2 측정
c(
"rio", "janitor",
"tidyverse", "tidytable", "gt",
"r2symbols", "equatiomatic"
) -> pkg_v
pkg_v %in% installed.packages()[,"Package"] -> pkg_installed
(pkg_v[!pkg_installed] -> pkg_new)
if(length(pkg_new)) install.packages(pkg_new)
sapply(pkg_v, library, ch = T)2.1 부분과 맥락
아래 체커에 비친 그림자를 보자 (Figure 2.1). 시지각(vision perception) 전문가인 MIT의 Edward Adelson 교수가 1995년에 소개한 동색착시(same color illusion) 착시다.
A네모와 B네모의 색은 같은 색일까, 다른 색일까? 우리 눈에는 명백하게 다른 색으로 보인다.

Figure 2.1: 사각형 A와 B는 같을 색일까?
눈으로 보이는 것과 달리 A와 B는 같은 색이다. 아래 그림처럼 맥락을 조금 바꿔보면 두 네모의 색이 같게 보인다 (Figure 2.2).

Figure 2.2: 사각형 A와 B는 같을 색이다?
맥락에 의한 착시는 통계에도 적용된다. 평균과 표준편차 등 숫자로 기술한 통계치는 같아 보여도 전체 맥락을 함께 보면 전혀 다른 대상임이 드러나는 경우가 있다. 이를 시각화를 통해 살펴보자.
2.2 시각화
시각화는 자료와 정보의 시각적 표현이다. 자료-정보-지식-지혜(DIKW: Data-Information-Knowledge-Wisdom) 위계론에 따르면, 자료(data)는 현상의 관측으로서 수집과 정체과정(1차 부호화)을 통해 생성하고, 정보(information)는 자료(data)를 분석해(즉, 2차 부호화) 생성한다. 시각화라 하더라고 자료시각화(data visualization)와 정보시각화(information visualization)은 기능과 목표에 차이가 있다.
자료시각화: 시각화에 투입하는 요소(자료) 강조. 자료분석의 한 방법. 자료를 시각적으로 분석해 정보구성. 시각적 자료분석.
정보시각화: 시각화로 산출하는 요소(정보) 강조. 정보 해석의 한 방법. 정보를 시각적으로 해석해 지식구성. 정보를 생성한다는 의미로 본다면 자료시각화와 동의어로서 분석단계에 해당한다. 그러나, 정보시각화를 시각적인 정보해석으로 본다면 소통에 해당한다.
탐색적 단계에서 자료의 특성을 파악하기 위해 시각화한다면 자료시각화에 해당하고, 분석을 마친 다음 분석결과를 소통하기 위해 시각화 한다면 정보시각화에 해당한다.
2.2.1 시각화를 하는 이유
백문(百聞)이 불여일견(不如一見)이기 때문이다. 시각화함으로써 숫자만으로는 드러나지 않는 내용을 파악할 수 있다. 좋은 사례가 통계학자 Francis Anscombe(1918-2001)가 구성한 ’안스콤의 4개조(Anscombe’s Quartet)’다. 데이터셋은 R의 내장자료 anscombe로 제공된다. str()함수로 살펴보자. 11행 8열로 이뤄진 데이터프레임이다.
str(anscombe)## 'data.frame': 11 obs. of 8 variables:
## $ x1: num 10 8 13 9 11 14 6 4 12 7 ...
## $ x2: num 10 8 13 9 11 14 6 4 12 7 ...
## $ x3: num 10 8 13 9 11 14 6 4 12 7 ...
## $ x4: num 8 8 8 8 8 8 8 19 8 8 ...
## $ y1: num 8.04 6.95 7.58 8.81 8.33 ...
## $ y2: num 9.14 8.14 8.74 8.77 9.26 8.1 6.13 3.1 9.13 7.26 ...
## $ y3: num 7.46 6.77 12.74 7.11 7.81 ...
## $ y4: num 6.58 5.76 7.71 8.84 8.47 7.04 5.25 12.5 5.56 7.91 ...head(anscombe, 3)## x1 x2 x3 x4 y1 y2 y3 y4
## 1 10 10 10 8 8.04 9.14 7.46 6.58
## 2 8 8 8 8 6.95 8.14 6.77 5.76
## 3 13 13 13 8 7.58 8.74 12.74 7.71각 열의 평균(mean)과 표준편차(sd: standard deviation)를 구해보자.
mean(anscombe$x1)
mean(anscombe$x2)
mean(anscombe$x3)
mean(anscombe$x4)
mean(anscombe$y1)
mean(anscombe$y2)
mean(anscombe$y3)
mean(anscombe$y4)
sd(anscombe$x1)
sd(anscombe$x2)
sd(anscombe$x3)
sd(anscombe$x4)
sd(anscombe$y1)
sd(anscombe$y2)
sd(anscombe$y3)
sd(anscombe$y4)비슷한 내용이 반복됐으니 반복문으로 간략화해보자. 반복문은 for() 뿐 아니라 apply()함수도 이용할 수 있다.
apply()함수를 이용해 mean()과 sd()함수가 반복(iteration)작업을 하도록 하면, 같은 함수를 반복해서 쓸 필요없이 한번에 계산하도록 할 수 있다.
apply(), lapply(), sapply()처럼 함수가 다른 함수를 실행대상으로 설정하는 작업을 함수형프로그래밍(functional programming)이라고 한다. apply()의 용법은 다음과 같다.
apply(X, MARGIN, FUN, ...)
- X : 함수로 실행할 대상. 매트릭스 등 행열자료구조.
- MARGIN : 함수의 적용 방향. 값이 1이면 행(row)방향, 2는 열(column)방향으로 계산.
- FUN : 투입한 X인자의 각 요소에 대해 실행할 함수.
- … : 추가로 사용할 수 인자가 많이 있다는 의미다.
아래 코드는 ’anscombe’데이터프레임에 대하여 각 열에 대하여 열방향(2)으로 투입한 함수(여기서는 mean()과 sd())를 적용(apply)해 반복적으로 mean()과 sd()함수를 실행하라는 의미다.
apply(anscombe, 2, mean) # 각 열의 평균 계산## x1 x2 x3 x4 y1 y2 y3 y4
## 9.000000 9.000000 9.000000 9.000000 7.500909 7.500909 7.500000 7.500909apply(anscombe, 2, sd) # 각 열의 표준편차 계산## x1 x2 x3 x4 y1 y2 y3 y4
## 3.316625 3.316625 3.316625 3.316625 2.031568 2.031657 2.030424 2.030579계산 결과를 살펴보자. x1열부터 x4열까지 그리고 y1열부터 y4열까지 평균값이 같다. 표준편차도 마찬가지다.
x1열부터 x4열까지 그리고 y1열부터 y4열 사이의 각각에 대한 상관계수도 모두 같다. x열과 y열의 4개 쌍을 cor()함수로 계산한 피어슨 상관관계 계수(coefficient) \(r\)은 모두 0.82다.
options(digits = 2) # 숫자를 두자리만 표시
cor(anscombe$x1, anscombe$y1)## [1] 0.82cor(anscombe$x2, anscombe$y2)## [1] 0.82cor(anscombe$x3, anscombe$y3)## [1] 0.82cor(anscombe$x4, anscombe$y4)## [1] 0.82상관관계(correlation)는 두 변수가 서로 관련돼 있는 정도다. 상관관계의 정도는 상관계수로 나타낸다. 상관관계의 범위는 -1에서 1까지이다. 상관계수가 -1 혹은 1이면 상관성이 완전한 관계이고, 0이면 상관성이 없다. 상관계수가 0.8이면 상당히 높은 수준의 상관성을 나타낸다. 0.2는 낮은 수준의 상관성.
원칙적으로 명목척도와 서열척도는 불연속변수이고, 등간척도와 비율척도는 연속변수이나, 자료를 분석할 때 서열척도를 종종 연속변수로 취급하기도 한다. 예를 들어, 소득수준은 서열변수인데도 등간을 전제로 한 분석도구(예: 피어슨)를 이용하는 경우가 있다. 서열변수에는 서열분석도구(예: 스피어만이나 켄달)을 투입하는 것이 원칙이다.
이번에도 cor()함수를 네번이나 반복했으므로, 이를 프로그래밍으로 자동화할 수 있다. 이번에는 for 루프(loop: 반복문)를 이용해 반복작업을 자동화해보자.
cor_l <- list() # 컨테이너(output)
for(i in 1:4){ # 카운터와 범위
cor_l[i] <- cor(anscombe[i], anscombe[i+4]) # 실행부
}
cor_l## [[1]]
## [1] 0.82
##
## [[2]]
## [1] 0.82
##
## [[3]]
## [1] 0.82
##
## [[4]]
## [1] 0.82위의 코드에서 { }안의 실행부를 풀어서 표시하면 아래와 같다.
cor_l[1] <- cor(anscombe[1], anscombe[1+4])
cor_l[2] <- cor(anscombe[2], anscombe[2+4])
cor_l[3] <- cor(anscombe[3], anscombe[3+4])
cor_l[4] <- cor(anscombe[4], anscombe[4+4])이런 식으로 순차적으로 { }안의 함수를 실행하면, 이 과정을 통해 미리 만들어 둔 컨테이너에 순차적으로 값이 쌓이게 된다. 여기서는 빈 객체를 리스트로 만들었기 때문에, 생성된 객체는 리스트다.( 반복문에 대해 보다 자세한 내용은 R2DS의 반복문 편 참고.)
)
평균, 표준편차, 및 각 상관계수는 모두 같은 값이지만, x열과 y열의 4개 쌍의 관계를 시각화하면 각 쌍의 상관관계는 전혀 다른 모습으로 나타난다. plot()함수로 1번째행(x1)과 5번째행(y1), 2번째행(x2)과 6번째행(y2), 3번째행(x3)과 7번째행(y3), 4번째행(x4)과 8번째행(y4)의 관계를 산점도로 그려보자.
par(mfrow = c(2,2)) # 4개의 도표를 2행 2열로 배열.
plot(anscombe[,1], anscombe[,5],
main = paste("Quartet", 1, sep = " "),
xlab = colnames(anscombe)[1],
ylab = colnames(anscombe)[5],
pch = 16, cex = 2, col = "blue")
plot(anscombe[,2], anscombe[,6],
main = paste("Quartet", 2, sep = " "),
xlab = colnames(anscombe)[1],
ylab = colnames(anscombe)[5],
pch = 16, cex = 2, col = "blue")
plot(anscombe[,3], anscombe[,7],
main = paste("Quartet", 3, sep = " "),
xlab = colnames(anscombe)[1],
ylab = colnames(anscombe)[5],
pch = 16, cex = 2, col = "blue")
plot(anscombe[,4], anscombe[,8],
main = paste("Quartet", 4, sep = " "),
xlab = colnames(anscombe)[1],
ylab = colnames(anscombe)[5],
pch = 16, cex = 2, col = "blue")par(mfrow = c(2,2))에서 par()함수는 도표 표시하는 방식을 지정한다. mfrow인자는 행과 열의 갯수다. mfrow = c(2,2)는 “2행 2열”이란 의미가 된다. “3행 4열”로 지정하면 par(mfrow = c(3,4))이 된다.
R에서 기본함수로 제공하는 시각화 도구는 plot(x, y, ...)함수다. x축의 값과 Y축의 값을 투입해 산점도를 표시한다. 산점도 모양은 다양한 인자를 이용해 설정한다.
- pch : 점 모양.
pch = 16은 꽉찬 원. R에서 사용하는 점의 모양은 다음과 같다.
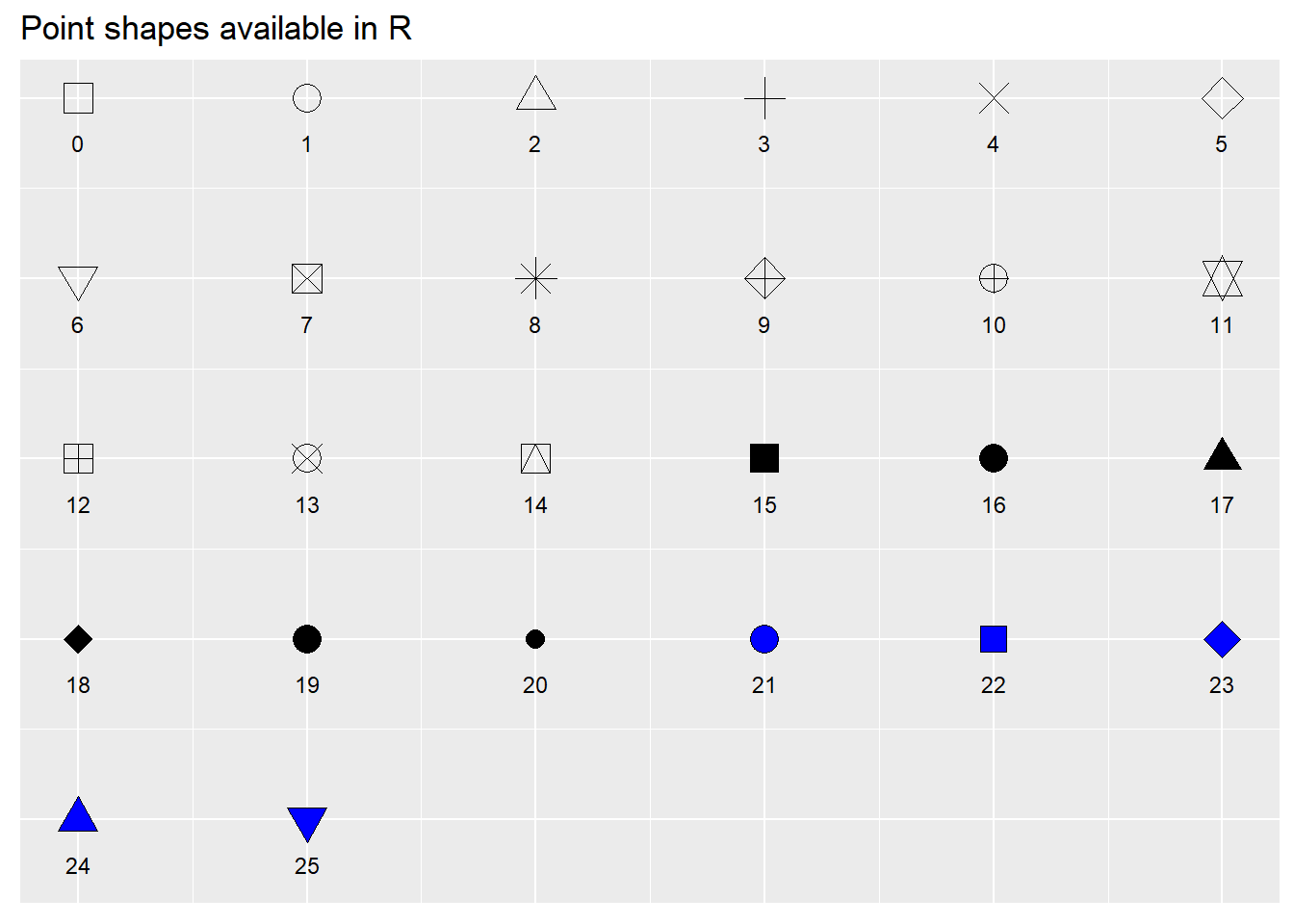
cex : 크기.
cex = 2는 기본값의 2배.col : 색. 색의 용법은 w3school의 Colors Tutorial 참조.
