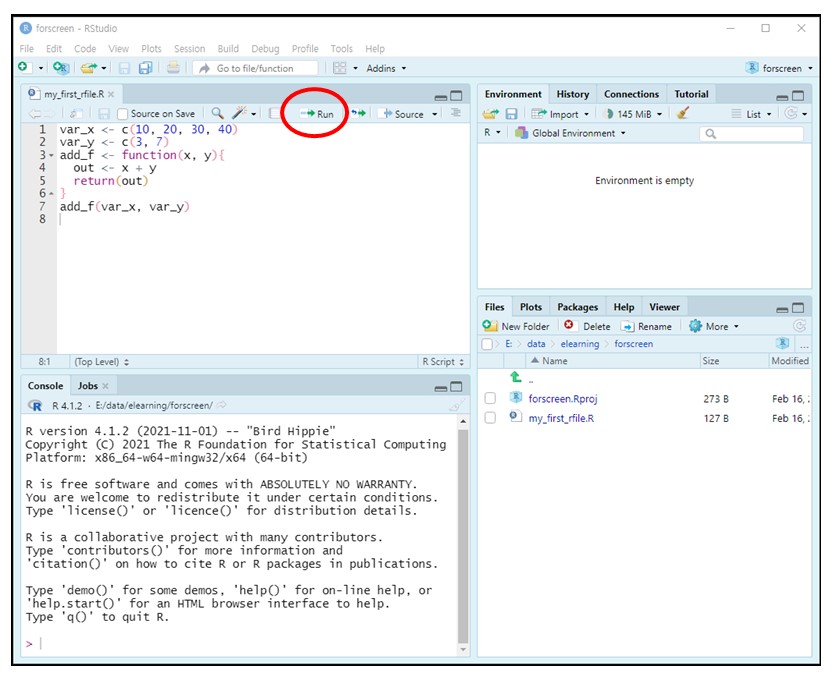
Figure 1.18: R 코드 실행
여러 줄의 코드를 동시에 실행하려면 실행하려는 코드를 마우스로 드랙해 설정한 다음, 콘트롤 + 엔터키를 입력하거나, 혹은 RStudio 편집창 화면에서 Run아이콘 클릭 (Figure 1.19).
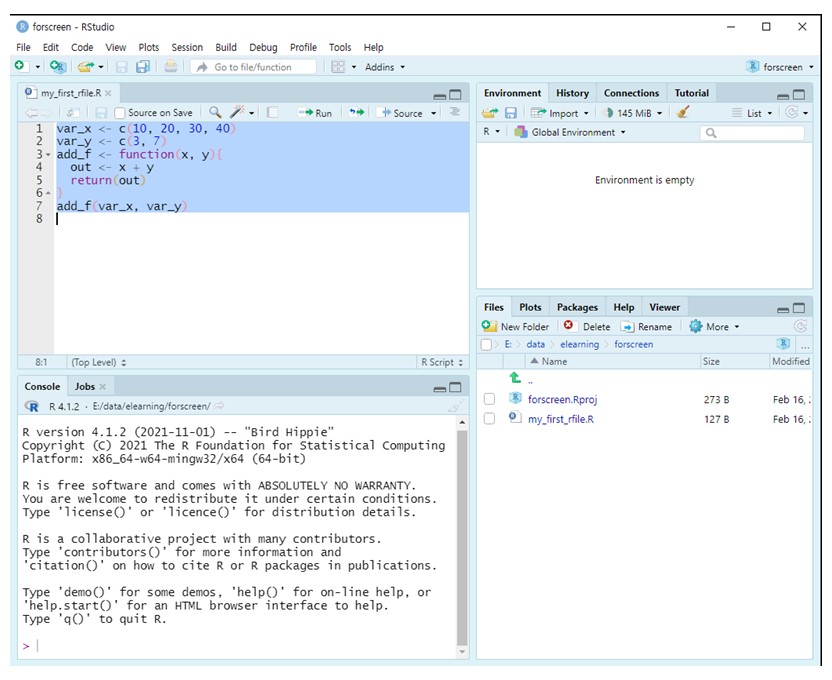
Figure 1.19: R 코드 여러 줄 실행
1.3.7 작업공간(workspace)
현재 실행중인 R의 작업환경이다. 사용자가 생성한 객체(object)가 저장돼 있는 곳이다. 컴퓨터의 하드디스크가 아니라 메모리에 올려져 있다. R을 종료하면 함께 사라진다.
아래 코드를 편집기에 입력한 다음 실행해 RStudio의 콘솔 화면과 작업공간 화면이 어떻게 바뀌는지 살펴 보자 (Figure 1.20).
var_x <- c(10, 20, 30, 40)
var_y <- c(3, 7)
add_f <- function(x, y){
output <- x + y
return(output)
}
add_f(var_x, var_y)콘솔에는 코드와 실행결과가 나타난다.
작업공간에는 생성된 객체(object)와 객체의 내용이 나타난다.
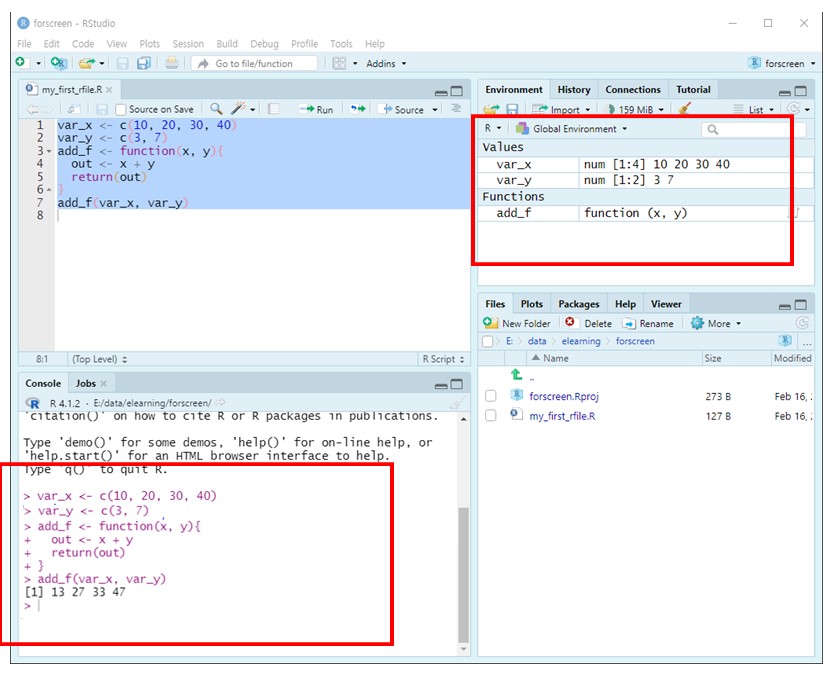
Figure 1.20: R 코드 실행후 화면
ls()함수는 작업공간의 객체의 목록(list)을 보여준다. 조금 전에 객체 var_x, var_y, add_f을 만들었으므로 ls()함수를 콘솔에 입력하면 이 세 객체가 콘솔에 나타난다.
ls()rm()함수는 작업공간의 객체를 제거(remove)한다. 객체 x, y, fit를 제거하고 ls()함수를 실행해보자. x, y, fit을 제외한 R환경에 탑재돼 있는 객체의 목록이 나타난다.
rm(var_x, var_y, add_f)
ls()주의!!! 작업공간(working space)은 메모리에 생성된 작업환경이고 작업디렉토리(working directory)는 HDD(하드디스크)에 생성된 폴더다.
list.files()현재의 작업디렉토리에 있는 파일과 폴더 목록 보여준다.ls()는 작업공간의 객체 목록을 보여준다.
주의!!! " "와 아포스트로피(apostrophe) “ ”는 다른 기호다. 다른 문서에서 코드 복사해 사용할때 주의.
R스튜디오 사용법을 정리한 요약본(cheat sheet)은 여기서 다운로드 받을 수 있다. 전반적인 기능이 잘 정리돼 있다.
유용
R을 종료할때 “Save workspace image?”라는 창이 뜬다. 작업공간에 저장된 객체는 이미지파일로 하드디스크에 저장할 것인지 묻는 메시지다. ’예’를 선택하면 현재 작업공간의 객체들이 모두 .RData파일로 저장된다. 이 이미지 파일의 내용은 R을 다시 기동하면 작업공간으로 다시 올려진다. 이런 결과가 불편할때가 많다. 이 설정을 끄는 것이 좋다 (Figure 1.21).