같은 코드를 반복해서 작성했으므로 반복문으로 4번 반복해서 쓴 plot() 함수 작업을 자동화해 보자. (도표를 표시하기 때문에 컨테이너를 만들지 않았다.)
par(mfrow = c(2,2))
for(i in 1:4){
plot(anscombe[ ,i], anscombe[ ,i+4],
main = paste("Quartet", i, sep = " "),
xlab = colnames(anscombe)[i],
ylab = colnames(anscombe)[i+4],
pch = 16, cex = 1.3, col = "blue")
}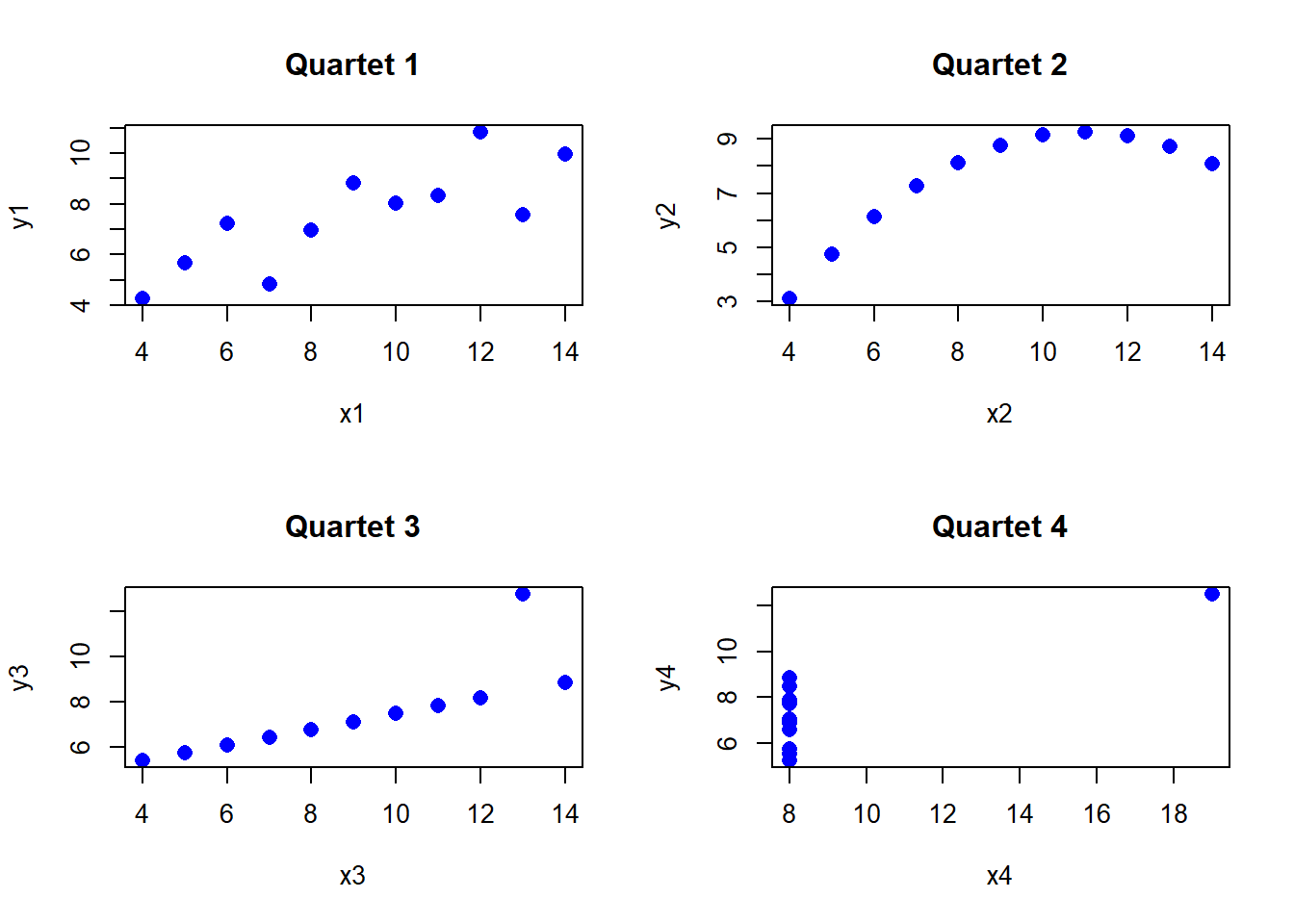
이처럼 시각화를 이용하면 계수로만 파악하기 어려운 관계를 표현할 수 있다. 평균, 표준편차, 상관계수가 모드 같지만, 시각화한 상관관계는 모두 다르다.
2.2.2 ggplot2
현대적인 시각화는 ggplot2패키지가 제공한다. ’gg’는 ’grammar of graphics’로서 ’도표를 작성하는 문법’이라는 의미다. 도표를 일관된 원리에 의해 작성하도록 했기 때문에 붙인 이름이다. ggplot2패키지는 tidyverse패키지의 일부로서 함께 설치되고 함께 탑재된다.
ggplot2패키지로 안스콤 4개조 중 x2와 y2의 관계를 점도표로 표시하면 다음과 같다.
ggplot(data = anscombe) +
geom_point(mapping = aes(x = x2, y = y2))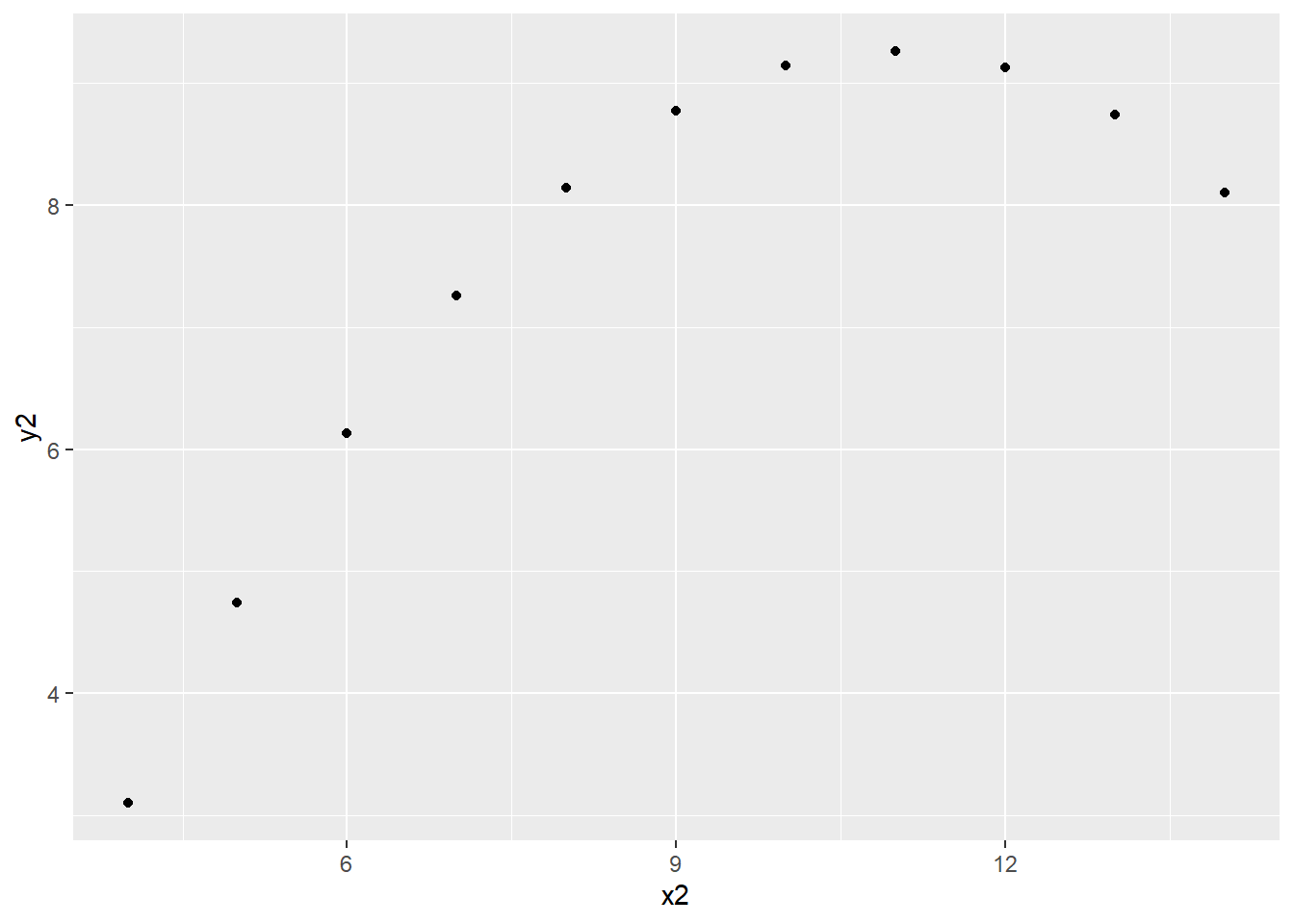
ggplot2패키지는 층(layer)에 층을 겹겹이 쌓아 올리는 식으로 도표를 구성한다. 각 층은 +기호로 연결한다. 이를 체이닝(chaining)이라고 한다. dplyr패키지에서 사용하는 파이프 %>%와 비슷하지만 작동원리는 다르다. 파이프는 앞의 값을 뒤로 전달하는 기능을하는 반면, 체인은 층을 쌓아 올리는 기능을 한다.
즉, 위 코드는 ggplot()함수로 ’anscombe’데이터로 좌표가 있는 층을 만든 다음, 그 위에 geom_point()함수로 x축과 y축에 미적(aes) 기하객체(geom_point: 점)을 배치(mapping)해 만든 층을 추가한 것이라 할 수 있다.
geom_point()라는 함수의 이름은 기하객체(geom)가 점(point)이라는데서 왔다. 이 원리를 적용하면, 기하객체(geom)가 막대인 경우는 geom_col()이나 geom_bar()가 된다. 선인 경우는 geom_line() 혹은 geom_smooth()다. 투입하는 변수의 수, 종류에 따라 매우 다양한 도표를 시각화할 수 있다. (자세한 내용은 ggplot2 설명서를 참고. 요약본도 있다.)
anscombe데이터를 ggplot()함수에 대해 파이핑한 다음, 산점도를 그리고, 그 위에 x2와 y2의 관계를 회귀선으로 표시하면 다음과 같다. method =인자는 x2와 y2의 관계를 계산하는 방식을 지정하는 인자다. lm은 선형모형(linear models)을 계산하는 함수다 (뒤에서 자세히 다룬다).
anscombe %>%
ggplot() +
geom_point(aes(x2, y2)) +
geom_smooth(aes(x2, y2), method = lm)## `geom_smooth()` using formula 'y ~ x'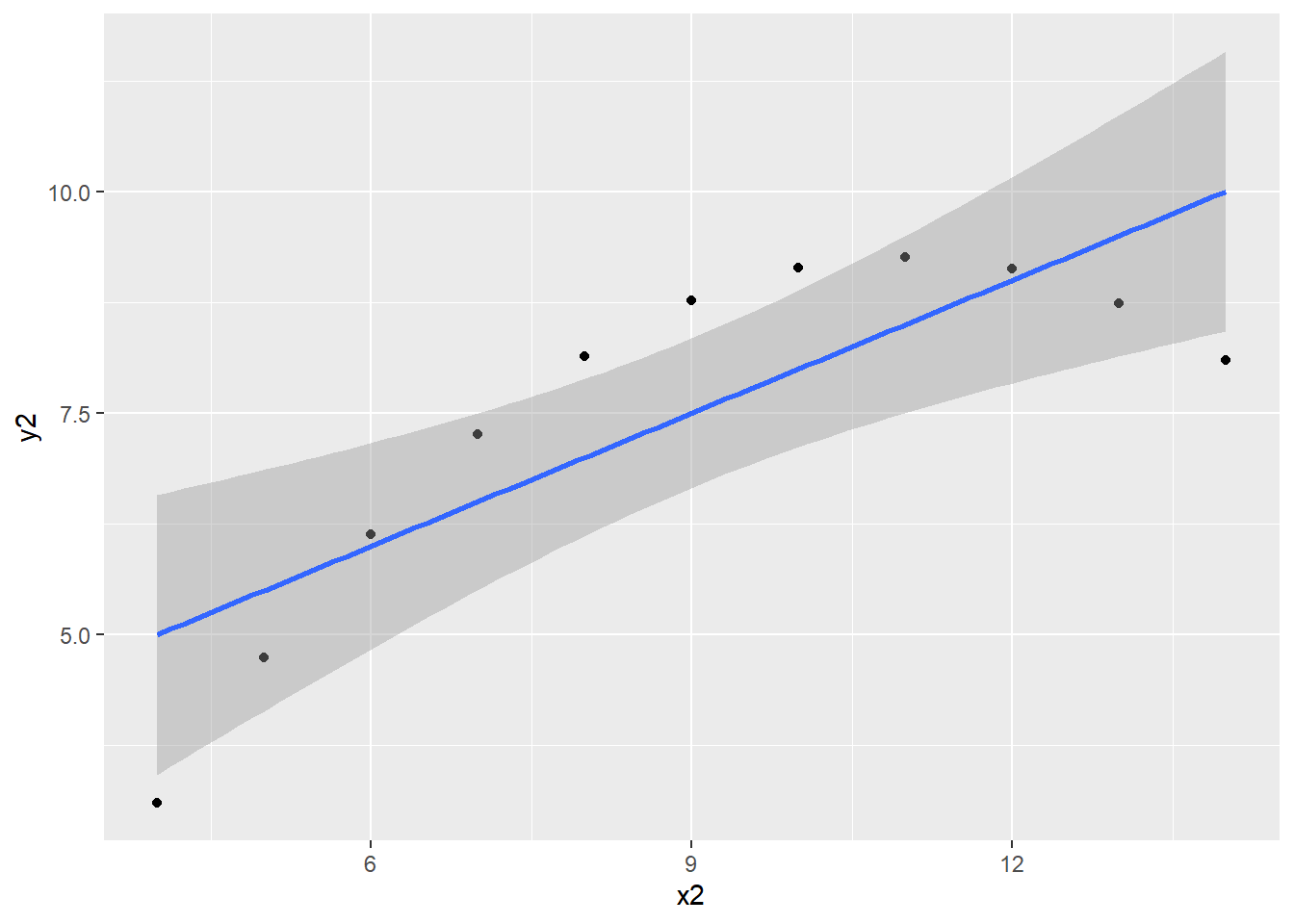
geom_smooth()의 method =인자를 따로 지정하지 않으면 기본값인 loess가 적용된다. loess는 ’LOcally Weighted Scatter-plot Smoother’의 약어로 국소(locally)적으로 가중치를 적용해 비선형 모형을 계산하는 함수다.
anscombe %>%
ggplot() +
geom_point(aes(x2, y2)) +
geom_smooth(aes(x2, y2))## `geom_smooth()` using method = 'loess' and formula 'y ~ x'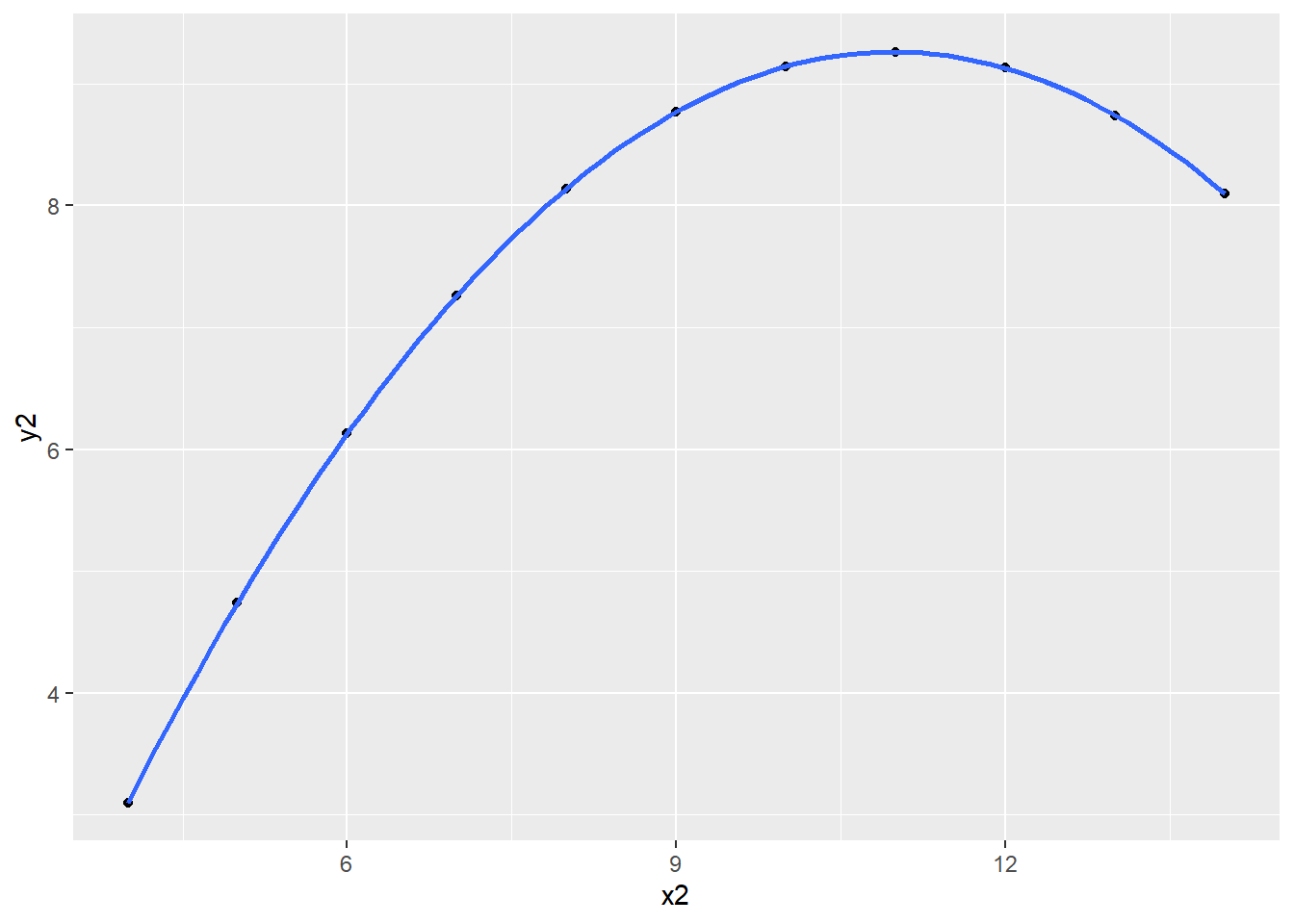
aes()를 geom_...()함수에 반복적으로 투입하지 않고 ggplot()함수에 한번 투입해도 된다.
anscombe %>%
ggplot(aes(x2, y2)) +
geom_point() +
geom_smooth(method = lm)작성한 도표에 labs()함수로 텍스트 층을 추가해 제목, 부제목, 캡션 등을 붙인 다음 theme()함수로 제목의 크기, 색, 위치 등을 지정할 수 있다.
anscombe %>%
ggplot() +
geom_point(aes(x2, y2)) +
geom_smooth(aes(x2, y2), method = lm) +
labs(title = "안스콤의 4개조",
subtitle = "x2와 y2의 관계",
caption = "Source: anscombe") +
theme(plot.title = element_text(size = 20),
plot.subtitle = element_text(color = "purple", size = 15))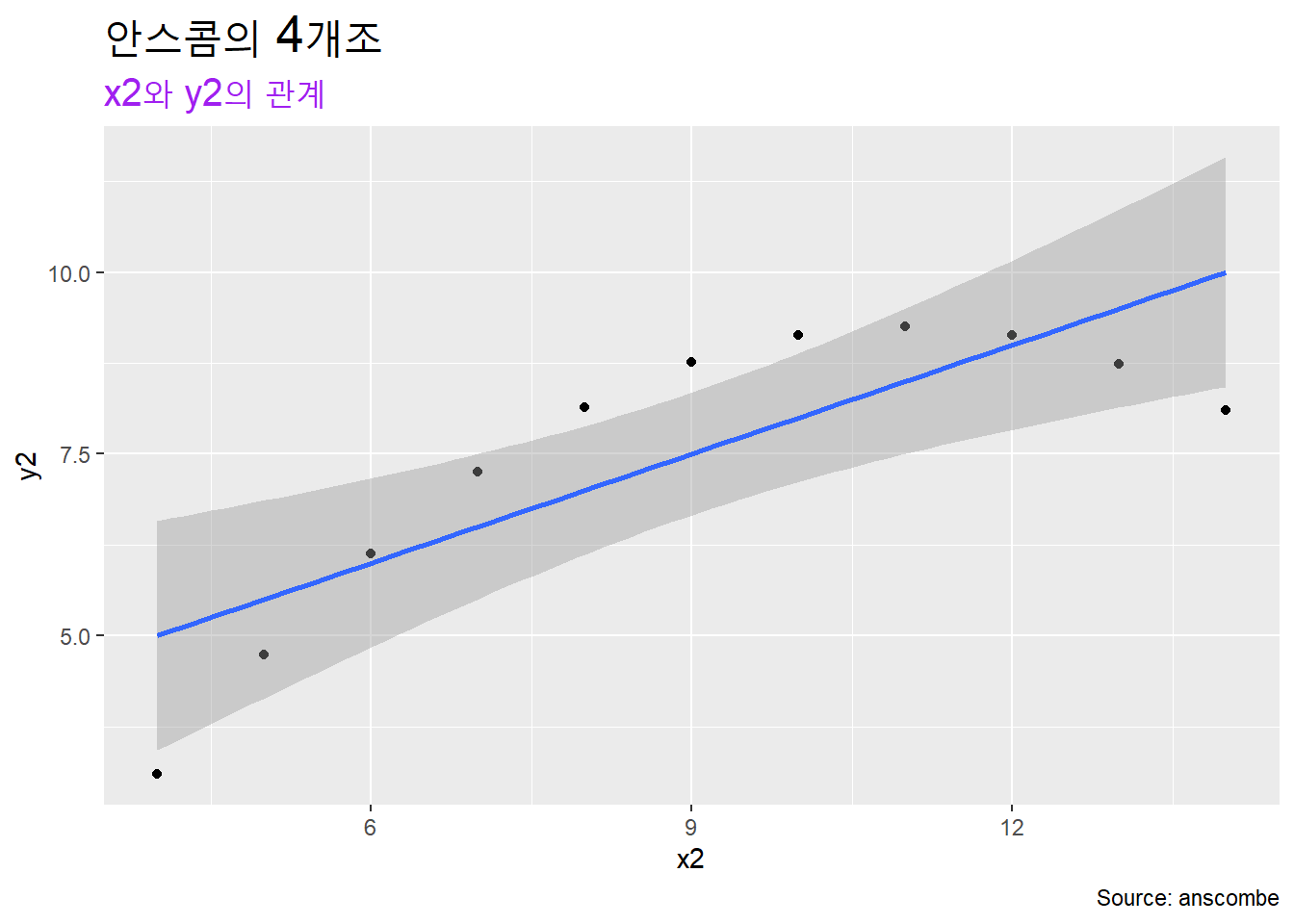
x열과 y열의 4개 쌍의 관계를 모두 산점도와 선도로 시각화해보자. x1-y1, x2-y2, x3-y3, x4-y4 등 4개 쌍에 대해 기술문을 4번 반복해서 작성할 수 있지만, 반복문(loop)을 이용하면 4번의 과정을 자동화할 수 있다.
이번에는 lapply()함수와 사용자함수를 이용해보자.
lapply()의 용법은 다음과 같다.
lapply(X, FUN, ...)
- X : 함수로 실행할 벡터 또는 리스트.
- FUN : 투입한 X인자의 각 요소에 대해 실행할 함수.
- … : 투입한 FUN인자에 사용할 인자.
apply(X, MARGIN, FUN, ...): 계산 방향을MARGIN =인자로 행 방향인지 열방향인지 지정.lapply(X, FUN, ...): 투입한 객체에 대하여 지정한 함수를 반복 계산해 리스트로 산출.sapply(X, FUN, ...): 투입한 객체에 대하여 지정한 함수를 반복 계산해 매트릭스로 산출.
p <- lapply(1:4, function(i) {
x <- anscombe[, i]
y <- anscombe[, i + 4]
ggplot() +
geom_point(aes(x, y)) +
geom_smooth(aes(x, y), method = "lm", se = F) +
labs(subtitle = str_glue("변수{i}"))
})
p## [[1]]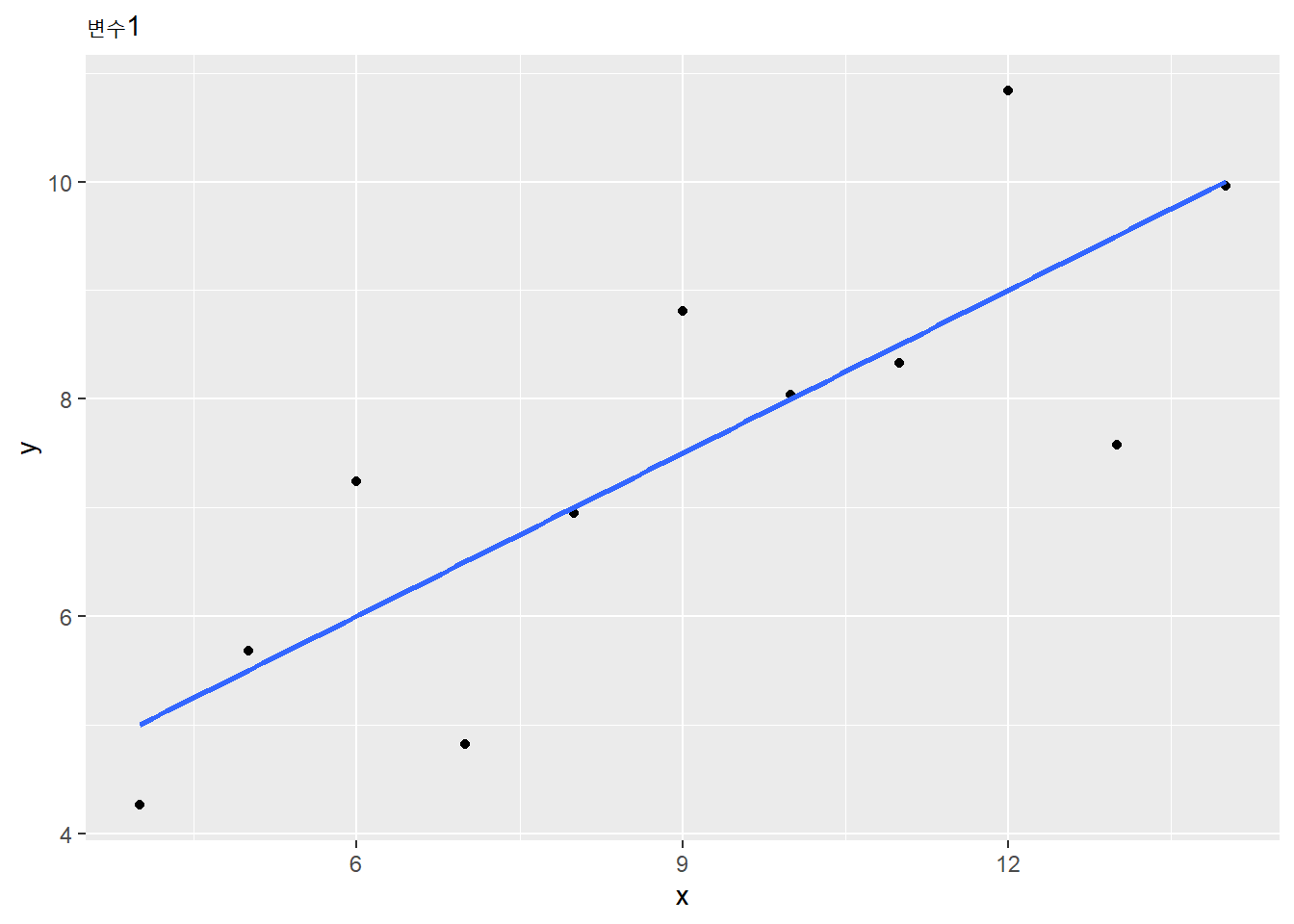
##
## [[2]]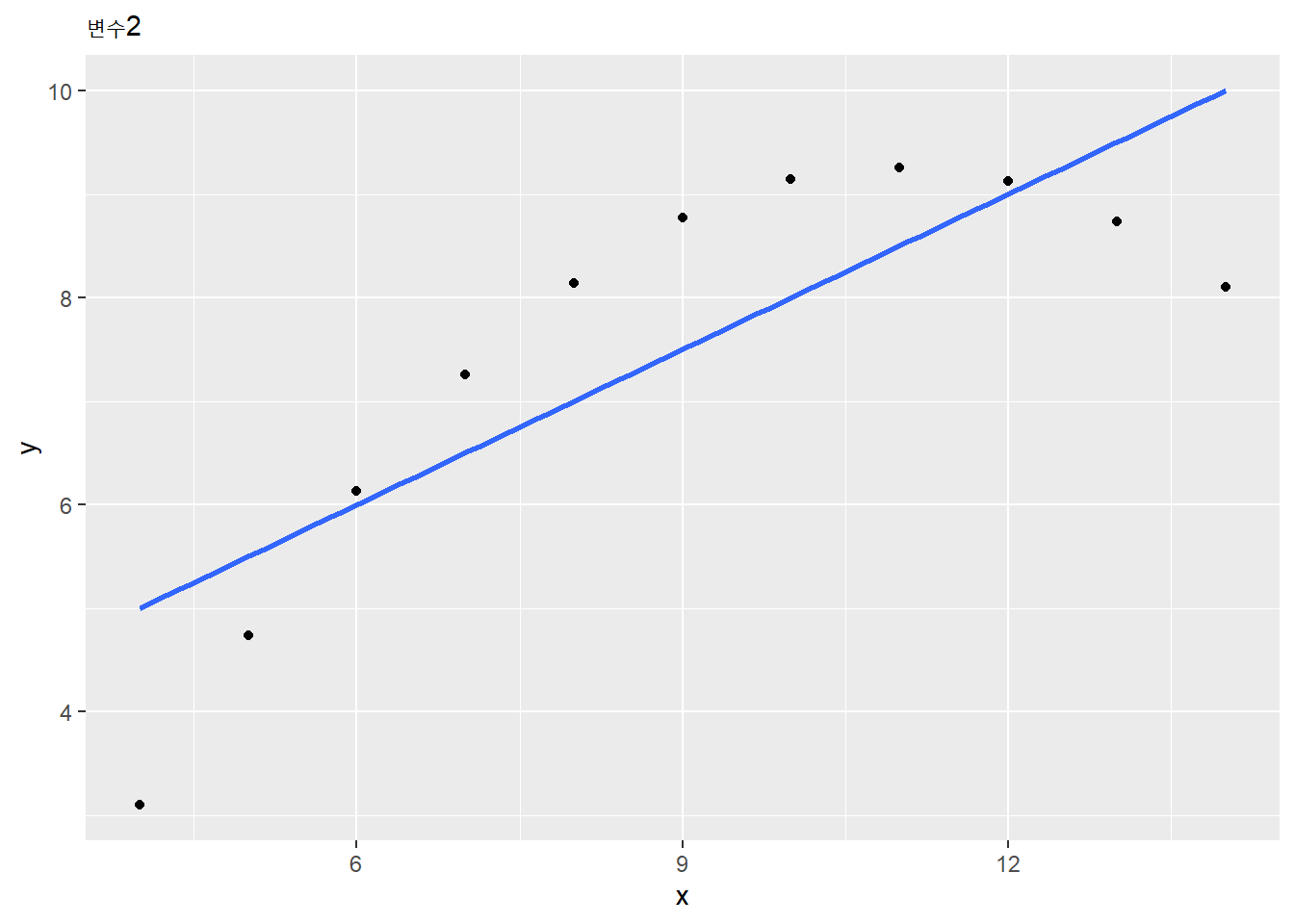
##
## [[3]]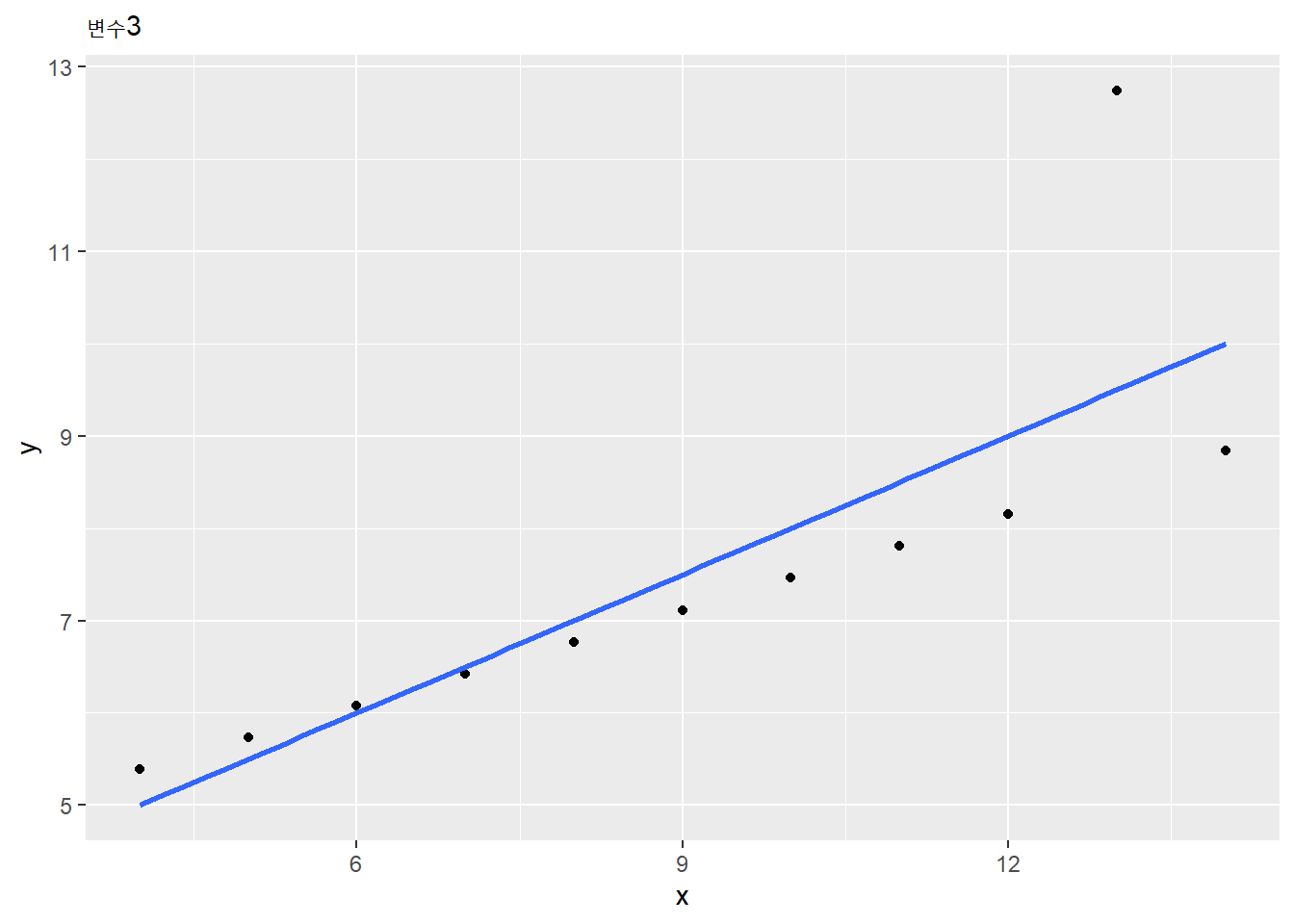
##
## [[4]]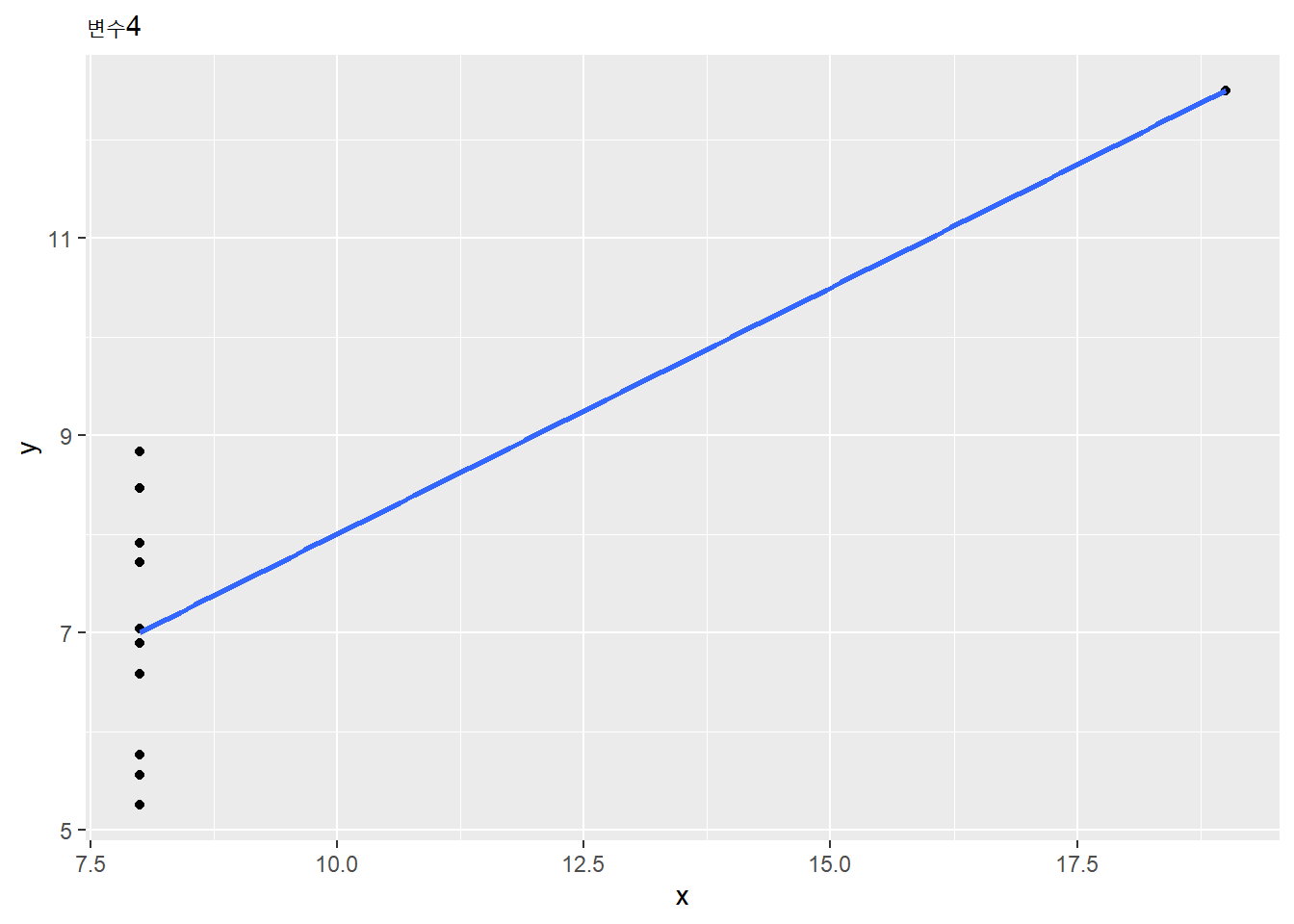
tidyverse와 함께 탑재되는 stringr패키지는 문자형(string)을 처리하는 유용한 함수를 제공한다. 그중 하나가 str_glue()함수다. paste()와 비슷하지만 보다 강력한 기능이 있다.