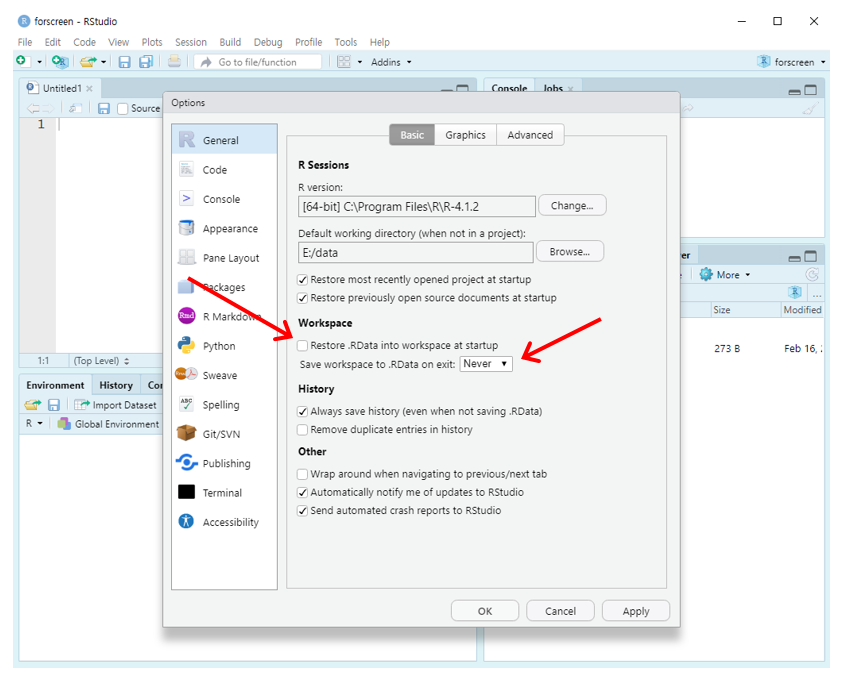
Figure 1.21: .RData 복원하지 않기 설정
1.4 함수·객체·인자
R과 같은 프로그래밍 언어는 함수, 객체, 및 인자를 통해 기능을 구현한다.
1.4.1 객체(object)
데이터, 함수, 그래프, 분석결과 등을 할당해 객체를 생성한다. 아래 예시는 hello_v라는 객체에 “Hello World!”라는 문자를 할당(assign)해 객체를 만들었다.
hello_v <- "Hello World!"할당할 때는 할당 연산자 <-를 사용한다. =를 사용해도 된다. 다른 프로그래밍 언어에서는 객체를 생성할 때 값을 할당하기 위해 =를 주로 사용한다. R프로그래밍에서는 <-를 주로 사용한다. =를 이용해 할당하면 오류가 생기는 경우가 가끔 있다.
할당할 객체를 오른쪽에 놓고 싶을 때는 ->를 이용한다. 사고의 흐름과 일치해 코딩과정이 효과적이다.
"Hello World!" -> hello_v반드시 기억
생성된 객체는 내장 메모리에 저장된다. 객체를 따로 저장하지 않으면, R세션을 종료시 생성된 객체는 사라진다. 객체를 다시 사용하려면 외부저장장치(예: HDD)에 파일로 저장해야 한다.
생성한 객체의 내용을 보는 방법은 다양하지만, 가장 기본적인 방법은 프롬프트에 객체명을 입력하는 것이다. 프롬프트(아래 화면에서는 ## [1]로 표시)에 객체에 저장된 내용이 나타난다. 프롬프트에 표시된 숫자 [1]은 현재 표시된 화면에서 첫번째 줄이라는 의미다.
hello_v## [1] "Hello World!"객체의 이름
- 객체의 이름은 문자로만 시작한다.
- 객체 이름에는 문자, 숫자,
_,.만 포함한다.
1.4.2 함수(function)
특정 동작을 수행하는 객체다. 알고리듬이 함수에 구현돼 있다. 언어로 따지면 동사에 해당한다. 예를 들어, print()는 “출력하다”는 동작을 지정한 함수다. (함수의 이름도 동사를 사용한다.) 앞서 만든 “hello_v” 객체의 내용을 화면에 출력하려면 다음과 같이 쓴다.
print(hello_v)c()는 벡터 데이터구조를 만드는 함수다. ’c’는 concatenate(사슬같이 잇다) 혹은 combine(결합하다)이란 의미다. 개별 값을 결합하는 기능을 하기 때문이다.
“37, 41, 53”를 벡터로 만들어 number_v에 할당하자.
number_v <- c(37, 41, 53)벡터(vector) 값을 모아 1차원 구조로 만들어진 데이터구조를 벡터(vector)라고 한다. 물리학에서 개별 값은 스칼라, 방향성을 지닌 값을 벡터라고 하는데서 온 용어다. 개별 값을 1차원 구조로 방향성이 있도록 저장해 놓았기 때문이다.
37, 41, 53을 더한 값을 구해보자. +연산자를 이용할 수 있다.
37 + 41 + 53함수를 이용해 보자. sum()함수를 이용할 수 있다.
sum(c(37, 41, 53))무지개괄호 따옴표와 괄호는 짝이 맞아야 한다. 특히, 괄호의 짝을 맞추는데 주의하자. 괄호를 2개 열었으면, 닫는 괄호도 2개여야 한다. RStudio의 무지개괄호(rainbow parenthesis) 기능을 이용하면 괄호의 색을 달리 표현해 괄호를 정확하게 막는데 도움이 된다.
객체를 만들었으니 활용하자.
number_v <- c(37, 41, 53)
sum(number_v)## [1] 131length()는 ’개수를 구하라’는 동작의 함수다. number_v벡터에 요소가 몇개 있는지 계산해보자.
length(number_v)## [1] 3R에는 세 종류의 함수가 있다.
내장 함수: R을 설치하면 기본적으로 함께 제공되는 함수. R함수라고 줄여 말하기도 한다. 합을 구하는
sum(), 평균을 구하는mean(), 표준편차를 구하는sd(), 벡터를 만드는c()함수 등이 내장함수다. 패키지를 설치하는install.packages(), 설치한 패키지는 R환경에 탑재하는library()도 내장함수다.패키지 함수: 추가로 설치하는 패키지에서 제공하는 함수. 많이 사용하는 패키지로는 데이터를 다루는데 사용하는
dplyr패키지, 다양한 종류의 파일을 R환경으로 가져오는(import)rio패키지가 있다. 패키지함수는 해당 패키지를 R환경에 탑재해야 쓸수 있다. 예를 들어,rio패키지의import()함수를 이용하려면 먼저install.packages("rio")로rio패키지를 컴퓨터에 설치하고,library(rio)로 R환경에 탑재해야 한다.
패키지는 R함수, 데이터, 완성된 코드를 정리해 종합한 꾸러미(package)다. 모아 놓았기 때문에 라이브러리(library)라고도 한다. install.packages("패키지이름")으로 설치하고 library(패키지이름)로 R환경에 탑재해서 사용한다.
- 사용자 함수: 사용자가 자신의 편의를 위해 만든 맞춤형 함수다. 예를 들어, 합과 개수를 한번에 계산하고 싶으면
sum()과lenghth()등 2개 함수를 모아 하나의 함수로 만들면 사용자 함수가 된다.function()함수를 이용해 만든다.
아래 사례가 합과 개수를 한번에 계산하는 사용자 함수다.
describe_f <- function(x){
out_s <- sum(x)
out_n <- length(x)
output <- c(out_s, out_n) # 값이 2개 생성되므로 이를 벡터에 저장.
return(output)
}주석(comment) #
코딩할 때 코딩한 내용에 대해 사람이 참조하기 위해 기록을 남길 필요가 있다. #부호가 있으면 컴퓨터에게는 해석(interpret)할 필요가 없다는 의미가 돼, #부호 다음의 내용은 컴퓨터가 계산하지 않고 주석내용을 화면에 표시만 한다.
사용자 함수를 만들기 위해서는 3가지 요소를 지정해야 한다.
함수의 이름: 위의 사례에서는
describe_f라고 이름을 부여했다. 함수는 동작을 지정하므로 함수의 이름은 동사로 설정한다. (사용자 함수 명에_f를 붙인 이유는 다른 내장함수나 패키지함수와의 중복을 피하기 해서다. 예를 들어,psych패키지에서 기술통계치를 구하는 함수가describe()다.)함수에 투입할 인자(argument): 위의 예에서 함수의 계산 대상이 하나이므로 인자
x를 하나만 지정했다. 만일, 계산 대상이 두 개면 인자를 두 개(예:function(x, y)지정한다. (인자의 명칭으로 반드시 “x”나 “y”를 사용할 필요는 없다. 어느 문자를 써도 무관. 다만 일관성있게 사용).
함수의 계산 대상이 되는 요소를 인자(argument 혹은 parameter)라고 한다. 다양한 인자를 이용해 함수를 보다 정밀하게 사용할 수 있다. 언어로 치면 목적어, 보어, 수식어 등에 해당한다. 함수는 서술어에 해당. 뒤에서 상술.
- 실행할 코드:
function()함수 다음에{ }사이에 실행할 코드를 기입한다. 마지막 줄의return()은 함수가 계산한 결과를 산출(반환: return)해 보여주는 동작을 지정한 함수다. 여기서는 합(sum(x))과 개수(length(x)를 구한다음, 두 객체를 결합(c(out_s, out_n))하는 함수가 포함돼 있다. 끝으로return()함수로 계산한 결과를 산출하도록 하면 실행부가 완성된다.
띄어쓰기 코딩도 글쓰기이므로 가독성을 위해 띄어쓰기를 적절하는 하는 것이 바람직하다. 눈이 피곤하면 bad. 오해의 여지가 없어야 good.
- 연산자는 앞뒤로 띄어쓰는 것이 원칙.
- good:
37 + 73
- bad:
37+73 - good:
object_name <- c("value1", "value2")
- bad:
object_name<-c("value1","value2")
- good:
- 붙여써야 하는 경우도 있다.
- good:
37:73
- bad:
37 : 73
- good:
심화
전역(global) 환경 vs. 국지(local) 환경:
전역환경은 사용자의 작업공간(working environment)이다. 사용자가 만든 객체가 저장되는 공간이다. 그런데, 이 작업공간이 국지적으로(locally) 특정 영역에만 임시로 설정되기도 한다. 사용자 함수를 만들 때 지정한 { }가 임시로 설정한 국지환경이다. 국지환경 { }안에서 만들어진 객체는 전역환경에 저장되지 않는다. 따라서, 위의 사용자함수에서 생성한 객체(out_s, out_n, output)는 { }안의 국지환경에만 사용되고 사라진다.
만든 사용자함수를 이용해 합과 개수를 한번에 계산해 보자.
describe_f(number_v)## [1] 131 3합과 개수를 구했지만, 무엇이 어떤 산출값인지에 대한 알기 어렵다. 라벨을 추가해보자.
describe_f <- function(x){
out_s <- sum(x)
out_n <- length(x)
output <- c(out_s, out_n)
names(output) <- c("합", "개수") # names()로 값의 라벨 설정
return(output)
}
describe_f(number_v)## 합 개수
## 131 3이번에는 숫자 두개를 더하는 사용자함수를 만들어 보자.
add_f <- function(x, y){
output <- x + y
return(output)
}이렇게 만든 사용자 함수를 이용해 37과 73을 더해 보자.
add_f(37, 73)## [1] 110이번에는 값이 여러개인 벡터를 더해 보자. 계산 결과를 보고, 어떤 순서로 계산했는지 추론해 보자.
var_x <- c(100, 200, 300, 400)
var_y <- 2
add_f <- function(x, y){
output <- x + y
return(output)
}
add_f(var_x, var_y)## [1] 102 202 302 402var_x <- c(100, 200, 300, 400)
var_y <- c(3, 7)
add_f <- function(x, y){
output <- x + y
return(output)
}
add_f(var_x, var_y)## [1] 103 207 303 4071.4.3 인자(argument 또는 parameter)
인자는 함수 실행에 필요한 데이터, 실행방식 등의 값을 투입하는 입력 객체다. 함수가 동사로서 서술어라면, 인자는 목적어나 수식어 등에 해당한다. 예를 들어, 아래의 코드는 paste()라는 동작을 x와 y라는 목적어 인자에 대해 sep =인자의 방식으로 동작하라는 의미다. 즉, sep =인자를 투입해 x와 y의 값이 결합해 작동하는 방식을 지정했다. 아래 코드는 x와 y의 값 사이에 "과 "를 넣으라는 의미가 된다.
x <- "10"
y <- "20"
paste(x, y, sep = "과 ")## [1] "10과 20"함수에는 기본적으로 지정된 기본값(default)이 있다. paste()함수의 sep =인자 기본값(default)은 " "이다. 기본값은 따로 지정하지 않아도 된다. 즉, paste(x, y)와 paste(x, y, sep = " ")의 산출 결과는 동일하다.
기술문(statement) 함수, 객체, 인자 등을 이용해 구성한 일련의 코드를 기술문이라고 한다.
도움말: R의 모든 함수와 인자를 기억해 사용할 수 없다. 도움말을 이용해야 한다. 일반적인 도움말은 help.start()함수를 이용한다. 개별 함수에 대한 도움말은 help("함수")나 ?함수의 형식으로 입력한다.
c()함수에 대해 알고 싶으면?chelp("c")
mean()함수의 도움말은:?meanhelp("mean")
1.5 반복(for)
프로그래밍을 하는 이유는 기계에 반복작업을 시키기 위해서다. 예를 들어, 이상의 오감도를 보자 (원 시의 내용을 편의상 “아해가”를 모두 “아해도”로 바꿨다).
제1의아해도무섭다고그리오.
제2의아해도무섭다고그리오.
제3의아해도무섭다고그리오.
제4의아해도무섭다고그리오.
제5의아해도무섭다고그리오.
제6의아해도무섭다고그리오.
제7의아해도무섭다고그리오.
제8의아해도무섭다고그리오.
제9의아해도무섭다고그리오.
제10의아해도무섭다고그리오.
제11의아해도무섭다고그리오.
제12의아해도무섭다고그리오.
제13의아해도무섭다고그리오.숫자가 1부터 13까지 바뀌는 것 외에는 같은 문장이 반복된다. 반복작업은 사람보다 기계가 훨씬 잘한다. for 반복문(loop)으로 기계가 쓰도록 해보자.
nn <- 13 # 만들 문장의 수
output <- vector() # 컨테이너
for(i in 1:nn){
output[i] <- paste0("제", i, "의아해도무섭다고그리오.")
}
output## [1] "제1의아해도무섭다고그리오." "제2의아해도무섭다고그리오."
## [3] "제3의아해도무섭다고그리오." "제4의아해도무섭다고그리오."
## [5] "제5의아해도무섭다고그리오." "제6의아해도무섭다고그리오."
## [7] "제7의아해도무섭다고그리오." "제8의아해도무섭다고그리오."
## [9] "제9의아해도무섭다고그리오." "제10의아해도무섭다고그리오."
## [11] "제11의아해도무섭다고그리오." "제12의아해도무섭다고그리오."
## [13] "제13의아해도무섭다고그리오."for 반복문은 세개요소로 이뤄져 있다.
컨테이너: 반복 작업을 통해 생성될 값을 저장할 객체를 미리 만들어 놓은 객체. 일반적으로 컨테이너에는 값을 할당하지 않는 빈 객체를 만든다. 여기서는 컨테이너를 빈 벡터로 만들었다. for반복문에서 빈 벡터는
vector()함수로 만든다.c()함수가 느리기 때문이다.카운터와 범위:
for(i in X)표현식의( )안의 있는i가 카운터다.X는 카운터의 범위(~부터 ~ 까지).X는 위의 코드에서1:nn이다.nn에 “13” 값이 할당돼 있으므로i in 1:nn은 “i 카운터를 1부터 13까지 순서대로 투입해 작업하라”는 의미가 된다. (관례적으로 카운터를 i로 사용하지만, 어느 문자를 써도 관계없다. 일관성있게 쓰면 된다.)실행부:
{ }안의 함수를 반복해서 실행하는 부분.output[i] <- paste0("제", i, "의아해도무섭다고그리오.")에서i를for( )에서 지정한 범위인 1부터 13까지 순서대로 투입해 실행하게 된다.
반복작업이 이뤄지는 과정이 보이지 않아 답답할 수 있다. cat()함수를 이용하면 반복 작업내용을 화면에 표시할 수 있다. \n은 “new line”이란 의미다.
nn <- 13 # 만들 문장의 수
output <- vector() # 컨테이너
for(i in 1:nn){
output[i] <- paste0("제", i, "의아해도무섭다고그리오.")
cat(output[i], "\n") # `\n`은 "new line"
}## 제1의아해도무섭다고그리오.