name <- "홍길동"
age <- 20
str_glue(
"저는 {name}입니다. ",
"내년에 {age + 1}살이 돼요."
)## 저는 홍길동입니다. 내년에 21살이 돼요.2.2.2.1 복수의 도표 배치
patchwork패키지를 이용하면 복수의 도표를 +와 /로 이어 붙여(patch) 하나의 도표로 표시할 수 있다.
위의 코드에서 4개의 도표는 p에 리스트로 저장돼 있으므로, p의 각 요소를 [[ ]]로 부분선택(subsetting)해 각 도표를 +로 좌우방향 patch하고 /로 상하방향 patch해 이어 붙인다.
plot_layout()함수로 행과 열(ncol =)을 설정할수 있다.
plot_layout(
ncol = NULL,
nrow = NULL,
byrow = NULL,
widths = NULL,
heights = NULL,
guides = NULL,
tag_level = NULL,
design = NULL
)plot_annotation()함수는 이어 붙인 도표에 제목, 부제목, 캡션 등을 달수 있다.theme()함수는 제목의 위치(hjust: 가로위치 조정)나 크기(size)를 설정할 수 있다.
plot_annotation()함수와 theme()함수 사이를 &로 연결한 것에 주의하자.
if(!require(patchwork)) install.packages("patchwork")
library(patchwork)
(p[[1]] + p[[2]]) / (p[[3]] + p[[4]]) +
plot_annotation(title = "안스콤의 4개조") &
theme(plot.title = element_text(hjust = .5, size = 20))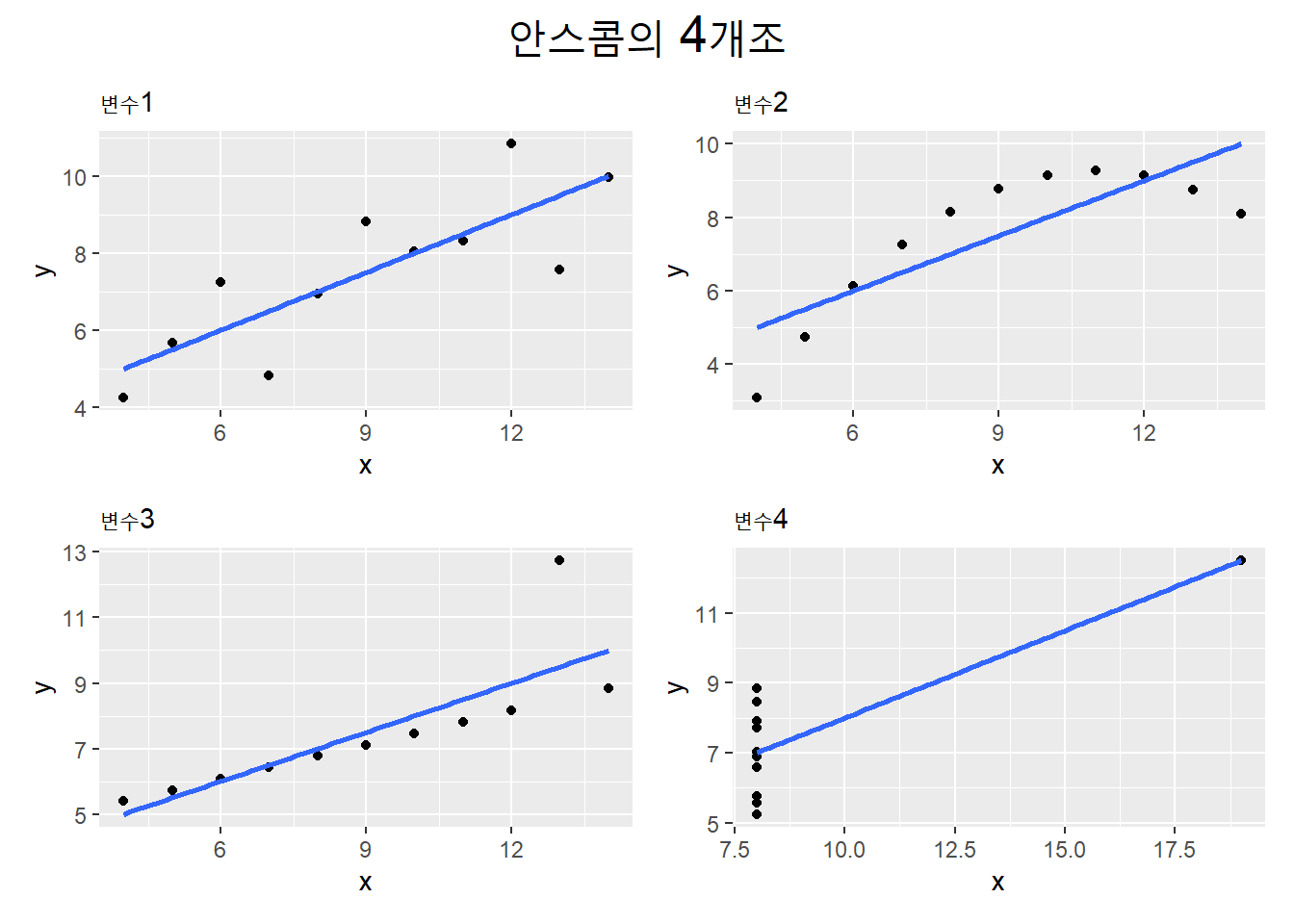
2.3 이야기의 시작
안드로메다 은하계의 코랄 행성에서 고등문명을 이룬 테란은 인근 태양계를 개척하는 중 차우사 행성에서 또다른 고등문명체인 저그 및 프로토스와 조우하게 된다. 테란은 저그와 프로토스가 매우 왕성한 기력을 보유한 것에 관심을 갖고 안드로메다과학재단의 연구원 갑돌이로 하여금 그 원인을 찾도록 했다.
갑돌이는 차우사 행성에서 저그들의 행동을 관찰하던 중 저그들이 즐겨먹는 보양제에 주목했다. 보양제가 저그들의 기력의 비결인지 확인하기 위한 연구에 착수했다.
갑돌이는 저그들의 보양제와 기력을 측정하기 위해 학창시절 배웠던 과학적 탐구절차인 “측정 - 정제 - 분석 - 소통”의 절차를 떠올렸다. 우선, 저그들의 보양제와 기력을 측정하기로 했다.
갑돌이는 저그들이 보양식을 얼마나 먹는지, 그리고 기력은 어느정도인지 자료를 수집하러(즉, 측정하러) 저그 마을에 도착했다. 테란에게 저그에게 접근하기는 힘들었다. 저그들은 갑돌이를 따돌렸다. 자료수집방법을 찾기 전에 우선 가상의 자료를 만들어 모의분석을 하기로 했다.
갑돌이는 저그의 보양제복용량과 기력의 관계를 파악하기 위해 복용량과 기력에 대한 자료가 필요하다. 또한 성별, 나이, 종에 따른 영향도 고려할 생각이다. 이렇게 계획을 세웠지만, 아직 부족한게 느껴졌다. 도대체 이런 자료를 어떻게 수집해야 할까? 다시, 학창시절의 공부한 내용을 떠올렸다. 자료의 유형부터 생각났다.
2.4 자료의 유형(data type)
자료는 다양한 유형이 있는데, 우선 숫자형, 논리형, 문자형 등 3개 유형을 구분하도록 하자.
2.4.1 숫자와 문자의 차이
R은 숫자와 문자를 구분한다. 문자는 " "안에 넣어 숫자와 구분한다. R이 처리하는 방식도 다르다. 숫자와 문자를 합하는 방법을 통해 비교해 볼수 있다.
x에 숫자 10을 할당하고, y에 숫자 20을 할당해 x와 y를 더하는 코드를 작성해보자.
x <- 10
y <- 20
x + y## [1] 30이번에는 x에 문자 10을 할당하고, y에 문자 30을 할당해 x와 y를 더하는 코드를 작성해 보자. 문자이므로 숫자에 따옴표 " "를 넣었다.
x <- "10"
y <- "20"x + yError in x + y : 이항연산자에 수치가 아닌 인수입니다라는 오류메시지가 나타난다. 숫자에 따옴표" "로 감싸 문자형(string)이 됐는데, 숫자처럼 취급했기 때문이다. (작은 따옴표' '로 감싸도 문자형이 된다.)
문자 요소는 paste()함수로 결합한다.
paste(x, y, sep = " ")## [1] "10 20"심화
자료는 값(value)의 성격에 따라 다양한 유형으로 구분할 수 있다. 컴퓨터가 처리하는 방식이 다르기 때문에 이 구분은 중요하다. typeof()함수와 class()함수로 자료의 유형을 알수 있다. typeof()는 원시자료형(낮은 수준의 데이터 유형)을, class()는 높은 수준의 데이터 유형을 알려준다.
2.4.2 숫자형(numeric)
- 정수형(integer): 1, 2, 3, 4, …
- 정수형임을 명확하게 표기하기 위해 숫자 뒤에
L을 추가한다: 1L, 2L, 3L, …
- 정수형임을 명확하게 표기하기 위해 숫자 뒤에
- 실수형(double): 1.12, 2.22, 3.14, 4.15, …
2.4.3 논리형(logical)
- 참
TRUE, 거짓FALSE TRUE는T,FALSE는F로 표기 가능- 주의: “True,” “true” 등은 따옴표 안에 있으므로 논리형이 아니라 문자형.
2.4.4 문자형(character/string)
- “1” , “2” , “3” , …
- “TRUE,” “True,” “true,” …
- “일,” “이,” “삼,” “사,” …
- “남자,” “여자,” …
- “rose,” “pink,” …
2.4.5 특수한 값(value)
2.4.5.1 NA
Not Available의 약어. 즉 결측값(missing value)이다. 데이터의 값(value)이 없다는 의미의 값(value)이다. 논리형이다. 결측값 여부는 is.na()함수를 이용한다.
NA## [1] NAis.na(NA)## [1] TRUEtypeof(NA)## [1] "logical"class(NA)## [1] "logical"2.4.5.2 NULL
값 자체의 부재. NA는 값이 없다는 의미의 값이므로 값으로서 존재한다. 반면, NULL은 값 자체가 없다는 의미이므로 값으로서 존재하지도 않는다.
NULL## NULLis.na(NULL)## logical(0)typeof(NULL)## [1] "NULL"class(NULL)## [1] "NULL"2.5 자료구조
자료가 저장된 자료구조는 다양하다. 자료를 책이라고 한다면, 자료구조는 책을 보관하는 책장이나 서랍 캐비닛 등 에 비유할 수 있다. R에서 주로 사용하는 자료구조는 벡터(vector), 데이터프레임(dataframe), 리스트(list) 등 3가지다. 이외에도 매트릭스(matrix)와 배열(어레이: array)가 있다. 5가지 자료구조를 그림으로 표현하면 다음과 같다 (Figure: 2.3).
심화
정확하게는 벡터를 아토믹벡터(atomic vector)와 제네릭벡터(generic vector)로 구분할 수있다. 아토믹벡터가 일반적으로 말하는 벡터다. 제네릭벡터는 리스트(list).
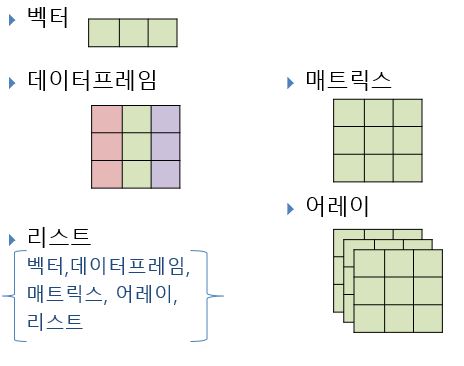
Figure 2.3: 자료구조
2.5.1 벡터 c()
1차원의 자료구조다. 개별 값(요소)를 1차원의 공간에 배치하는 자료구조다. c()함수로 벡터를 만든다. ‘c’는 combine 혹은 concatenate로서 값들을 ’결합하다’ 혹은 ’연결시키다’는 의미다.
‘사과,’ ‘배,’ ‘오렌지’ 등 3개 요소를 벡터에 저장해 ’fruit_v’에 할당해보자.
fruit_v <- c('사과', '배', '오렌지')저장하는 자료의 유형에 따라 벡터의 종류 결정된다.
- 숫자형 값으로만 이뤄졌으면 숫자벡터
- 실수형(double) 벡터:
c(1, 2, 3) - 정수형(integer) 벡터:
c(1L, 2L, 3L)
- 실수형(double) 벡터:
- 논리형 값으로만 이뤄졌으면 논리벡터
c(TRUE, FALSE)
- 문자형 값으로만 이뤄졌으면 문자벡터
c("1", "TRUE", "F", "포도", "apple")
" "나' '로 값의 앞뒤를 감싸면 문자형이 된다.
주의: 벡터를 요소를 다양한 유형으로 구성하면 단일 유형으로 강제 변환(coerce)한다.
c(1, "1")## [1] "1" "1"숫자형(numeric)은 “double(실수형)”과 “integer(정수형)”로 구분한다. 실수형은 소숫점이 있고, 정수형은 소숫점이 없다.
num_v <- c(1, 2, 1, 2)
typeof(num_v)## [1] "double"class(num_v)## [1] "numeric"정수임을 명확하게 표현하기 위해서 1L 30L처럼 숫자 뒤에 L을 붙인다.
int_v <- c(1L, 2L, 1L, 2L)
typeof(int_v)## [1] "integer"class(int_v)## [1] "integer":는 연속하는 숫자를 만들 때 사용한다. 2부터 7까지 연속하는 벡터를 만들어보자.
2:7## [1] 2 3 4 5 6 7seq()함수로 연속하는 숫자를 보다 유연하게 만들 수 있다.
seq(from = 1, to = 1, by = , length.out = , ...)
10부터 30까지 홀수로만 연속하는 숫자를 만들어 보자. (from =, to =처럼 명백한 인자는 표기하지 않아도 된다.)
seq(11, 30, by = 2)## [1] 11 13 15 17 19 21 23 25 27 291부터 짝수로만 연속하는 숫자를 5개 만들어 보자.
seq(2, by = 2, length.out = 5)## [1] 2 4 6 8 102.5.1.1 요인(factor)
요인은 범주형(category) 벡터다. 예를 들어, 성(sex)이라는 범주형 자료는 ‘남자’와 ’여자’라는 속성을 갖고 있는데, 문자형 벡터의 각 값들(’남자,’ ‘남자,’ ‘여자,’ ‘여자’ 등)에서 각 ’남자’와 ’여자’가 개별 문자가 아니라 범주( = level)라고 지정한 자료형이다.