## 제2의아해도무섭다고그리오.
## 제3의아해도무섭다고그리오.
## 제4의아해도무섭다고그리오.
## 제5의아해도무섭다고그리오.
## 제6의아해도무섭다고그리오.
## 제7의아해도무섭다고그리오.
## 제8의아해도무섭다고그리오.
## 제9의아해도무섭다고그리오.
## 제10의아해도무섭다고그리오.
## 제11의아해도무섭다고그리오.
## 제12의아해도무섭다고그리오.
## 제13의아해도무섭다고그리오.1.5.1 팩토리얼
팩토리얼(\(!\))은 숫자를 1씩 늘려 곱하는 계산이다. 4의 팩토리얼(4\(!\))을 계산한다면, 숫자를 1씩 늘려 곱하므로(4x3x2x1) 다음과 같이한다.
x <- 1
x <- x * 1
x <- x * 2
x <- x * 3
x <- x * 4
x## [1] 24같은 작업이 반복되므로 for 반복문으로 해결할 수 있다.
nn <- 4
x <- 1 # 컨테이너
for(i in 1:nn){ # 카운터와 범위
x <- x * i # 실행부
}
x## [1] 24팩토리얼 계산하는 과정을 cat()함수로 화면에 표시해 보자.
nn <- 4
x <- 1
for(i in 1:nn){
x <- x * i
cat(x, "<-", x, "*", i, "\n")
}## 1 <- 1 * 1
## 2 <- 2 * 2
## 6 <- 6 * 3
## 24 <- 24 * 4팩토리얼을 자주 구해야 한다면, 매번 반복문을 쓰는 것은 비효율적이다. 팩토리얼 구하는 사용자함수를 만들자.
fact_f <- function(nn) {
x <- 1
for (i in nn) {
x <- x * i
}
return(x)
}
fact_f(4)## [1] 4팩토리얼을 구하는 R 내장함수는 factorial(n)이다.
factorial(4)## [1] 241.5.2 순열
순열(permutation)을 구해보자. 순열은 서로 다른 대상을 뽑아 정렬하는 방법 중 하나다. 순서를 고려해 배열하기 때문에 순열이다.
순열은 permutation이므로 \(_{n}P_{k}\)로 표현한다. \(n\)개의 대상을 순열해(\(P\)) \(k\)개를 산출하는 경우의 수라는 의미다. “사과, 배, 딸기, 포도” 4개를 순열해 2개를 뽑는 경우의 수(\(_{4}P_{2}\))는 다음과 같이 12개다.
("사과", "배")
("사과", "딸기")
("사과", "포도")
("배", "사과")
("배", "딸기")
("배", "포도")
("딸기", "사과")
("딸기", "배")
("딸기", "포도")
("포도", "사과")
("포도", "딸기")
("포도", "배") 이 12개의 경우의 수를 직접 손으로 쓰지 않고, 프로그래밍으로 해결하는 방법을 단계별로 살펴보자.
먼저 뽑을 대상을 화면에 표시해보자. 범위를 설정하는 함수는 seq_along()을 이용한다.
fn <- c("사과", "배", "딸기", "포도")
seq_along(fn)## [1] 1 2 3 4fn <- c("사과", "배", "딸기", "포도")
for(i in seq_along(fn)){
cat(fn[i], "\n")
}## 사과
## 배
## 딸기
## 포도\(_{4}P_{2}\)는 2개를 뽑아야 하므로 짝을 지어 화면에 표시해보자.
fn <- c("사과", "배", "딸기", "포도")
for(i in seq_along(fn)){
cat(fn[i], ", ", fn[i], "\n")
}## 사과 , 사과
## 배 , 배
## 딸기 , 딸기
## 포도 , 포도이번에는 연속적으로 같은 값이 반복해서 나오도록 해보자. 이를 위해서는 loop를 이중으로 작성(double loop)해야 한다. i인덱스의 첫째 값(예: 사과)이 투입된 상태에서 j인덱스를 반복하고, i인덱스의 둘째 값(예: 둘째)이 투입된 상태에서 j인덱스를 다시 반복하는 방식이다.
fn <- c("사과", "배", "딸기", "포도")
for(i in seq_along(fn)){
cat(i, "\n")
for(j in seq_along(fn)){
cat(fn[i], fn[j], "\n")
}
}## 1
## 사과 사과
## 사과 배
## 사과 딸기
## 사과 포도
## 2
## 배 사과
## 배 배
## 배 딸기
## 배 포도
## 3
## 딸기 사과
## 딸기 배
## 딸기 딸기
## 딸기 포도
## 4
## 포도 사과
## 포도 배
## 포도 딸기
## 포도 포도i인덱스에서 선택한 값이 j인덱스에서 선택한 값과 중복되지 않게 설정하면, 순열을 구하는 코드가 완성된다.
먼저, 중복되지 않도록 i인덱스의 특정 값을 제외하도록 부분선택 한다.
fn <- c("사과", "배", "딸기", "포도")
fn2 <- fn[-1]
fn2## [1] "배" "딸기" "포도"i인덱스에 제외된 벡터를 fn2에 할당한 다음, 이를 j인덱스에 투입하자.
fn <- c("사과", "배", "딸기", "포도")
for(i in seq_along(fn)){
cat(i, "\n")
fn2 <- fn[-i]
for(j in seq_along(fn2)){
cat(fn[i], fn2[j], "\n")
}
}## 1
## 사과 배
## 사과 딸기
## 사과 포도
## 2
## 배 사과
## 배 딸기
## 배 포도
## 3
## 딸기 사과
## 딸기 배
## 딸기 포도
## 4
## 포도 사과
## 포도 배
## 포도 딸기여기에 제시된 개수가 순열에 따른 경우의 수다.
순열의 원리를 파악했으니, 개수를 직관적으로 셀수 있도록 값을 숫자로 바꿔보자.
fn <- 1:4
for(i in seq_along(fn)){
cat(i, "\n")
fn2 <- fn[-i]
for(j in seq_along(fn2)){
cat(fn[i], fn2[j], "\n")
}
}## 1
## 1 2
## 1 3
## 1 4
## 2
## 2 1
## 2 3
## 2 4
## 3
## 3 1
## 3 2
## 3 4
## 4
## 4 1
## 4 2
## 4 3여기서 순열로 4개에서 2개를 뽑는(\(_{4}P_{2}\)) 경우의 수는 4 x 3 = 12라는 것을 알 수 있다.
이중루프를 만들수 있으면 삼중, 사중루프도 가능하다. 4개 중 2개를 뽑는 순열을 구하기 위해 이중루프를 이용했다면, 3개를 뽑는 순열은 삼중루프, 4개를 뽑는 순연을 사중루프를 만들어야 한다.
3개를 뽑는 삼중루프를 만들어보자.
fn <- 1:4
for(i in seq_along(fn)){
cat(i, "\n")
fn2 <- fn[-i]
for(j in seq_along(fn2)){
cat(fn[i], fn2[j], "\n")
fn3 <- fn2[-j]
for(k in seq_along(fn3)){
cat(fn[i], fn2[j], fn3[k], "\n")
}
}
}## 1
## 1 2
## 1 2 3
## 1 2 4
## 1 3
## 1 3 2
## 1 3 4
## 1 4
## 1 4 2
## 1 4 3
## 2
## 2 1
## 2 1 3
## 2 1 4
## 2 3
## 2 3 1
## 2 3 4
## 2 4
## 2 4 1
## 2 4 3
## 3
## 3 1
## 3 1 2
## 3 1 4
## 3 2
## 3 2 1
## 3 2 4
## 3 4
## 3 4 1
## 3 4 2
## 4
## 4 1
## 4 1 2
## 4 1 3
## 4 2
## 4 2 1
## 4 2 3
## 4 3
## 4 3 1
## 4 3 2여기서 순열로 4개에서 3개를 뽑는(\(_{4}P_{3}\)) 경우의 수는 4 x 3 x 2 = 24라는 것을 알 수 있다.
순열과 팩토리얼의 유사점을 찾을 수 있다.
- \(_{4}P_{2}\) = 4 x 3
- \(_{4}P_{3}\) = 4 x 3 x 2
- 4\(!\) = 4 x 3 x 2 x 1
연속하는 4개의 숫자(4,3,2,1) 중 2개(4,3)까지 곱하는 것은 4\(!\)(4 x 3 x 2 x 1)을 4-2 = 2의 2\(!\)(2 x 1)로 나누는 것과 같다(4\(!\) / (4-2)\(!\)).
4*3 == 4*3*2*1 / 2*1## [1] TRUE이를 공식으로 표현하면 다음과 같다.
\[ _{n}P_{k} = \frac{n!}{(n-k)!}\] 공식이 있으면 알고리듬으로 사용자함수에 구현할 수 있다.
perm_f <- function(n, k){
output <- fact_f(n) / fact_f(n-k)
return(output)
}
perm_f(4,3)## [1] 41.5.3 조합
조합(combination)은 순열에서 순서를 고려하지 않은 경우의 수이다. 순서와 관계없이 \(n\)개에서 \(k\)개의 요소를 선택하는 방법이다.