예를 들어 보자. “male,” “female,” “female,” “male” 등 4개 값을 벡터로 만들어 sex_v에 할당하면, sex_v는 문자벡터가 된다. 4개의 문자요소가 생성된다.
typeof()함수는 낮은 수준의 자료형(원시자료형)을 제시한다.class()함수는 높은 수준의 자료형(자료구조 등)을 제시한다.
sex_v <- c("male", "female", "female", "male")
typeof(sex_v)## [1] "character"class(sex_v)## [1] "character"문자벡터를 factor()함수로 요인으로 만들면 ’male female female male ’이라는 글자는 그대로 보이나, " "가 사라진 것을 알수 있다. 개별 문자가 아니라, 범주(category = level)이 됐기 때문이다.
factor(sex_v)## [1] male female female male
## Levels: female malefactor(sex_v) %>% class()## [1] "factor"요인의 원시자료형은 정수이기 때문에, 각 값은 정수로 저장돼 있다.
factor(sex_v) %>% typeof()## [1] "integer"factor(sex_v) %>% str()## Factor w/ 2 levels "female","male": 2 1 1 2levels =인자를 이용해 범주(level)의 순서를 명시적으로 지정할 수 있다.
levels_sex <- c("male", "female")
factor(sex_v)## [1] male female female male
## Levels: female malefactor(sex_v, levels = levels_sex)## [1] male female female male
## Levels: male female글자의 순서와 의미의 순서가 일치하지 않을때 유용하다.
gen_v <- c("어린이", "청소년", "청소년", "성인", "청소년")
factor(gen_v)## [1] 어린이 청소년 청소년 성인 청소년
## Levels: 성인 어린이 청소년levels_gen <- c("어린이", "청소년", "성인")
factor(gen_v, levels = levels_gen)## [1] 어린이 청소년 청소년 성인 청소년
## Levels: 어린이 청소년 성인2.5.1.2 중요: 부분선택(subsetting)
객체에 할당된 요소 일부만 부분적으로 선택(subsetting)할 수 있다. 부분선택(subsetting)은 자료를 다루는데 매우 중요하니 잘 숙지해야 한다.
’fruit_v’에 할당된 세개의 값에는 위치가 숫자로 부여돼 있다. 따라서 그 위치에 대한 숫자로 해당 요소만 부분선택(subset)할 수 있다. 첫번째 요소를 부분선택 해보자.
R은 인덱싱할 때 첫번째 요소를 ‘1’에서 시작한다. (파이썬 등 다른 프로그래밍언어는 ’0’에서 시작). 즉, R은 인간의 직관대로 첫번째 요소는 ’1,’ 두번째 요소는 ’2’가 된다.
fruit_v <- c('사과', '배', '오렌지')
fruit_v[1]## [1] "사과"첫번째와 세번째 요소를 부분선택하려면 숫자벡터를 만들어 실행하면 된다.
fruit_v[c(1, 3)]## [1] "사과" "오렌지"특정 요소를 제외하고 부분선택하려면 -기호를 이용한다. fruit_v에서 첫번째와 세번째 요소를 제외해 부분선택해보자.
fruit_v[-c(1, 3)]## [1] "배"2.5.2 데이터프레임 data.frame()
행과 열로 구성된 2차원의 자료구조다. 1차원 자료구조인 벡터를 모아 만든다. data.frame()함수로 만든다. 벡터를 모아 자료프레임의 열(column)로 투입한다.
문자벡터, 숫자벡터, 논리벡터 등 벡터 5개를 이용해 데이터프레임을 만들어 df에 할당해 보자.
id_v <- c("참가자1", "참가자2", "참가자3")
age_v <- c(32, 33, 45)
status_v <- c(TRUE, FALSE, TRUE)
weight_v <- c(60, 56, 30)
height_v <- c(167, 160, 155)
df <- data.frame(id_v, age_v, status_v, weight_v, height_v)summary()함수로는 각 변수(열)의 값에 대한 요약을 볼수 있다.
summary(df)## id_v age_v status_v weight_v height_v
## Length:3 Min. :32 Mode :logical Min. :30 Min. :155
## Class :character 1st Qu.:32 FALSE:1 1st Qu.:43 1st Qu.:158
## Mode :character Median :33 TRUE :2 Median :56 Median :160
## Mean :37 Mean :49 Mean :161
## 3rd Qu.:39 3rd Qu.:58 3rd Qu.:164
## Max. :45 Max. :60 Max. :167str()함수는 자료구조를 보여준다. ’structure’의 준말이다.
str(df)## 'data.frame': 3 obs. of 5 variables:
## $ id_v : chr "참가자1" "참가자2" "참가자3"
## $ age_v : num 32 33 45
## $ status_v: logi TRUE FALSE TRUE
## $ weight_v: num 60 56 30
## $ height_v: num 167 160 155“‘data.frame’: 3 obs. of 5 variables:”이라고 요약해 준다. 3개 행(row)과 5개 열(column)로 이뤄진 데이터프레임이란 의미다.
“obs.”는 observation의 준말이다. 자료를 수집하면 행에는 개별 사례를 투입하고 변수를 열에 투입하기 때문에 행은 “obs.” 열을 “variables”이라고 표현했다 (Figure: 2.5).
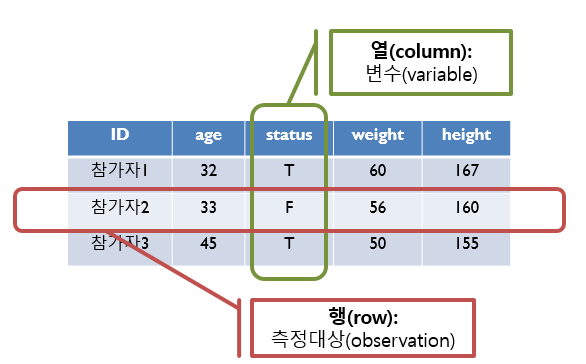
Figure 2.4: 행렬 구조의 데이터프레임
데이터프레임을 엑셀같은 스프레드시트 방식의 행렬로 보고 싶으면 View()함수를 이용한다. 별도의 창에서 행렬로 정렬된 데이터프레임이 열린다 (Figure: 2.5).
View(df)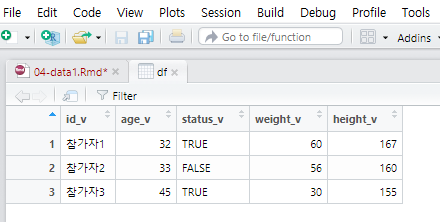
Figure 2.5: View()함수로 보는 데이터프레임
데이터프레임 열이름의 기본값은 열벡터의 이름이 그대로 사용된다. 별도로 이름을 부여할수도 있다.
df <- data.frame(ID = id_v,
age = age_v,
status = status_v,
weight = weight_v,
height = height_v)
df## ID age status weight height
## 1 참가자1 32 TRUE 60 167
## 2 참가자2 33 FALSE 56 160
## 3 참가자3 45 TRUE 30 155데이터테이블은 기능을 강화한 데이터프레임이다. 처리속도가 매우 빠르다.
df <- data.table(ID = id_v,
age = age_v,
status = status_v,
weight = weight_v,
height = height_v)
df## ID age status weight height
## 1: 참가자1 32 TRUE 60 167
## 2: 참가자2 33 FALSE 56 160
## 3: 참가자3 45 TRUE 30 1552.5.2.1 부분선택(subsetting)
데이터프레임은 열벡터(column vector)로 이뤄져 있기 때문에 [ ]로 부분선택하면 해당 열이 부분선택된다. 부분선택된 열은 데이터프레임 구조를 유지한다.
df[2] # `df`데이터프레임의 2번째 열 부분선택. ## ID age status weight height
## 1: 참가자2 33 FALSE 56 160df[2:4] # `df`데이터프레임의 2~4번째 열 부분선택## ID age status weight height
## 1: 참가자2 33 FALSE 56 160
## 2: 참가자3 45 TRUE 30 155
## 3: <NA> NA NA NA NA데이터프레임은 행과 열로 이뤄져 있으므로, 부분선택할 때 행와 열을 나눠 지정할 수 있다.
- n행 m열 선택 : df[n, m]
df[1, ] # `df` 데이터프레임의 1행 부분선택## ID age status weight height
## 1: 참가자1 32 TRUE 60 167df[c(1,2), ] # df` 데이터프레임의 1행과 2행 부분선택## ID age status weight height
## 1: 참가자1 32 TRUE 60 167
## 2: 참가자2 33 FALSE 56 160df[ ,2] # `df` 데이터프레임의 2열 부분선택 (벡터구조로 산출)## age
## 1: 32
## 2: 33
## 3: 45df[ ,c(2,3)] # `df` 데이터프레임의 2열과 3열 부분선택 (데이터프레임으로 산출)## age status
## 1: 32 TRUE
## 2: 33 FALSE
## 3: 45 TRUEdf[2,c(3:5)] # `df` 데이터프레임의 2행과 3~5열 부분선택## status weight height
## 1: FALSE 56 160주의!!! : 행과 열을 구분해 부분 선택할 때 단일 열만 부분선택하는 경우 부분선택된 결과의 자료구조를 구분할 수 있어야 한다.
df[2] # 2번째 열이 데이터프레임으로 부분선택## ID age status weight height
## 1: 참가자2 33 FALSE 56 160df[,2] # 2번째 열이 벡터로 부분선택## age
## 1: 32
## 2: 33
## 3: 45데이터프레임은 열벡터(열을 구성하는 벡터)들의 합이므로, $기호와 열의 이름을 이용해 부분선택할 수 있다. $기호를 이용해 ’ID’열과 ’height’열을 열의 이름으로 부분선택해보자.
df$ID## [1] "참가자1" "참가자2" "참가자3"df$height## [1] 167 160 155tidytable패키지는 처리속도가 빠른 데이터테이블을 기반으로 tidyverse식의 구문을 사용할 수 있도록 하는 패키지다. 기본적인 사용법은 dplyr와 비슷하다. 함수도 dplyr의 함수에 verb.()과 같은 방식으로 사용하도록 돼 있다.
먼저 패키지를 설치하고 R환경에 탑재하자.
if(!require(tidytable)) install.packages("tidytable")
library(tidytable)열을 부분선택할 때 tidytable패키지의 select.()함수를 이용하면 편리하다. (dplyr패키지의 select()함수에 해당)
select()함수의 다양한 용법은 설명서 참조.
select()를 함수명으로 이용하는 패키지가 많기 때문에, select()함수를 이용할 때는 와 혼동을 피하기 위해 dplyr::select()처럼 명시적으로 dplyr패키지의 select()함수를 사용한다고 기술하는 것이 좋다.
select.(df, ID, age) # df데이터프레임에서 ID와 age열 선택## # A tidytable: 3 x 2
## ID age
## <chr> <dbl>
## 1 참가자1 32
## 2 참가자2 33
## 3 참가자3 45select.(df, status:height) # status열부터 height열까지 순서대로 모두 포함해 선택## # A tidytable: 3 x 3
## status weight height
## <lgl> <dbl> <dbl>
## 1 TRUE 60 167
## 2 FALSE 56 160
## 3 TRUE 30 155select.(df, -c(ID, age)) # ID열과 age열만 제외하고 선택## # A tidytable: 3 x 3
## status weight height
## <lgl> <dbl> <dbl>
## 1 TRUE 60 167
## 2 FALSE 56 160
## 3 TRUE 30 155행을 부분선택할 때는 filter.()함수를 이용한다.
dplyr패키지의filter()함수의 다양한 용법은 설명서 참조.
주의!!! : =는 <-와 같은 의미로 ’할당하다’가 된다. “같다”는 의미는 ==다.
ID열의 ’참가자1’과 같은 행에 있는 행을 선택해 보자.
filter.(df, ID == "참가자1") ## # A tidytable: 1 x 5
## ID age status weight height
## <chr> <dbl> <lgl> <dbl> <dbl>
## 1 참가자1 32 TRUE 60 167!기호는 ’Not’이라는 의미다. ID열에서 “참가자1”과 같은 행의 행을 제외하고 부분선택해 보자. 아래 두 경우 모두 같은 결과를 산출한다.
filter.(df, !ID == "참가자1")## # A tidytable: 2 x 5
## ID age status weight height
## <chr> <dbl> <lgl> <dbl> <dbl>
## 1 참가자2 33 FALSE 56 160
## 2 참가자3 45 TRUE 30 155filter.(df, ID != "참가자1")## # A tidytable: 2 x 5
## ID age status weight height
## <chr> <dbl> <lgl> <dbl> <dbl>
## 1 참가자2 33 FALSE 56 160
## 2 참가자3 45 TRUE 30 155dplyr사용법요약: dplyr 사용법을 정리한 요약본(cheat sheet)은 여기서 다운로드 받을 수 있다. 전반적인 기능이 잘 정리돼 있다.
2.5.3 리스트 list()
리스트는 다양한 구조의 자료를 담을 수 있는 일종의 서랍장과 같은 자료구조다.
먼저 아래의 경우처럼 벡터를 구성하는 요소의 수가 다른 경우부터 살펴보자.
data.frame(a = 1:3, b = 1:4)Error in data.frame(a = 1:3, b = 1:4) : arguments imply differing number of rows: 3, 4라며 행의 수가 같지 않으면 오류가 생긴다. 데이터프레임을 구성하는 열벡터에 포함된 요소의 숫자는 같아야 한다. 행렬구조이기 때문이다.
이처럼 구성 요소의 길이가 다르면 리스트 형식의 자료터구조에 담아야 한다.
list(a = 1:3, b = 1:4)## $a
## [1] 1 2 3
##
## $b
## [1] 1 2 3 4데이터프레임은 길이가 같은 열벡터로만 만들지만, 리스트는 벡터, 데이터프레임, 리스트 등 모든 형식의 자료구조를 이용해 만들수 있다. 리스트는 이것 저것 넣어두는 서랍장이라 할수 있다.
cha <- "리스트"
number <- c(25, 26, 18, 39)
string <- c("one", "two", "three", "four")
df2 <- data.frame(number, string)
list_l <- list(CH = cha, NU = number, ST = string, DF = df2)
str(list_l)## List of 4
## $ CH: chr "리스트"
## $ NU: num [1:4] 25 26 18 39
## $ ST: chr [1:4] "one" "two" "three" "four"
## $ DF:'data.frame': 4 obs. of 2 variables:
## ..$ number: num [1:4] 25 26 18 39
## ..$ string: chr [1:4] "one" "two" "three" "four"2.5.3.1 부분선택
리스트에는 다른 자료구조가 하부요소로 포함돼 있기 때문에 부분선택할 때 [ ]와 [[ ]]를 이용한다. 앞서 만든 리스트 ’list_l’의 2번째 요소를 [ ]와 [[ ]]로 각각 부분선택해 결과를 비교해보자.
list_l[2] %>% typeof()## [1] "list"list_l[[2]]## [1] 25 26 18 39[ ]로 부분선택하면 리스트 구조를 유지한 채 부분선택한다. [[ ]]로 부분선택하면 구성요소의 구조(여기서는 벡터)로 부분선택한다.
데이터프레임이 리스트의 구성요소일때는 $와 [ ]를 함께 사용하거나 [[ ]]와 [ ]를 함께 이용한다.
list_l$DF[2] # 리스트 list_l의 DF요소에서 2번재 열 부분선택## string
## 1 one
## 2 two
## 3 three
## 4 fourlist_l[[4]][2] # 리스트 list_l의 DF요소의 4번재 요소 중 2번째 열 부분선택## string
## 1 one
## 2 two
## 3 three
## 4 four2.5.4 매트릭스와 어레이(배열)
벡터를 2차원 구조로 구성한 자료구조가 매트릭스이고, 3차원 구조로 구성한 자료구조가 어레이다. 달리 표현하면, 벡터는 1차원 어레이, 매트릭스는 2차원 어레이, 어레이는 3차원 어레이라고도 할수 있다.
2.5.4.1 매트릭스 matrix()
벡터에 행과 열을 지정해 만든다. 1부터 20까지의 숫자로 이뤄진 벡터를 5개 행으로 이뤄진 매트릭스를 만들면 다음과 같다.
matrix(1:20, nrow = 5)## [,1] [,2] [,3] [,4]
## [1,] 1 6 11 16
## [2,] 2 7 12 17
## [3,] 3 8 13 18
## [4,] 4 9 14 19
## [5,] 5 10 15 20열을 지정해 만들수도 있다.
matrix(1:20, ncol = 10)## [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
## [1,] 1 3 5 7 9 11 13 15 17 19
## [2,] 2 4 6 8 10 12 14 16 18 202.5.4.2 어레이 array()
기본 속성은 벡터나 매트릭스와 같다. 1개 차원만 지정하면 벡터, 2개 차원만 지정하면 매트릭스가 된다. 차원은 dim =인자를 이용한다.
1부터 6까지의 숫자벡터를 2행 3열의 매트릭스로 만들어 보자. matrix()함수와 array()함수를 이용한다. dim = c(2, 3)은 행 2개, 열 3개 등 2차원으로 배치하라는 의미이므로 매트릭스를 만들게 된다.
matrix(1:6, nrow = 2)## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6array(1:6, dim = c(2, 3))## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 63차원 어레이를 만들려면 차원 인자 dim =에 행과 열 외에 추가차원을 지정한다. 1에서 24까지의 숫자벡터를 2행과 3열로 이뤄전 3차원 어레이를 만드는 경우, 투입한 인자 dim = c(2, 3, 4)는 2행 3열의 행렬을 4개 만들라는 의미다.
array(1:24, dim = c(2, 3, 4))## , , 1
##
## [,1] [,2] [,3]
## [1,] 1 3 5
## [2,] 2 4 6
##
## , , 2
##
## [,1] [,2] [,3]
## [1,] 7 9 11
## [2,] 8 10 12
##
## , , 3
##
## [,1] [,2] [,3]
## [1,] 13 15 17
## [2,] 14 16 18
##
## , , 4
##
## [,1] [,2] [,3]
## [1,] 19 21 23
## [2,] 20 22 242.6 변수와 척도
2.6.1 변수(Variable)
기력과 보양제의 복용량은 고정된 값이 아니라 변하는 값이다. 이처럼 변하는 값을 변수(variable)라고 한다. 변함이 없는 값이 상수(constant)다. (데이터프레임의 열을 변수(variable)라고 했다.)
변수는 “변하는” 속성에 따라 연속변수와 불연속변수로 구분한다.
- 연속변수(continuous variable): 속성이 연속적인 값(숫자)으로 구성. 속성과 속성 사이에 셀수 없을만큼 많은 값을 가정할 수 있다. 1과 2 사이에는 1.2, 1.21, 1.211 등이 끝없이 있을 수 있다.
- 예: 나이, 점수 등
- 불연속변수(이산변수: discrete variable): 속성이 불연속적인 값(범주 or 요인)으로 구성.
- 예: 성(sex), 인종, 세대 등
그렇다면, 기력과 복용량은 연속변수일까, 불연속변수일까? 만일, 기력을 연속하는 숫자(예: 1, 1.5, 2, 3)로 구성한다면 연속변수다. 반면, 불연속하는 범주(예: 강과 약)로 구성하면 불연속 변수다.
2.6.2 척도(Scale)
변수를 측정하는 도구를 척도라고 한다. 척도는 측정하는 수준(Measurement Level: 측정수준)에 따라 명목척도, 서열척도, 등간척도, 비율척도 등 4종으로 구분한다.
명목척도(nominal scale):
변수의 속성을 고유한 범주(속성이 서로 다르다)로 측정하는 척도다. 성변수에는 남자와 여자라는 서로 다른 속성이 있다. 인종이란 변수도 아시안 코카시안 아프리칸 서로 다른 속성이 있다. 명목변수의 속송에는 명목(이름)만 갖고 있다.서열척도(ordinal scale):
변수의 속성을 상대적인 크기로 측정하는 척도다. 명목척도에 순서(서열)가 추가된 척도다. 지적능력을 “높음, 중간, 낮음”으로 측정한다면 “높음-중간-낮음”으로 순서가 부여된다.등간척도(interval scale):
변수의 속성을 일정한 간격(등간)으로 측정하는 척도다. 서열척도에 간격이 추가된 척도다. 지적능력으 높음과 중간, 중간과 낮음 사이의 간격은 같지 않다. 그러나, 지적능력을 IQ와 같은 도구로 측정해 점수를 산출한다면, 점수와 점수의 간격이 동일하다. 120과 130의 간격(차이)과 110과 120의 간격은 모두 10으로서 같다.등간척도의 값은 상대적이다. IQ 200은 100보다 점수로는 2배이나, 지적능력이 2배라는 의미는 아니다. 등간척도의 0의 임의로 정한 상대적인 값이다. IQ가 0점이라고 해서 지적능력이 전혀 없는 것은 아니다.
비율척도(ratio scale):
변수의 속성에 절대 영점(0)이 포함돼 있어 실질적인 값(비율)을 반영한 척도다. 섭씨온도의 값은 끊는 점과 어는 점을 기준을 100등분한 상대적인 속성이나, 절대온도의 값은 분자운동을 반영한 값이다. 등간척도인 섭씨 0도는 임의로 정한 상대적인 값이나, 비율척도인 절대온도의 0은 분자운동이 정지해 운동에너지가 0인 절대적인 값이다.척도의 측정수준에 따라 적용하는 통계도구가 달라진다. 등간척도와 비율척도는 사칙연산이 가능하고, 평균과 표준편차를 구할 수 있다. 등간척도와 비율척도로 자료를 수집해야 분석에 용이하다.
2.7 자료생성
이제 갑돌이는 감이 잡혔다. 저그의 보양제복용량과 기력의 관계에 대해 성별, 나이, 종에 따른 영향도 고려해야 하므로, 변수는 복용량, 기력, 성별, 나이, 종이다. 여기에 연구참여자를 비실명으로 식별하기 위한 ID도 추가했다. 실명을 이용하면 저그들의 개인정보를 보호할수 없기 때문이다. 생명윤리위원회(Institutional Review Board: IRB)가 연구를 승인한 조건이기도 하다.
따라서 필요한 자료구조는 6개 열의 데이터프레임이다. 아래와 같은 방식으로 만들 수 있다. data.frame()함수보다 속도가 빠른 data.table()함수를 이용했다.
data.table(
id = id_v,
sex = sex_v,
species = species_v,
age = age_v,
dose = dose_v,
vigor = vigor_v,
)데이터프레임은 값의 개수가 같은 열벡터를 결합한 것이므로 각 변수별로 벡터를 만들 차례다.
2.7.1 문자형 벡터
문자형 벡터는 아이디, 성별, 종 등 3개 변수다.
2.7.1.1 아이디
갑돌이는 우선 아이디를 만들었다. 각 종별로 60명씩 총 180명의 자료를 수집할 계획이므로, 아이디 180개를 만들었다. 저그로 부터 수집한 자료는 테란 및 프로토스의 자료와 비교해야 하므로 총 90개가 필요하다.
id_zerg <- paste0("저그", 1:60)
id_teran <- paste0("테란", 1:60)
id_protos <- paste0("프로토스", 1:60)
id_v <- c(id_zerg, id_teran, id_protos)
str(id_v)같은 작업을 반복했으니 반복문을 이용해 코드를 단순화했다.
id <- c("저그", "테란", "프로토스")
nn <- 60
id_v <- vector()
for(i in seq_along(id)){
output <- paste0(id[i], 1:nn)
id_v <- c(id_v, output)
}
str(id_v)## chr [1:180] "저그1" "저그2" "저그3" "저그4" "저그5" "저그6" "저그7" ...2.7.1.2 종
갑돌이는 저그, 테란, 프로토스 등 종별로 자료를 수집해야 하기 때문에 저그, 테란, 프로토스 등의 값을 속성으로 저장한 종변수를 만들어야 한다. 각 30개씩 총 90개의 값을 만들어보자. rep()는 같은 값을 복제(replicate)하는 함수다.
sp_zerg <- rep("저그", 60)
sp_teran <- rep("테란", 60)
sp_protos <- rep("프로토스", 60)
species_v <- c(sp_zerg, sp_teran, sp_protos)위 코드 역시 반복문으로 단순화할 수 있다. id_v벡터 만들때 사용한 코드를 조금만 바꾸면 된다.
id <- c("저그", "테란", "프로토스")
nn <- 60
species_v <- vector()
for(i in seq_along(id)){
output <- rep(id[i], nn)
species_v <- c(species_v, output)
}
table(species_v)## species_v
## 저그 테란 프로토스
## 60 60 60불연속변수는 막대도표로 시각화할 수 있다.
data.table(species = species_v) %>%
ggplot(aes(species)) + ylim(0, 80) +
geom_bar() +
labs(title = "종별 참가자 수") +
theme(title = element_text(size = 15))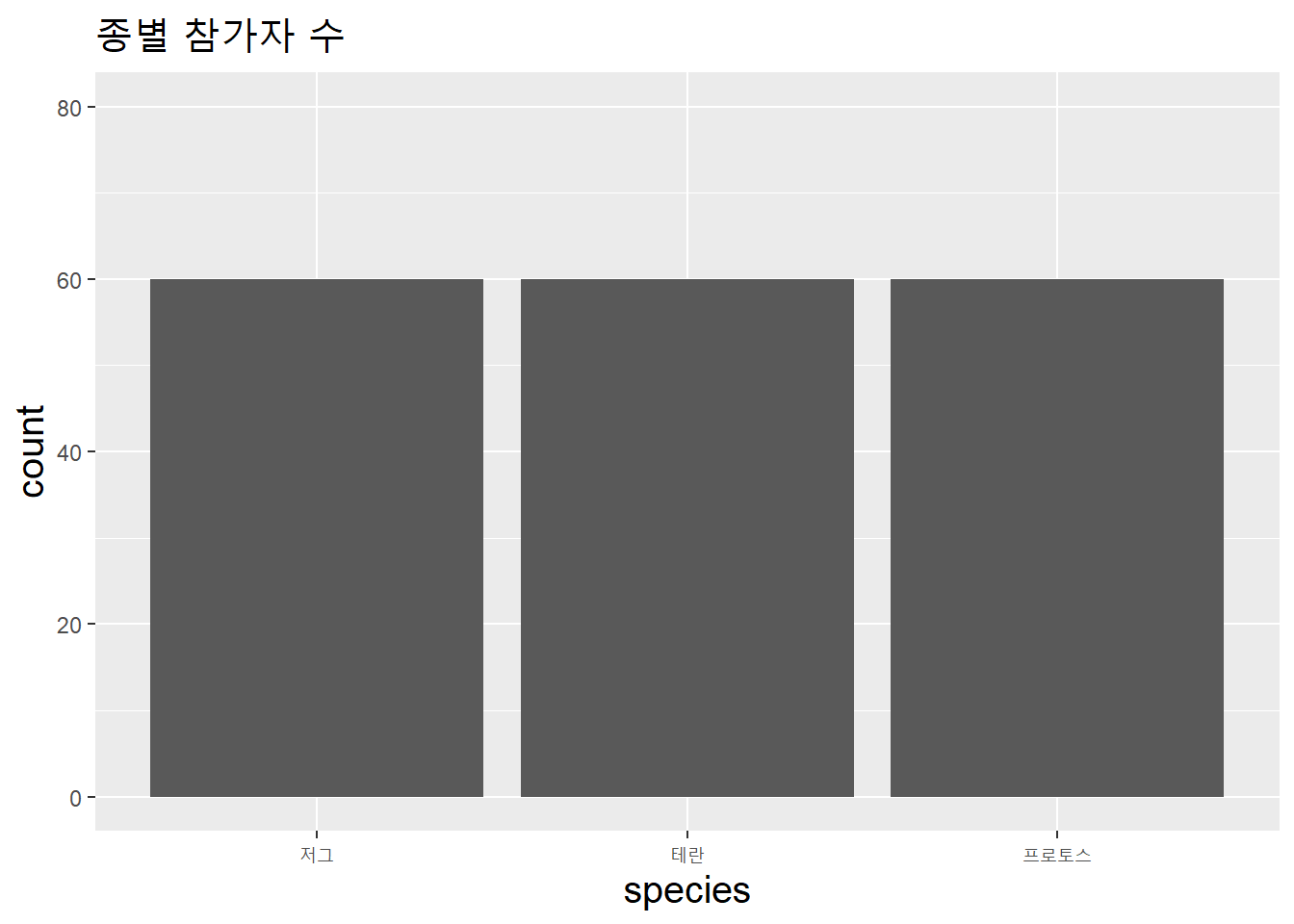
coord_flip()로 가로축을 Y로 세로축을 X로 바꿀 수 있다.
data.table(species = species_v) %>%
ggplot(aes(species)) + ylim(0, 80) +
geom_bar() +
coord_flip() +
labs(title = "종별 참가자 수") +
theme(title = element_text(size = 15))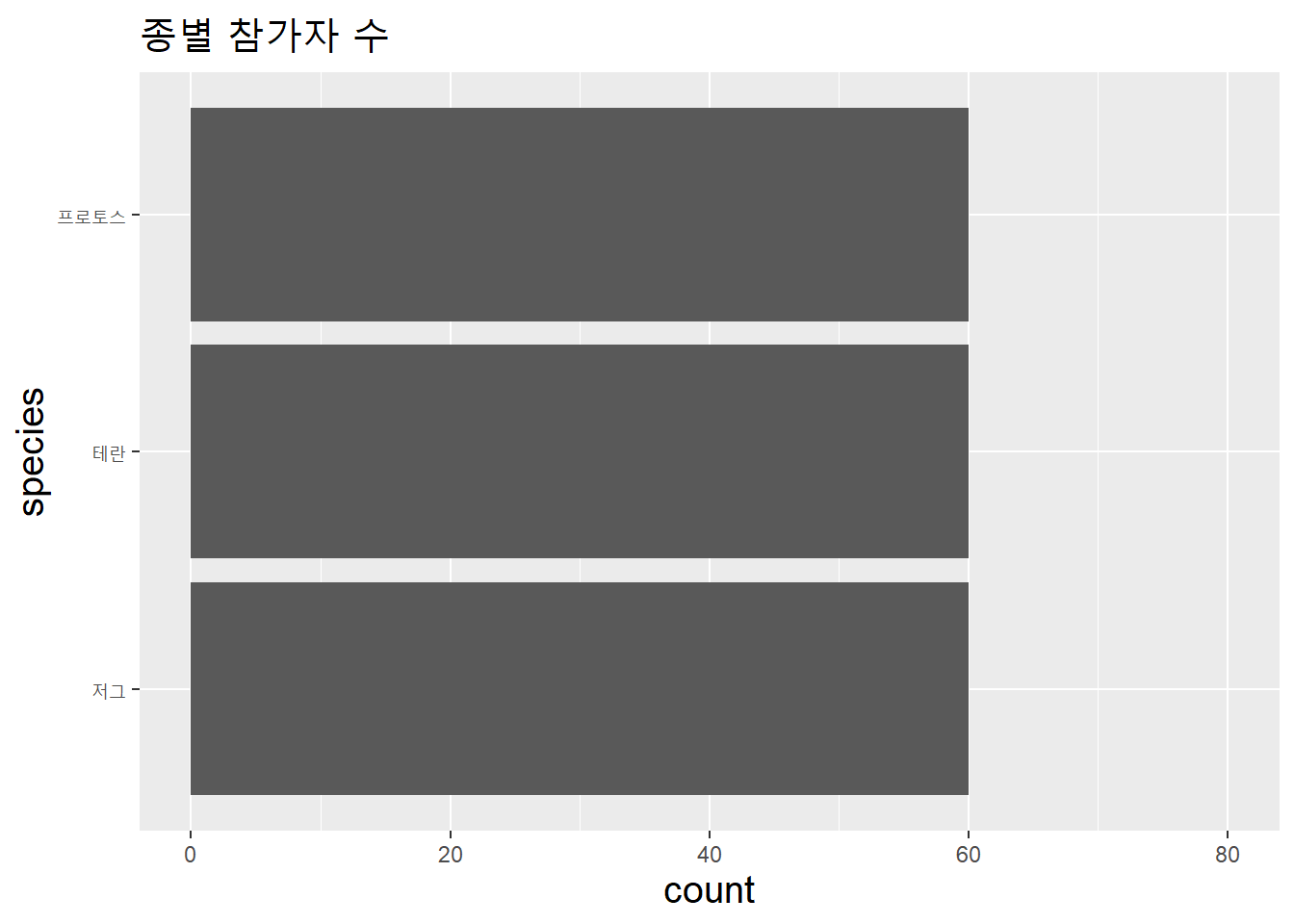
fill =인자를 이용해 막대별 색을 달리 설정할 수 있다 (color =는 테두리 색 지정.) width =인자로 막대의 두께를 조정할 수 있다. [색설정 참조(http://www.cookbook-r.com/Graphs/Colors_(ggplot2)/].
data.table(species = species_v) %>%
ggplot(aes(species)) + ylim(0, 80) +
geom_bar(fill = c("red", "blue", "green"), width = .4) +
coord_flip() +
labs(title = "종별 참가자 수") +
theme(title = element_text(size = 15))
Color Brewer를 이용하면 미리 체계적으로 짜여진 색의 조합(color palette)을 이용해 색 지정이 가능하다. colorbrewer2에서 색의 조합을 미리 볼수 있다.
종별 참가자수이므로 종별 구분이 두드러지도록 Qualitative의 Dark2 팰릿을 선택해보자. aes()에 fill =을 추가하고, scale_fill_brewer()함수와 함께 쓴다. 만일, aes()에 color =를 투입했으면, scale_color_brewer() 사용.
data.table(species = species_v) %>%
ggplot(aes(species, fill = species)) + ylim(0, 80) +
geom_bar(width = .5) +
coord_flip() +
scale_fill_brewer(palette = "Dark2") +
labs(title = "종별 참가자 수") +
theme(title = element_text(size = 15),
legend.position = "none") # 범례(legend) 표시 여부
2.7.1.3 성
성별로도 자료를 수집해야 하므로 성별 벡터를 만들어야 한다. 성별은 난수로 임의의 값을 만들었다. 남성은 0, 여성은 1의 값을 부여할 계획이다. 이를 위해 rbinom()함수를 이용해 0과 1의 값을 촟 180개 임의로 생성했다.
rbinom(n = 180, size = 1, prob = .5) 이항분포(Binomial distribution)
결과가 성공/실패, 동전앞면/뒷면, 남자/여자, 발생/미발생 등 둘 중 하나로만 나오는 시행(어떤 것을 실제로 하는 것)을 베르누이 시행이라고 한다. 베르누이분포는 베르누이시행을 했을 때 나오는 값의 분포다. 예를 들어, 공평한(앞면/뒤면 확률이 같은) 동전을 던졌을 때 앞면인 경우를 성공으로 치고, 뒷면을 실패라고 치는 시행을 하는 경우, 베르누이분포를 이루는 값은 실패(0)와 성공(1)으로만 이뤄진다. 동전을 던지는 시행횟수는 1회이고, 성공확률은 1/2이기 때문이다.