조합은 combination이므로 \(_{n}C_{k}\)로 표현한다. \(n\)개의 대상을 조합해(\(C\)) \(k\)개를 산출하는 경우의 수라는 의미다. “사과, 배, 딸기, 포도” 4개를 조합해 2개를 뽑는 경우의 수(\(_{4}C_{2}\))는 다음과 같이 12개 중 순서만 다르고 내용이 같은 6개경우를 뺀 6이 된다.
("사과", "배")
("사과", "딸기")
("사과", "포도")
x("배", "사과")
("배", "딸기")
("배", "포도")
x("딸기", "사과")
x("딸기", "배")
("딸기", "포도")
x("포도", "사과")
x("포도", "딸기")
x("포도", "배") 순열에서는 중복만 안되게 선택했으므로 한번 선택됐더라도 다음 루프에서 다시 선택되지만, 조합에서는 한번 선택되면 그 다음에는 선택되지 않도록 해야 한다.
fn <- c("사과", "배", "딸기", "포도")
for(i in seq_along(fn)){
cat(i, "\n")
fn2 <- fn[-i]
for(j in seq_along(fn2)){
cat(fn[i], fn2[j], "\n")
}
fn <- fn2 # 선택된 항목 제외된 결과
fn <- c(NA, fn) # 제외된 항목 자리를 NA로 채움.
}## 1
## 사과 배
## 사과 딸기
## 사과 포도
## 2
## 배 NA
## 배 딸기
## 배 포도
## 3
## 딸기 NA
## 딸기 NA
## 딸기 포도
## 4
## 포도 NA
## 포도 NA
## 포도 NA위의 코드에서 fn <- c(NA, fn)을 넣지 않으면 조합 결과가 산출되지 않는다. 이유를 추론해 보자. i인덱스가 투입되는 값을 구체적으로 하나씩 넣어가며 생각해보자.
fn <- c("사과", "배", "딸기", "포도")
for(i in seq_along(fn)){
cat(i, "\n")
fn2 <- fn[-i]
for(j in seq_along(fn2)){
cat(fn[i], fn2[j], "\n")
}
fn <- fn2 # 선택된 항목 제외된 결과
# fn <- c(NA, fn) # 제외된 항목 자리를 NA로 채움.
}## 1
## 사과 배
## 사과 딸기
## 사과 포도
## 2
## 딸기 배
## 딸기 포도
## 3
## NA 배
## NA 포도
## 4
## NA 배
## NA 포도조합은 순열과 달리 배열 순서와 관계없이 포함된 항목의 내용만 같으면 단일 조합으로 계산한다. 따라서 조합을 계산하는 간단한 방법은 순열 \(_{n}P_{k}\)을 \(k!\)로 나누는 것이다. \(n\)개중 \(k\)개를 추출하는 경우, 순서를 고려해 배열하는 방법이 \(k!\)개가 되기 때문이다.
예를 들어, 1과 2 두 숫자를 순서를 고려해 배열하는 방법은 \(2!\)로 (1, 2), (2, 1) 등 총 2가지가 있다. 조합에서는 이 2가지 배열을 모두 같은 경우로 취급한다. 1,2,3 등 세 숫자를 순서를 고려해 배열하면 (1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1) 등 3\(!\)로 총 6가지 경우가 생긴다. 조합에서는 이 6가지 경우가 모두 같은 배열이다.
조합을 공식으로 표현하면 다음과 같다.
\[ _{n}C_{k} = (^{n}_{k}) = \frac{_{n}P_{k}}{k!} = \frac{\frac{n!}{(n-k)!}}{k!}\]
이 공식을 이용해 조합을 구하는 사용자 함수를 만들자.
comb_f <- function(n, k){
output <- fact_f(n) / fact_f(n-k) / fact_f(k)
return(output)
}
comb_f(4, 2)## [1] 1조합을 구하는 R 내장함수는 choose(n, k)다.
choose(4, 2)## [1] 6- 팩토리얼, 순열, 및 조합을 이용한 반복문 학습방법은 <3일만에 끝내는 코딩 통계>(박준석 저, 2021, 사회평론아케데미)을 참조하였다.
1.6 조건(if else)
TRUE와 FALSE 의 논리값을 if()함수에 투입해 실행하는 조건을 구분함으로써 보다 복잡한 작업을 할 수 있다.
먼저 비교연산자를 통해 논리값이 나오는 사례를 살펴보자.
2 == 2## [1] TRUE2 != 2## [1] FALSE3 <= 3## [1] TRUE3 < 3## [1] FALSE7 %% 2 == 0## [1] FALSE복수의 논리값
복수의 논리값을 하나로 처리해야 할때가 있다. 이때 유용한 함수가 all()과 any()다.
all(TRUE, TRUE, TRUE)## [1] TRUEall(TRUE, TRUE, FALSE)## [1] FALSEall(TRUE, FALSE, FALSE)## [1] FALSEall(FALSE, FALSE, FALSE)## [1] FALSEany(TRUE, TRUE, TRUE)## [1] TRUEany(TRUE, TRUE, FALSE)## [1] TRUEany(TRUE, FALSE, FALSE)## [1] TRUEany(FALSE, FALSE, FALSE)## [1] FALSE조건문은 아래의 형식으로 만든다. if() 함수 논리값이 TRUE가 산출되면 { } 안의 실행부에 있는 함수를 실행하고, FALSE가 산출되면 실행하지 않는다.
if(논리값){
실행부
}혹은 아래와 같은 형식으로 만들어 if() 함수 논리값이 TRUE가 산출되면 { } 안의 실행부1을 실행하고, FALSE가 산출되면 else의 실행부2를 실행한다.
if(논리값){
실행부1
} else {
실행부2
}조건을 지정해 사용자함수를 만들어 보자. 투입한 수가 짝수면 “너는 짝수구나!”라고 출력하고, 홀수면 “너는 홀수구나!”를 출력하는 조건문이 포함된 사용자함수다.
oe_f <- function(x) {
if (x %% 2 == 0) {
cat("너는 짝수구나!")
} else {
cat("너는 홀수구나!")
}
}임의의 정수를 만들어, 앞서 만든 함수가 제대로 작동하는지 확인해보자.
임의 값은
runif(n, min, max)로 만든다.
runif(n = 1, min = 10, max = 100)는 10부터 100까지 범위에서 값 1개를 만든다. (‘unif’는 ’uniform distribution’ 의미. 분포는 뒤에서 자세히 다룬다.)정수는
as.integer()함수로 만든다.
random_n <- as.integer(runif(n = 1, min = 10, max = 100))
cat(random_n, "\n") # 생성한 수 화면에 표시## 29oe_f(random_n)## 너는 홀수구나!코딩 스타일
코딩도 일종의 글쓰기이므로, 코딩에도 스타일이 있다. 코딩은 기능적인 글쓰기이므로 실용성과 가독성이 중요하다. 코드를 작성한 다음 나중에 그 코드를 다시 봤을 때 혹은 다른 사람이 그 코드를 봤을 때 직관적으로 잘 이해할 수 있도록 일관적이고도 효율적으로 코드를 작성해야 한다.
널리 사용되는 코딩스타일의 지침은 해들리 위컴의 R스타일 가이드다.
꼭 기억해야 할 코딩스타일은 코딩객체나 함수이름 지정 방법이다.
- 다른 사람 혹은 본인이 나중에 봤을 때 그 의미를 쉽게 파악할 수 있도록 설정.
good: fruit_v
bad: f
- 객체이름의 의미 단위는
_나-로 구분.
good: plots_combined
bad: plotsCombined
- 객체 특성 명기
데이터를 할당한 객체에는 객체의 특성(예: 사용자함수, 데이터구조)을 명기한다. 이 방법이 좋은 이유는 객체의 이름을 다른 중요한 함수 이름과 중복되지 않도록 할수 있기 때문이다.
- 예:
- 벡터: name_v
- 데이터프레임: name_df
- 매트릭스: name_m
- 리스트: name_l
- 사용자 함수: name_f
- 토큰: name_tk
1.7 패키지
패키지(Package)는 R함수, 데이터, 완성된 코드를 정리해 종합한 꾸러미다. install.packages()함수로 컴퓨터에 설치한다. 패키지는 라이브러리(library)라고도 한다. 패키지를 R환경에 올리는 함수가 library()인 이유다.
install.packages("패키지")
library(패키지)library(패키지)를 실행하지 않고, 패키지::함수와 같은 방식을 이용해도 패키지의 함수를 이용할 수 있다. 아래 예문은 library(dplyr)를 실행하지 않고, dplyr패키지의 select()함수를 실행하라는 기술문이다. (인자의 내용은 df데이터프레임에서 colx열을 선택하라는 의미다. 데이터프레임에 대해서는 뒤에서 자세히 다룬다.)
dplyr::select(df, colx)R환경에 올려진 패키지와 버전은 sessionInfo()함수를 이용해 확인할 수 있다. 패키지 버전만 확인하고 싶으면 packageVersion("패키지명")을 이용한다.
R Studio에서 버전을 확인하는 방법은 다음과 같다.
Tools -> Check for Package Updates ...주의!!! 윈도에서 패키지를 설치할 때는 RStudio를 관리자 권한으로 실행해야 제대로 설치된다. 윈도가 보안정책을 강화했기 때문이다.
먼저 install.packages()함수를 이용해 tidyverse 패키지를 설치하고, library()함수를 이용해 현재의 R환경에 올려 패키지를 사용할 수 있도록 하자.
tidyverse는 정돈된 세상(tidy + universe)이란 의미의 종합패키지다. 해들리 위컴(Hadley Wickham)이 “정돈된 데이터 원리(tidy data principle)”에 따라 구성한 세계관이다. 정돈된 세계를 통해 R은 한층 뛰어난 프로그래밍 언어가 됐다. “정돈된 세계(tidyverse)”안에서는 코딩작업을 직관적이고도 일관성있게 할 수 있다. (tidy를 직역하면 “깔끔한”이지만, tidyverse의 취지에 맞게 tidy를 “정돈된”으로 번역한다.)
tidyverse에 대해 조금 더 알고 싶으면 한국통계학회 소식지 2019년 10월호에 실린 "데이터사이언스 운영체계tidyverse문서 참조.tidyverse패키지를 설치하면ggplot2(시각화),dplyr(자료 조작),purrr(함수형프로그래밍),stringr(문자형 조작),forcat(요인(factor)자료 조작) 등 다수의 유용한 패키지가 함께 설치된다.
패키지를 install.packages()로 설치할 때는 패키지 이름에 " "를 하고, library()에서는 " "가 없는 점에 주의하자.
install.packages("tidyverse")
library(tidyverse)require()도 패키지를 R환경에 올리는 함수이나 library()와는 달리, TRUE와 FALSE값을 산출한다. if()함수를 이용한 조건문에서 사용할 수 있다.
require(tidyverse)if()와 !등 조건문과 논리함수를 사용하면 보다 효율적으로 코딩할 수 있다. 패키지가 이미 설치돼 있는 경우 설치작업을 반복하지 않을 수 있기 때문이다.
if()는TRUE와FALSE등 논리값에 따라 실행조건을 부여하는 조건 함수다.if()의 값이TRUE면 함수를 실행하고,FALSE면 함수를 실행하지 않는다.!는not이라는 의미다. 예를 들어,==은 “같다(equal)”는 의미인데, ,!=는 “같지 않다(not equal)”의 의미가 된다.
아래 if() 조건문은 다음의 의미다. (조건문이 한줄일때는 { }이 없어도 된다.)
if(!require(tidyverse)) install.packages("tidyverse")tidyverse가 설치돼 있지 않은 경우,if(!require(tidyverse))는Not FALSE이므로TRUE가 전달돼install.packages("tidyverse")를 실행하게 된다.tidyverse가 설치돼 있는 경우,if(!require(tidyverse))는Not TRUE이므로FALSE가 전달돼install.packages("tidyverse")를 실행하지 않게 된다.
tidyverse를 R환경에 탑재하자.
library(tidyverse)## -- Attaching packages --------------------------------------- tidyverse 1.3.1 --## v ggplot2 3.3.5 v purrr 0.3.4
## v tibble 3.1.6 v dplyr 1.0.8
## v tidyr 1.2.0 v stringr 1.4.0
## v readr 2.1.2 v forcats 0.5.1## -- Conflicts ------------------------------------------ tidyverse_conflicts() --
## x dplyr::filter() masks stats::filter()
## x dplyr::lag() masks stats::lag()tidyverse패키지를 탑재하면 -- Attaching packages --라는 메시지가 뜨며 아래 8종의 패키지 목록이 보인다. 이 8종의 패키지는 library(tidyverse)를 통해 tidyverse패키지를 현재의 R환경에 올리면 함께 R환경에 올라가는 부착된 패키지다. 즉, 아래 8개 패키지를 library()로 개별적으로 올리지 않아도 R환경에서 사용할 수있다.
ggplot2시각화 도구모음. 그래픽의 문법에 기초dplyr데이터 조작. 일종의 공구상자tidyr데이터 정돈. 데이터를 정돈하는 함수 제공readr데이터 이입. 행과 열이 있는 데이터(예: csv, tsv, fwf) 이입(import)purr함수형프로그래밍(functional programming) 도구모음tibble데이터프레임의 현대적 양식sringr문자형 데이터(string) 작업 도구 모음forcats데이터유형(type)이 요인(factor)일때 발생하는 문제해결 도구모음.
아래의 패키지는 tidyverse와 함께 설치되지만 library(패키지명)로 따로 R환경에 올려야 사용할 수 있는 패키지다.
hmshousr와 time 데이터 처리 도구 모음lubridatedate와 times 데이터 처리 도구 모음httr웹 APIrvest웹 스크레핑readxlxls ghrdms xlsx 파일 이입havenSPSS, SAS, STATA 파일 이입jasonliteJSONxml2XMLmodelr파이프라인안에서 모델링broom모델을 tidydata로
-- Conflicts --라는 메시지는 tidyverse내 패키지와 다른 패키지의 함수 이름이 충돌해, 다른 패키지의 동명 함수를 덮었다(mask)는 의미다.
여기서는 dplyr::filter()가 stats::filter()를 덮었지만, 반대로 다른 패키지의 함수가 tidyverse패키지 함수를 덮을 수 있다. 예를 들어, select()함수를 다른 패키지에서 덮어쓴 경우, select()함수 용법에 오류가 생길 수 있다. 이런 경우, dplyr::select()처럼 패키지를 명기해서 코딩하여 오류를 회피할 수 있다.
rtools
윈도에서 R의 다양한 패키지를 설치하고 사용하는데 필요한 패키지다. (맥이나 리눅스에서는 설치 불필요.)
CRAN의
rtools페이지에 접속한다.설치된 R버전과 일치하는 버전의
rtools를 다운로드받는다. 예를 들어, R이 4.0대 버전이면rtools40을 설치한다.
rtools는 다른 패키지와 달리install.packages()함수로 설치하지 않고, 설치파일을 컴퓨터에서 직접 실행해 설치한다.
- 설치할때 경로변경하지 말고
C:/Rtools에 설치한다. 설치과정에서Add rtools to system PATH가 체크돼 있는지 확인한다.
1.8 파이프1 %>%
파이프 %>%는 코드를 보다 간결하고 읽기 쉽게 만들수 있는 코딩방식이다. 다음 사례를 보자.
sum(as.integer(runif(5, 1, 10)))이 코드는 다음과 같이 작성할 수도 있다.
random_n <- runif(5, 1, 10)
random_i <- as.integer(random_n)
sum(random_i)파이프를 이용하면 다음과 같이 바꿀 수 있다. 훨씬 간결하고 사고의 흐름과 일치해 코드의 의미가 명확하게 드러난다.
runif(5, 1, 10) %>% as.integer() %>% sum()파이프는 앞의 값을 ’파이핑’해 뒤로 전달해 주는 기능을 하기 때문에, 파이프를 이용하면 사고의 흐름대로 코딩할 있다. 또한 객체를 불필요하게 많이 만드는 일도 피할 수 있다.
%>% 파이프는 magrittr패키지에 포함된 기능인데, tidyverse와 dplyr패키지를 설치해 사용할 수 있다.
단축기는 ctrl키와 m키의 조합이다.
R이 내장함수로 제공하는 파이프는 |>다. %>% 보다 기능이 부족해 여기서는 %>% 파이프를 이용한다.
1.9 오류(error) 다루기
Warning(경고)메시지는 참고만 하고 무시해도 되지만, 오류(error)메시지는 해결해야 다음 단계로 넘어갈 수 있다.
오류가 발생하면 당황하지 말고, 오류메시지를 잘 읽어보자.
흔한 오류는 다음과 같다.
1.9.1 오자와 탈자
가장 흔한 오류의 원인은 오타다.
- 대문자와 소문자를 정확하게 기입했는지 확인. 아래코드를 실행하면
Error in print(number_v) : object 'number_v' not found오류메시지가 나온다. 이유는?
Number_v <- 1:5
print(number_v)할당한 객체의 이름을 대문자로 지어놓고, 호출할때는 소문자를 썼기 때문이다.
- 영어권 사람들은 명사와 동사에
s를 추가하는 경우가 흔하다. 철자에 ’s’가 정확하게 들어 있는지 확인한다.