성공확률이 1/2인 베르누이분포를 이루는 값을 1개 구한다면 어떻게 해야할까?
rbinom(n = 난수개수, size = 시행횟수, prob = 성공확률)
rbinom(n = 1, size = 1, prob = 1/2)구하는 값을 17개로 늘리면 n = 인자를 17로 늘리면 된다.
set.seed(37)
rbinom(n = 17, size = 1, prob = 1/2)## [1] 1 0 1 0 1 1 0 0 0 0 0 1 0 0 1 1 1베르누이시행을 n번하는 시행을 이항시행(binomial trial)이라고 하고, 이항시행을 했을 때 나오는 값의 분포가 이항분포다. 예를 들어, 공평한 동전을 던지기를 1회가 아닌 2회를 시행하는 경우, 이항분포를 이루는 값은 실패2회(0+0), 실패1회 성공1회(0+1), 성공2회(1+1)로 이뤄진다. 2회 시행에 성공확률이 0.5인 이항분포의 값을 17개 구한다면 다음과 같이 하면 된다.
set.seed(37)
rbinom(n = 17, size = 2, prob = .5)## [1] 1 0 1 1 1 2 1 1 0 0 1 1 1 0 2 2 2결국, 베르누이분포는 이항분포를 1회 시행하는 특수한 경우다. 이항분포는 값이 0, 1, 2 등으로 불연속적인(discrete)이기 때문에 이산분포(또는 불연속분포)다. 베르누이분포와 이항분포를 시각화하면 다음과 같은 차이가 있다.
dist_br <- rbinom(n = 10000, size = 1, prob = .5)
data.table(x = dist_br) %>%
ggplot(aes(x)) + ylim(0, 6000) +
geom_bar(width = .4) +
labs(title = "베르누이분포") +
theme(title = element_text(size = 15))
그런데, 이 막대도표는 x축의 값을 이산변수가 아닌 연속변수로 표시했다. rbinom()함수는 숫자벡터를 산출하기 때문이다. 이를 요인(factor)으로 변경해 불연속변수(이산변수)로 바꾼다.
dist_br <- rbinom(n = 10000, size = 1, prob = .5) %>% factor()
data.table(x = dist_br) %>%
ggplot(aes(x)) + ylim(0, 6000) +
geom_bar(width = .4) +
labs(title = "베르누이분포") +
theme(title = element_text(size = 15))
시행회수를 늘린 이항분포를 시각화하자.
dist_br <- rbinom(n = 10000, size = 30, prob = .5) %>% factor()
data.table(x = dist_br) %>%
ggplot(aes(x)) + ylim(0, 2000) +
geom_bar(width = .4) +
labs(title = "이항분포") +
theme(title = element_text(size = 15))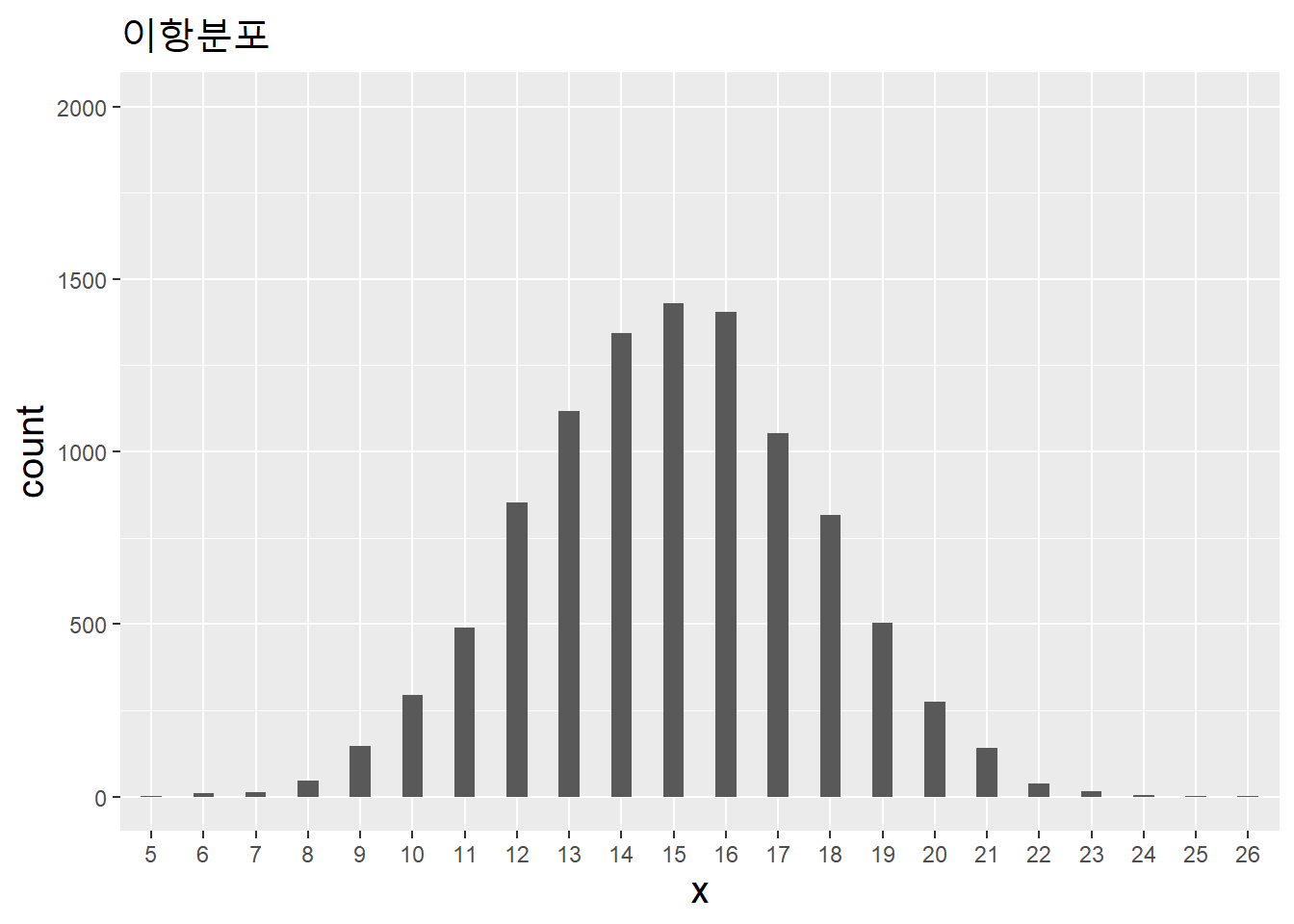
table()함수로 각 성별 참가자수를 계산해보자.
set.seed(73737)
rbinom(n = 180, size = 1, prob = .5) -> sex_v
table(sex_v)## sex_v
## 0 1
## 97 83janitor패키지의 tabyl()함수를 이용하면 보다 풍부한 계산결과를 볼수 있다.
if(!require(janitor)) install.packages("janitor")
library(janitor)
tabyl(sex_v)## sex_v n percent
## 0 97 0.54
## 1 83 0.46rbinom()함수로 생성된 값은 숫자벡터인데, 성별은 범주형 변수다. factor()함수를 이용해 요인(factor)으로 바꿔준다.
set.seed(73737)
rbinom(n = 180, size = 1, prob = .5) %>%
factor(labels = c("남성", "여성")) -> sex_v
tabyl(sex_v)## sex_v n percent
## 남성 97 0.54
## 여성 83 0.46종족별로 남성과 여성의 분포를 계산해보자.
data.table(species = species_v,
sex = sex_v) %>%
ggplot(aes(species, fill = sex)) +
geom_bar() +
coord_flip() +
labs(title = "각 종의 성별 분포") +
theme(title = element_text(size = 15))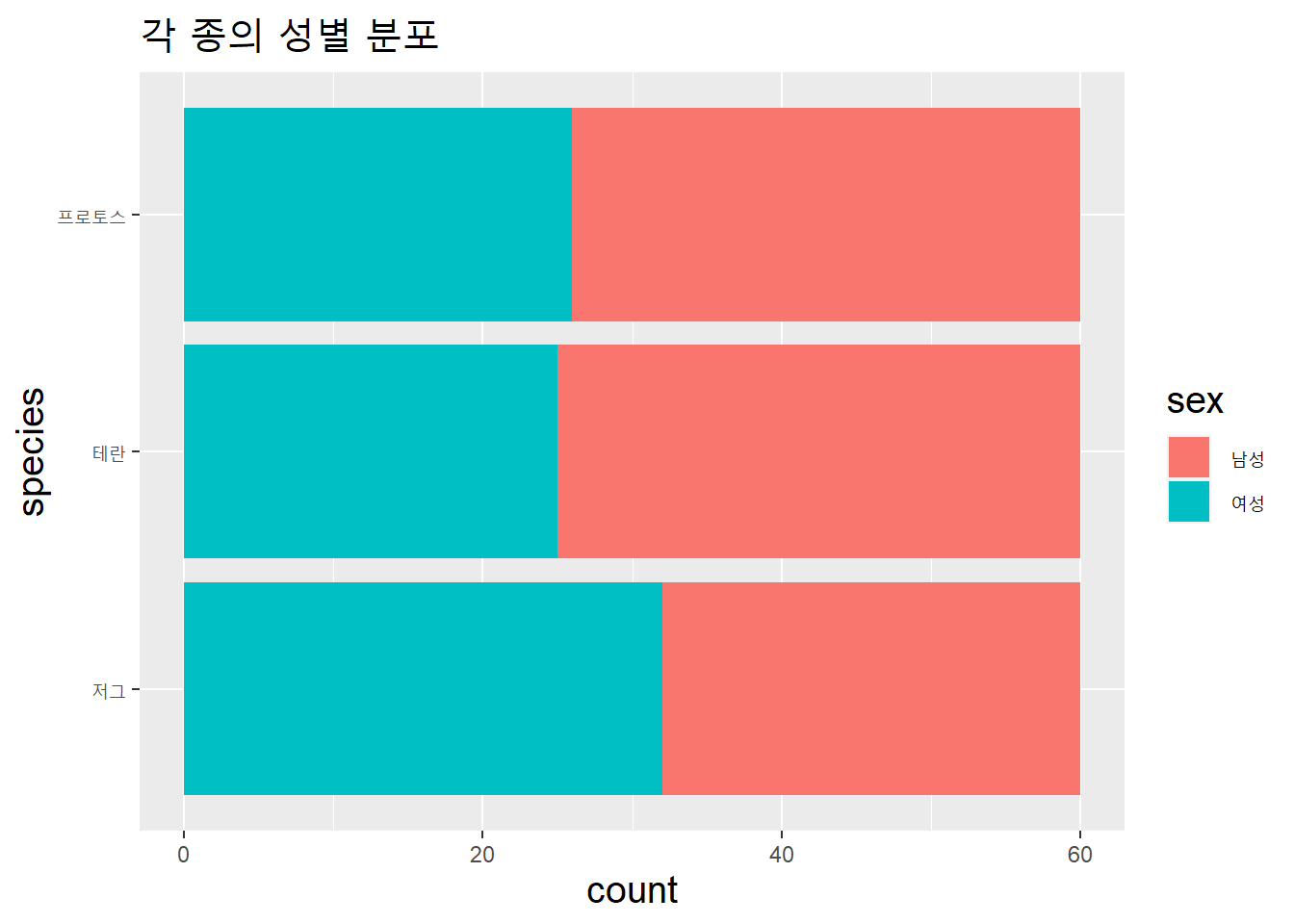
position = 인자의 기본값은 "stack"이다. "dodge"로 설정하면 막대 위치를 아래 그림처럼 바꿀수 있다. geom_bar()사용법.
data.table(species = species_v,
sex = sex_v) %>%
ggplot(aes(species, fill = sex)) +
geom_bar(position = "dodge") +
coord_flip() +
labs(title = "각 종의 성별 분포") +
theme(title = element_text(size = 15))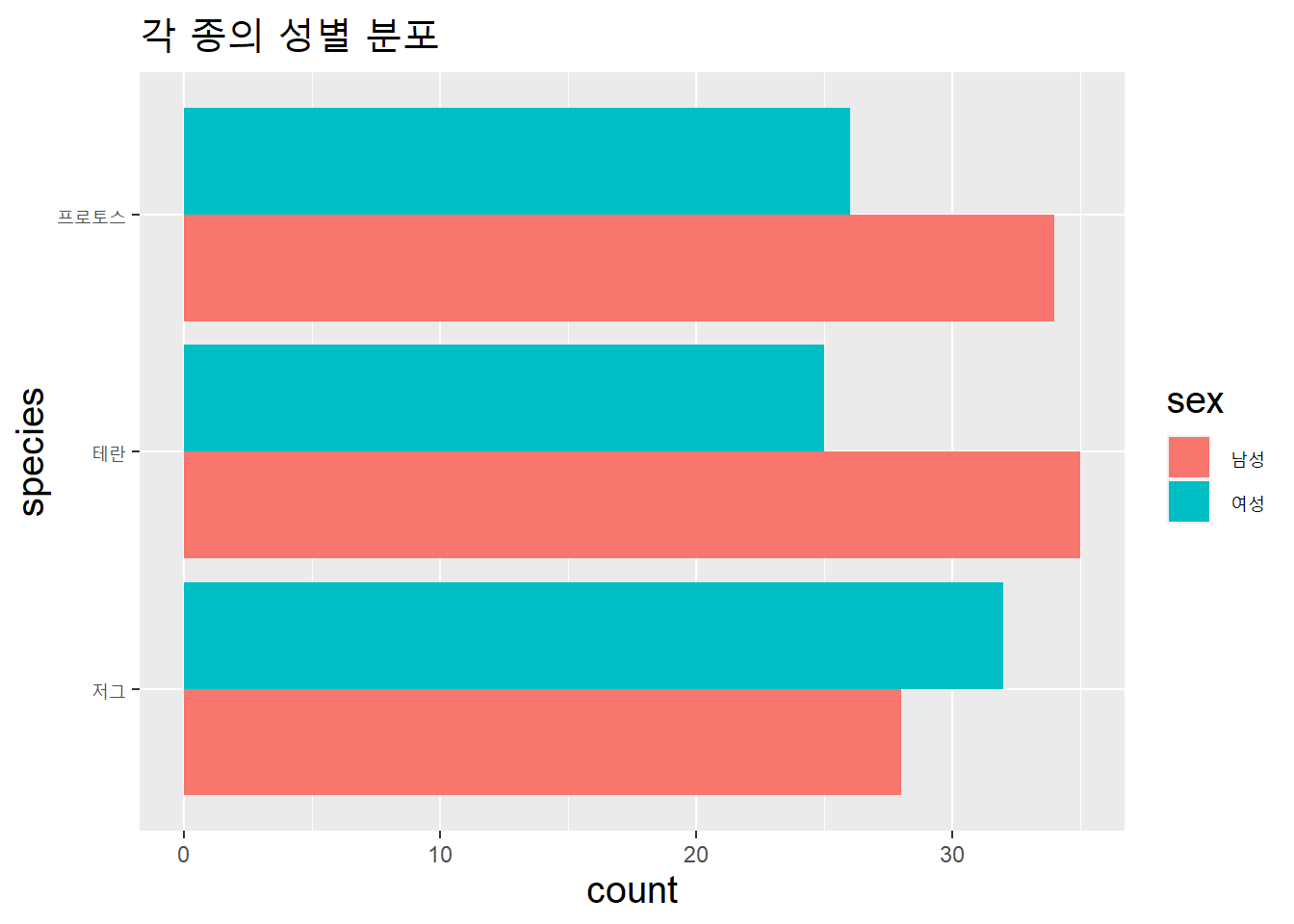
2.7.2 숫자형 벡터
갑돌이는 이제 나이, 복용량, 기력 등 숫자벡터 3종만 만들면 된다.
2.7.2.1 나이
연구참여자들이 특정 나이대에 편중되지 않도록 하기 위해 나이는 균등분포(uniform distribution)를 이루도록 자료를 생성했다. 균등분포는 시행의 결과값이 주어진 구간에 균등하게 나타나는 분포다.