아래 코드에서 Error in install.package("tidyverse") : could not find function "install.package" 오류가 발생하는 이유는?
install.package("tidyverse")- ’1’과 ’l’의 차이. 사람 눈에는 알파셋 L의 소문자 l과 숫자 1처럼 비슷해 보이는 글자가 있다. 기계에게는 전혀 다른 내용이다.
아래 코드에서 Error: object 'objl' not found" 오류가 발생하는 이유는?
obj1 <- c(1, 2, 3)
objl[1]1.9.3 보이지 않는 코드
PDF문서의 내용을 R스튜디오 편집창에 복사해서 붙일 때 오자나 탈자가 없는데도 코드가 작동하지 않는 경우가 있다. 이런 일이 생기는 이유는 사람의 눈에 동일한 문자라도 기계는 다른 문자코드로 인식할 수 있기 때문이다. PDF문서를 복사해서 편집기에 복사해서 붙이면 사람 눈에 보이지 않는 코드도 함께 복사돼 붙여지는 경우가 있다.
이런 문제가 생기면, Notepad++나 Atom같은 편집기에 해당 코드를 붙여넣었다 다시 복사해서 R스튜디오 편집창에 붙여 넣으면 해결할 수 있다.
1.9.4 패키지 설치시 오류가 뜨면?
패키지설치할 때 가끔 제대로 설치되지 않는 경우도 있고, 오류가 발생하기도 한다. 예를 들어, 아래와 같은 오류가 발생하는 경우가 있다.
library(“tidyverse”) Error: package or namespace load failed for ‘tidyverse’ in loadNamespace(i, c(lib.loc, .libPaths()), versionCheck = vI[[i]]): namespace ‘scales’ 0.4.0 is already loaded, but >= 0.4.1 is required
내용을 해석하면 tidyverse패키지와 함께 설치되는 패키지가 의존하는 scale패키지가 컴퓨터에서 업데이트돼 있지 않아 오류가 발생했다는 의미다.
만일, 패키지를 설치하려는데 설치가 제대로 진행되지 않거나, 설치한것 같은데도 패키지가 작동하지 않는다면 아래의 방법을 시도해본다.
1. RStudio를 관리자 권한으로 실행
2. 해당 패키지 새로 설치 또는 업데이트
해당 패키지(위의 경우 scale)를 새로 설치하거나 업데이트한다.
새로 설치할 때는 dependencies=TRUE를 명령어에 추가해 모든 의존 패키지도 설치하도록 하자.
install.packages("패키지명", dependencies=TRUE)패키지 업데이트를 해보는 방법도 있다.
update.packages("패키지명")3. RGui의 콘솔에서 실행
RStudio에서 패키지 설치할 때 아래와 같은 메시지가 나오며 진행이 안되는 경우가 있다 (Figure 1.22).
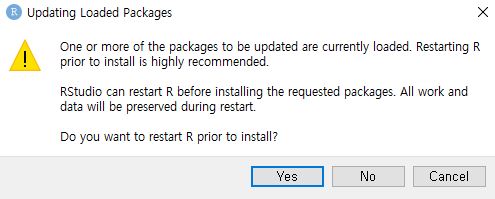
Figure 1.22: RStudio 패키지 설치 오류
Yes를 선택하고 진행하도 설치가 안되는 경우, Cancel한 후 패키지를 RGui의 콘솔에서 설치해본다. 이때 R을 관리자권한으로 실행한다.
4. 패키지 폴더 삭제 후 재설치
패키지를 새로 설치해도 Warning: cannot remove prior installation of package ‘패키지이름’과 같은 오류메시지가 나오며 해결이 안되는 경우가 있다.
패키지가 설치돼 있는 하드디스크폴더에서 해당 패키지 폴더를 삭제하고 다시 설치한다.
패키지가 설치된 위치는 다음과 같다. .libPaths()함수를 통해 확인할 수 있다.
패키지가 설치되는 위치는 RStudio를 관리자 권한으로 실행하는 경우 C:/Program Files/R/[R버전]/library다.
관리자권한으로 실행하지 않으면 아래의 경우처럼 문서폴더에 패키지가 설치된다.
내 PC > 문서 > R > win-library
또는
C:\Users\[윈도사용자]\Documents\R\win-library
예를 들어:
C:\Users\myPC\Documents\R\win-library패키지 설치위치는 .libPaths("폴더명")함수로 패키지 설치위치를 바꿀 수 있다.
예를 들어, C드라이브의 library폴더를 만들어 .libPaths("c:/library")를 입력하면 패키지 설치 경로가 변경된다.
5. RRui 삭제하고 다시 설치
위의 모든 방법을 동원해도 안될때가 있다. RRui를 삭제하고 다시 설치한다. 이때 패키지가 설치돼 있는 폴더도 삭제한다.
1.9.5 실행할 때 겪을 수 있는 오류
다음과 같은 에러메시지가 뜨는 경우가 있다. 메시지의 내용을 잘 읽어보자.
Error in tibble(text = text_vword) %>% unnest_tokens(output = word, input = text) :
함수 "%>%"를 찾을 수 없습니다실행하는데 필요한 함수 %>%를 찾을 수 없다는 의미다. %>%는 파이핑에 필요한 함수로서 dplyr에서 magrittr패키지를 통해 제공한다. dplyr는 tidyverse를 올리면 함께 부착된다.
따라서 아래 3가지 중 하나만 하면 해결할 수 있다.
library(tidyverse)
또는
library(dplyr)
또는
library(magrittr)마찬가지로 아래와 같은 에러메시지가 뜨면 어떻게 해야할까?
Error in unnest_tokens(., output = word, input = text) :
함수 "unnest_tokens"를 찾을 수 없습니다 오류메시지의 내용을 보니, unnest_tokens함수가 없다고 한다. unnest_tokens가 어디에 속해 있는 함수인지 검색해보자. tidytext패키지의 함수란 정보를 어렵지 않게 찾을 수 있다. 따라서 unnest_tokens함수를 제공하는 패키지 tidytext를 실행한다. 설치가 안돼 있으면 설치부터 한다.
if(!require(tidytext)) install.packages("tidytext")
library(tidytext)- 기타 패키지 설치 관련 정보는 이 문서 참조
1.9.6 글자가 깨지는 경우
글자가 깨지는 원인은 다양하다.
먼저, RStudio에서 인코딩이 정확하게 설정됐는지 확인한다. 그 다음에 함수에서 인코딩을 인자로 투입해야 하는지 함수의 용법을 확인해 본다.
그리고, 로케일을 확인해본다. 운영체제 로케일(locale)이 맞지 않아 문자가 깨지는 경우가 있다. 언어마다 문자를 표시하는 방식이 언어별로 각기 다른 로케일이 설정돼 있다.
로케일 설정 바꾸는 방법은 다음과 같다.
Sys.getlocale()함수로 로케일 설정 정보 확인후 텍스트로 복사해 메모장 등에 붙여 둔다.만일
Sys.getlocale()결과가LC_COLLATE=Korean_Korea.949로 나오지 않는다면 아래와 같이 설정해 테스트해 본다.
Sys.setlocale('LC_ALL', 'korean')
data.frame(test = c("하나","둘","셋"))로케일과 인코딩에 대해 다음 문서 참고
1.10 파일과 폴더
1.10.1 파일경로(path) 표시
1.10.1.1 슬래시 /
윈도에서는 경로를 표시할 때 역슬래시\를 사용하지만, R환경에서는 슬래시/를 이용해 경로를 표시한다. \\처럼 역슬래시를 두번 쓰기도 한다.
파일 위치를 지정할 때 /만 쓰거나 첫번째로 적는 /는 루트디렉토리를 의미한다.
list.files("/") # 루트디렉토리에 있는 모든 파일과 폴더 표시
list.files("/data") # 루트디렉토리 아래의 data폴더에 있는 모든 파일과 폴더 표시
list.files("data") # 현재 작업디렉토리 아래의 data폴더에 있는 모든 파일과 폴더 표시주의
list.files("data\images")를 실행하면 아래와 같은 오류가 발생한다. 이유는?
> list.files("data\images")
에러: ""C:\U"로 시작하는 문자열들 가운데 16진수가 아닌 "\U"가 사용되었습니다윈도에서 사용하는 경로표시 \를 R환경에서 사용했기 때문이다. \를 /로 수정한다.
1.10.1.2 마침표 . ..
파일위치를 지정할 때 마침표의 수에 따라 의미가 다르다.
- 마침표 하나
.: 현재 작업디렉토리 - 마침표 둘
..: 현재 작업디렉토리 바로 한단계 위에 있는 폴더
list.files(".") # 작업디렉토리에 있는 모든 파일과 폴더 표시
list.files("./images") # 작업디렉토리아래에 있는 images폴더에 있는 모든 파일과 폴더 표시. list.files("./images")의 산출결과는 list.files("images")와 같다. ./images와 images는 둘다 현재 작업디렉토리 아래에 있는 images란 의미.
list.files("..") # 작업디렉토리 위 폴더에 있는 모든 파일과 폴더 표시
list.files("../dir") # 작업디렉토의 위 폴더 아래(즉, 현 작업디렉토리와 같은 단계의 위치에 있는 폴더) 아래에 있는 images폴더에 있는 모든 파일과 폴더 표시1.10.1.3 물결 ~
파일위치를 지정할 때 물결표시~는 홈디렉토리를 의미한다. 홈디렉토리는 로그인 사용자가 사용할 수 있는 최상위 디렉토리다.
윈도의 경우에서 만일 사용자 ID를 user1이라고 한 경우 C:/Users/user1/Documents폴더가 홈디렉토리가 된다. (윈도환경에서는 경로를 역슬래시를 사용하므로 C:\Users\user1\Documents로 표시된다.)
따라서 list.files("~")과 list.files("C:/Users/user1/Documents")는 같은 결과 산출.
list.files("~") #홈디렉토리에 있는 모든 파일 표시
list.files("~/R/win-library") #홈디렉토리 아래단계에 있는 R/win-library폴더의 모든 파일과 폴더 표시 1.10.2 파일과 객체
1.10.2.1 하드디스크에 있는 파일을 다루는 함수
dir.create("C:/newdir") # 디렉토리(폴더) 생성
list.files() # 현재 작업디렉토리 파일과 폴더 목록1.10.2.2 R환경내 객체를 다루는 함수
ls() # 현재 작업공간에 있는 객체 목록
rm(객체명) # 작업공간의 객체 제거. 필요없는 객체 제거에 사용. getwd() # 작업디렉토리(working directory) 표시
setwd("C:/newdir") # "C:/newdir"을 작업디록토리 설정단일 R객체를 파일로 저장하고 가져오는 방법
saveRDS(name_df, file = "name_df.rds")
name_df <-readRDS("name_df.rds")복수의 R객체를 파일로 저장하고 가져오는 방법
save(n1_df, n2_df, file = "name.RData") # n1_df과 n2_df객체를 작업디렉토리에 name.RData란 이름의 파일로 저장
load("name.RData") # name.RData를 작업공간에 탑재R환경의 모든 객체를 이미지로 저장하고 가져오는 방법.
save.images("myData.RData") # 작업공간을 이미지파일로 저장. 파일명 지정하지 않으면 .RData로 저장.
load("myData.RData") # 작업디렉토리 파일을 현 작업공간에 객체로 탑재fst패키지를 이용하면 대용량 파일을 빠르게 처리할 수있다.
write.fst(df, "dataset.fst") # 데이터프레임 저장
df <- read.fst("dataset.fst") # 데이터프레임으로 불러오기1.10.3 주의: 폴더이름 설정
R작업에 관련된 폴더이름은 모두 영문으로 지정한다. 한글명 폴더를 이용할 경우 오류발생하는 경우가 드물지 않다.
폴더명을 지정할 때 띄어쓰기를 하지않는다. 오류의 원인이다. 데이터분석 작업을 하는 폴더의 이름은 모두 영문으로 붙여쓴다.
R스튜디오는 작업디렉토리 기본설정이 홈디렉토리(~)로 돼 있다. 만일 윈도나 맥 등 운영체제에서 한글을 사용자명으로 지정했을 꼉우, 경로에 한글폴더가 포함된다. 대부분 문제없지만, 간혹 오류 발생의 원인이 된다.
작업디렉토리 기본값을 루트디렉토리 아래 영문폴더(예: C:/data)를 만들어 설정하자.
1.11 종합
1.11.2 프로그래밍
- R, RGui, RStudio
- 소프트웨어
- 알고리듬
- 자료구조
- R은 통계에 특화한 프로그래밍언어. 컴파일이 필요없는 인터프리티드 언어.
- 다양한 연산자 활용.
- 모둘로 %% : 나눗셈 후 남는 값만 취하는 연산.
- 벡터와 부분선택
작업공간과 작업디렉토리
객체, 함수, 인자
- 사용자함수
- 자동화 코딩
- 반복문
- 이중루프
- 조건문
패키지
파이프 코딩
오류 다루기
파일과 폴더 구조 이해
- . .. ~ / 차이 숙지.
- / 루트디렉토리
- . 작업디렉토리
- .. 작업디렉토리 위
- ~ 사용자 최상위 디렉토리
- 코딩스타일
- 가독성
- 적절한 띄어쓰기
- 적절한 객체명 짓기
- 적절한 띄어쓰기
1.11.3 배운 함수 정리
print() # 객체의 내용 화면에 출력
cat() # 객체 내용을 화면에 기능(줄바꿈 등)을 이용해 출력
help() # 도움말
ls() # 작업공간의 객체 목록
rm() # 작업공간의 객체 삭제
getwd() # 작업디렉토리 확인
setwd() # 작업디렉토리 설정
dir.create() # 하드디스크에 폴더 생성
list.files() # 작업디렉토리의 파일과 폴더 목록 표시
install.packages() # 패키지 설치
library() # 패키지 탑재
require() # 패키지 탑재(TRUE, FALSE 논리값 생성)
paste() # 문자 결합 sep = 기본값 " "
paste0() # 문자 결합 sep = 기본값 ""
c() # 벡터 생성
+ # 더하기
- # 빼기
* # 곱하기
/ # 나누기
^ # 제곱
** # 제곱
sqrt() # 제곱근
%/% # 정수 나눗셈(몫만 산출)
%% # 모둘로(modulo)
# 비교연산자
==
!=
<=
>=
<
>
sum() # 합
length() # 개수
seq.along() # 값의 개수를 이용해 범위 산출. 기본값 11.12 연습
1. 오류수정
가. 아래 코드는 작동하지 않는다. 올바로 실행되도록 수정하시오.
x <- sum(c(10, 20, 30)
y <- longth(x)
paste(x, Y, sop = "과 ")나. 아래 코드는 작동하지 않는다. 올바로 실행되도록 수정하시오.
des_f <- funtion(x){
out_s <- sum(x)
out_n <- length(x)
output <- c(out_s, out-n)
return(output)
}
des.f(1:5)2. 사용자함수
- 37, 41, 53 이뤄진 숫자벡터를 만들어
number_v에 할당하시오.
- 평균을 구하는 함수를 만들어
mean_f에 할당하시오.
(평균은 합을 개수로 나누는 공식으로 구할 수 있다.)
\[평균(M) = 합(S) / 개수(N) \]
number_v의 평균을mean_f()함수로 계산하시오.
3. 작업디렉토리
C드라이브의 data폴더를 작업디렉토리로 설정하시오.
C드라이브에 newdir이란 폴더를 생성하고, 이 폴더를 작업디렉토리로 설정하시오. 설정된 작업디렉토리를 확인하시오.
4. 데이터구조
ABC제약은 감기몸살에 좋다는 영양제X를 새로 만들기 위해 영양제X의 효과를 확인하기 위해 영양제X의 복용량과 감기몸살의 회복기간의 관계를 파악하려고 한다. 이를 위해 2000명을 대상으로 영양제X의 복용량과 감기몸살 회복기간에 대한 자료를 수집했다.
ABC제약이 수집한 데이터셋의 데이터구조는 무엇이어야 할까?
5. 반복문
가. 2부터 9까지 정수가 임의로 생성되도록 한 다음, 생성된 수에 맞춰 구구단을 하는 반복문을 for()를 이용해 만드시오. cat()를 이용해 계산결과가 아래와 같이 화면에 출력하도록 코딩.
7 x 1 = 7
7 x 2 = 14
7 x 3 = 21
7 x 4 = 28
7 x 5 = 35
7 x 6 = 42
7 x 7 = 49
7 x 8 = 56
7 x 9 = 63 - 힌트: 아래의 과정을 코딩한다.
x <- 7
output1 <- x * 1
output2 <- x * 2
output3 <- x * 3
output4 <- x * 4
output5 <- x * 5
output6 <- x * 6
output7 <- x * 7
output8 <- x * 8
output9 <- x * 9나. 숫자를 투입하면 구구단 결과를 제시하는 사용자 함수를 만들어, 아래와 같이 73의 구구단 결과를 표시하시오.
73 x 1 = 73
73 x 2 = 146
73 x 3 = 219
73 x 4 = 292
73 x 5 = 365
73 x 6 = 438
73 x 7 = 511
73 x 8 = 584
73 x 9 = 657