성인 대상으로 자료를 수집할 계획이라 최소값은 21로 설정했고, 저그들의 사회활동을 고려해 최고값은 50으로 설정했다.
set.seed(55)
age_v <- runif(n = 180, min = 21, max = 50) %>%
as.integer() # 나이는 정수나이는 변수의 속성에 절대 영점(0)이 포함돼 있어 실질적인 값(비율)을 반영한 비율척도로 측정한 연속변수다. 연속변수는 막대도표가 아니라 히스토그램(geom_histogram())으로 시각화한다. 값이 연속적으로 분포하기 때문에 값들을 구간(bins =)으로 묶어야 시각화할 수 있기 때문이다.
data.table(x = age_v) %>%
ggplot(aes(x)) + ylim(0, 50) +
geom_histogram(bins = 5) + # 구간을 5개로 설정
labs(title = "나이의 히스토그램(구간 5개)") +
theme(title = element_text(size = 15))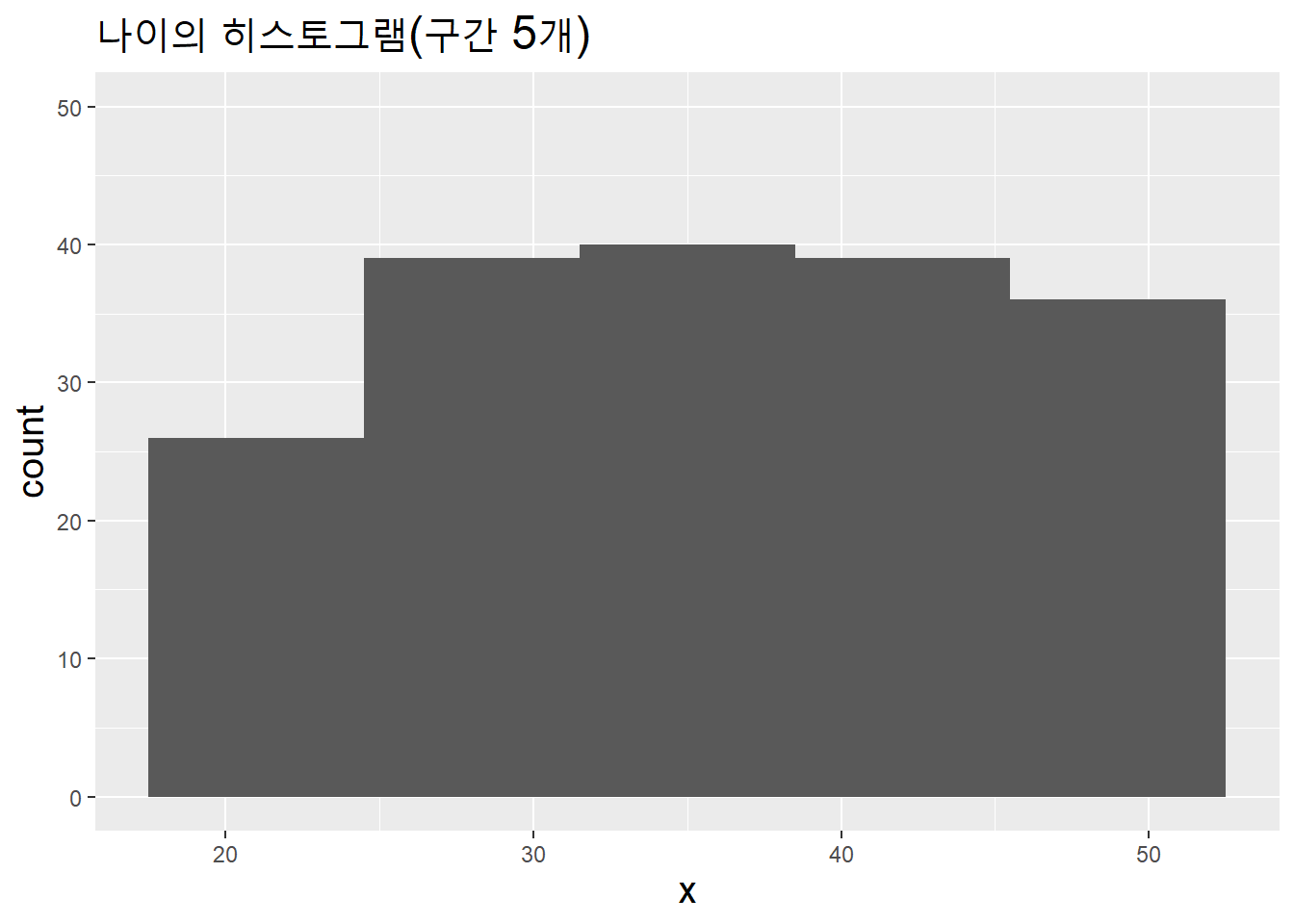
히스토그램은 연속하는 값의 시각화이므로 막대도표와 달리 구간과 구간 사이의 빈 간격이 없다. 다만 구간을 강조하기 위해 테두리를 색으로 표시할수 있다. 색 선택은 colorbrewer2 활용.
data.table(x = age_v) %>%
ggplot(aes(x)) + ylim(0, 50) +
geom_histogram(bins = 5, fill = "#636363", color = "#bdbdbd") +
labs(title = "나이의 히스토그램(구간 5개)") +
theme(title = element_text(size = 15))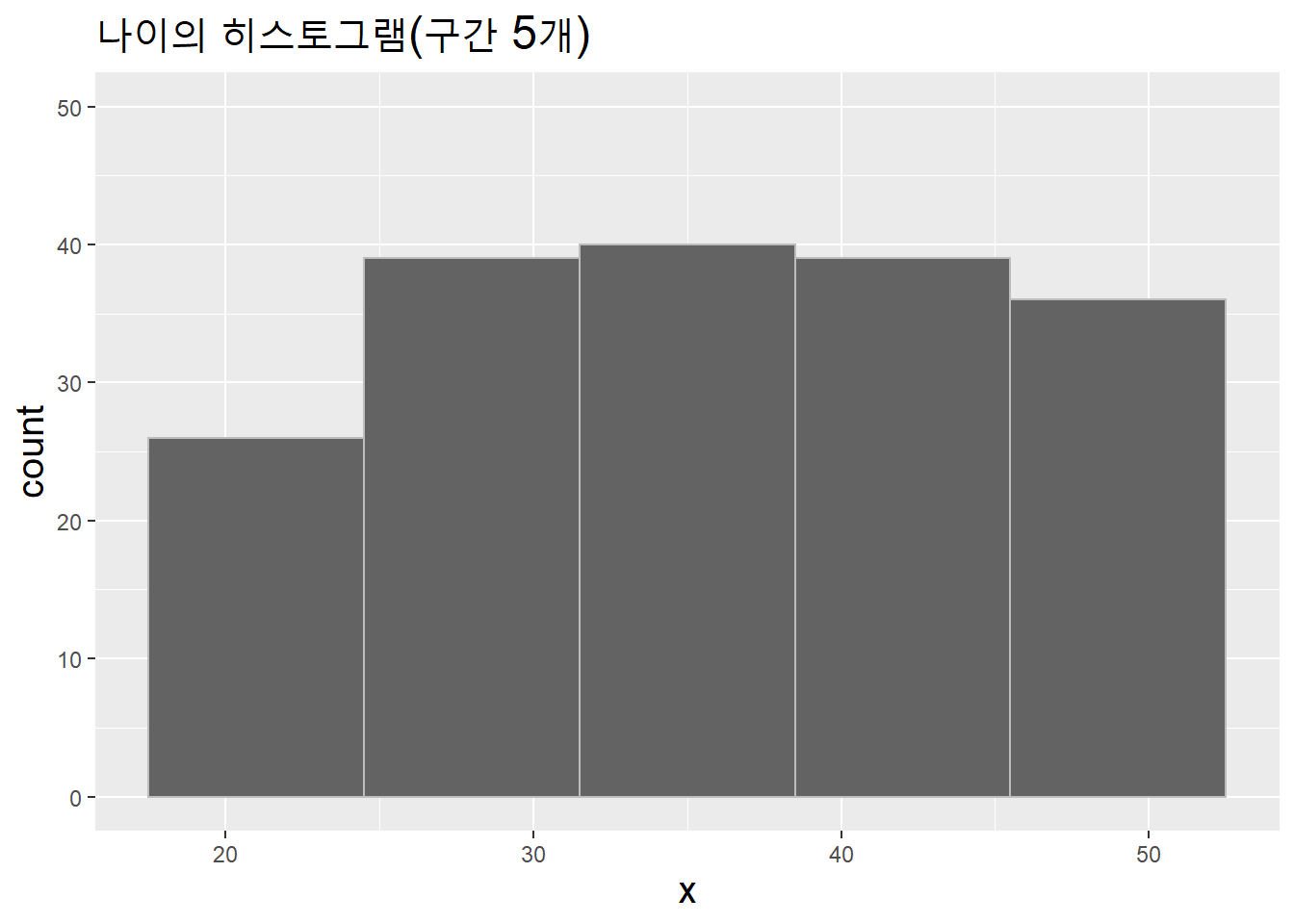
연속하는 값이므로 선을 이용해 표시할 수 있다. 값들이 선안에 밀도(density)있게 있기 때문에 밀도도표(density plot)이라고 한다.
data.table(x = age_v) %>%
ggplot(aes(x)) +
geom_density(aes(y = ..density..), fill = "red", alpha = .3) +
labs(title = "나이의 히스토그램과 밀도도표(구간 5개)") +
theme(title = element_text(size = 15))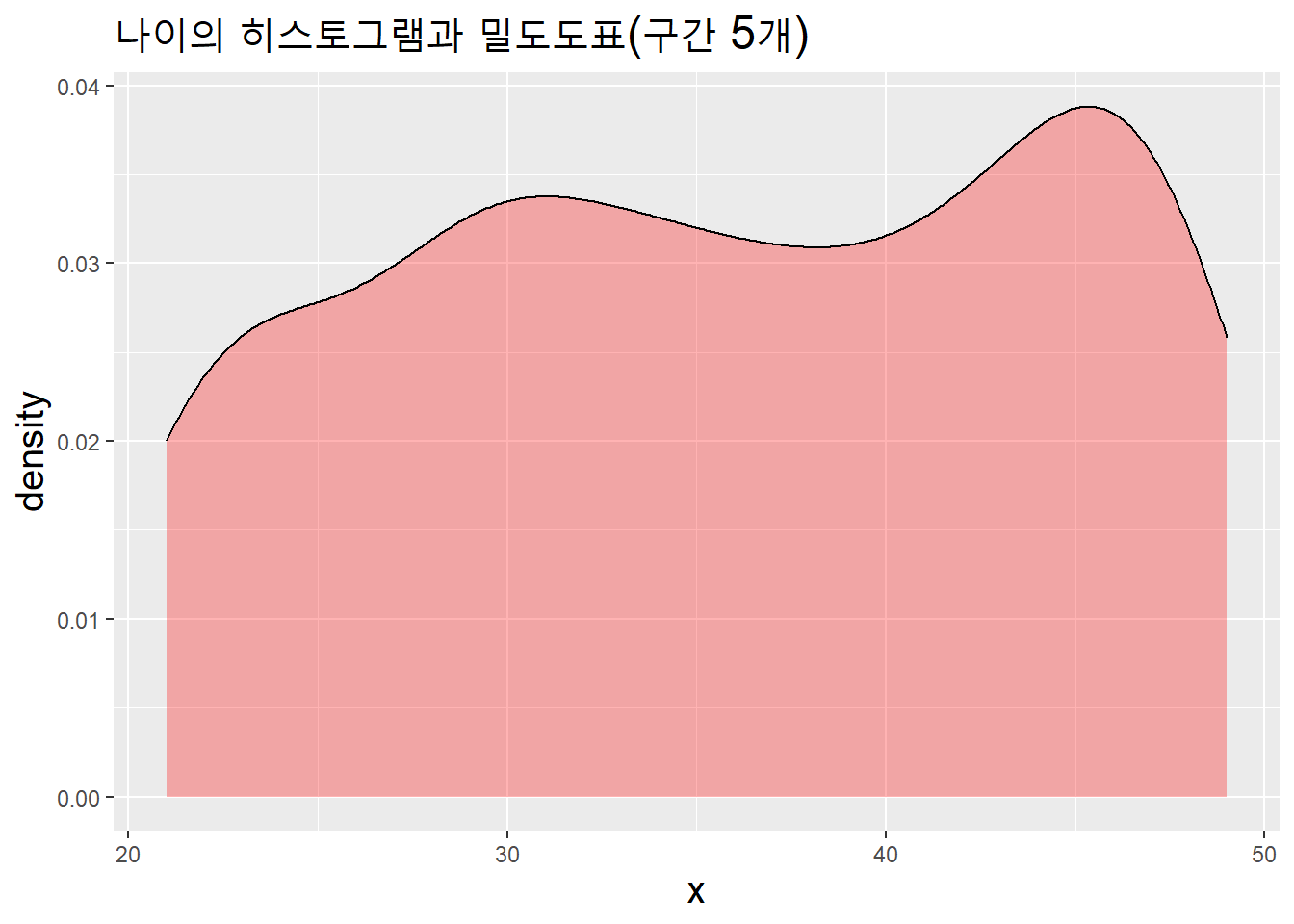
히스토그램 위에 겹쳐 그려보자. (밀도도표를 히스토그램 위에 그릴 때는 aes(y = ..density..)를 geom_histogram()에 투입해야 밀도도표가 보인다. )
data.table(x = age_v) %>%
ggplot(aes(x)) +
geom_histogram(aes(y = ..density..), bins = 5,
fill = "#636363", color = "#bdbdbd") +
geom_density(fill = "red", alpha = .3) +
labs(title = "나이의 히스토그램과 밀도도표(구간 5개)") +
theme(title = element_text(size = 15))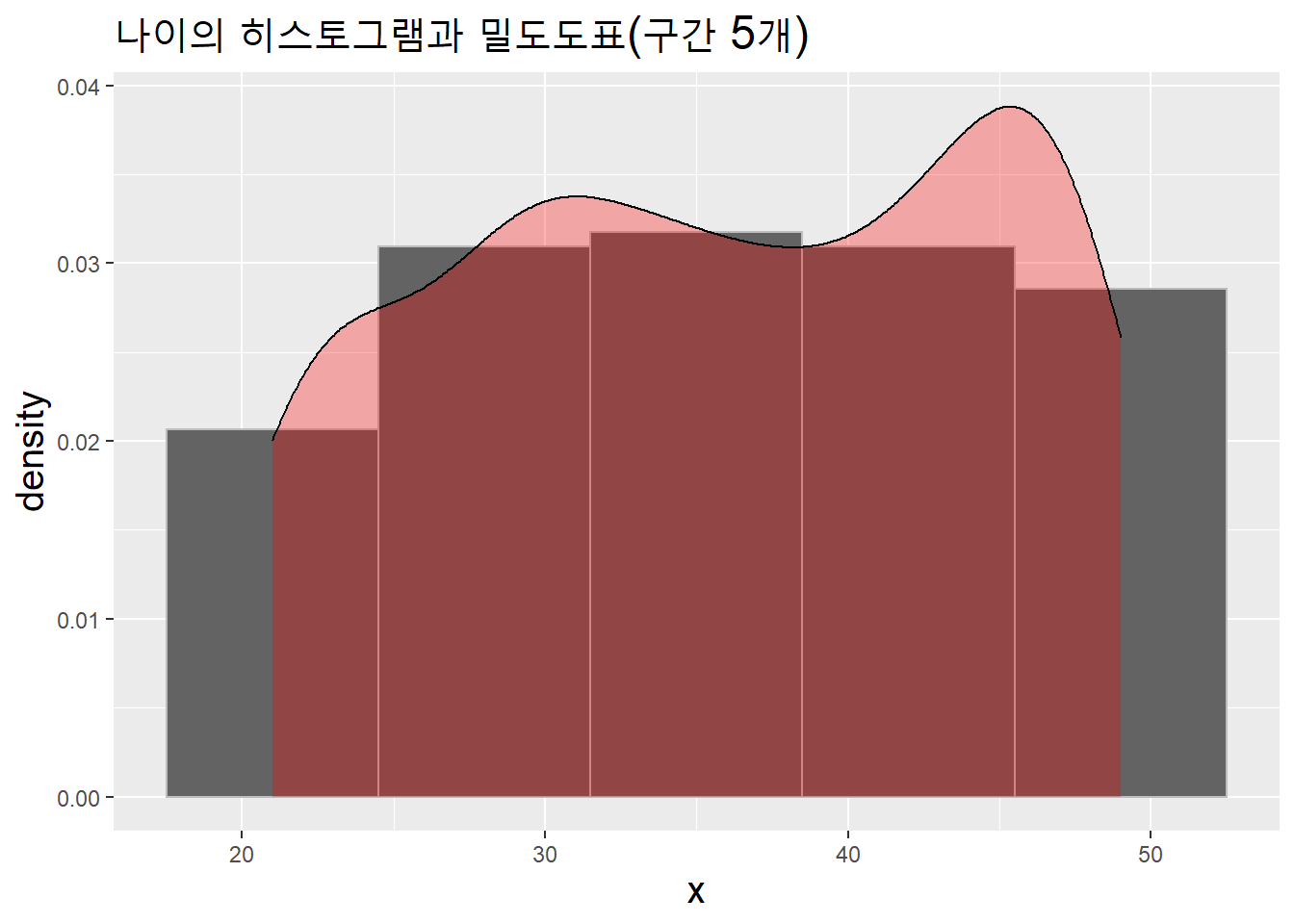
균등분포인데 분포가 그다지 균등하지 않은 이유는 값의 개수가 충분히 많지 않기 때문이다. 값의 개수를 크게 늘리면 거의 온전한 균등분포가 나타난다.
big_v <- runif(n = 180000, min = 21, max = 50) %>%
as.integer() # 나이는 정수
data.table(x = big_v) %>%
ggplot(aes(x)) +
geom_histogram(aes(y = ..density..), bins = 30,
fill = "#636363", color = "#bdbdbd") +
geom_density(fill = "red", alpha = .3) +
labs(title = "히스토그램과 밀도도표(구간 30개)") +
theme(title = element_text(size = 15))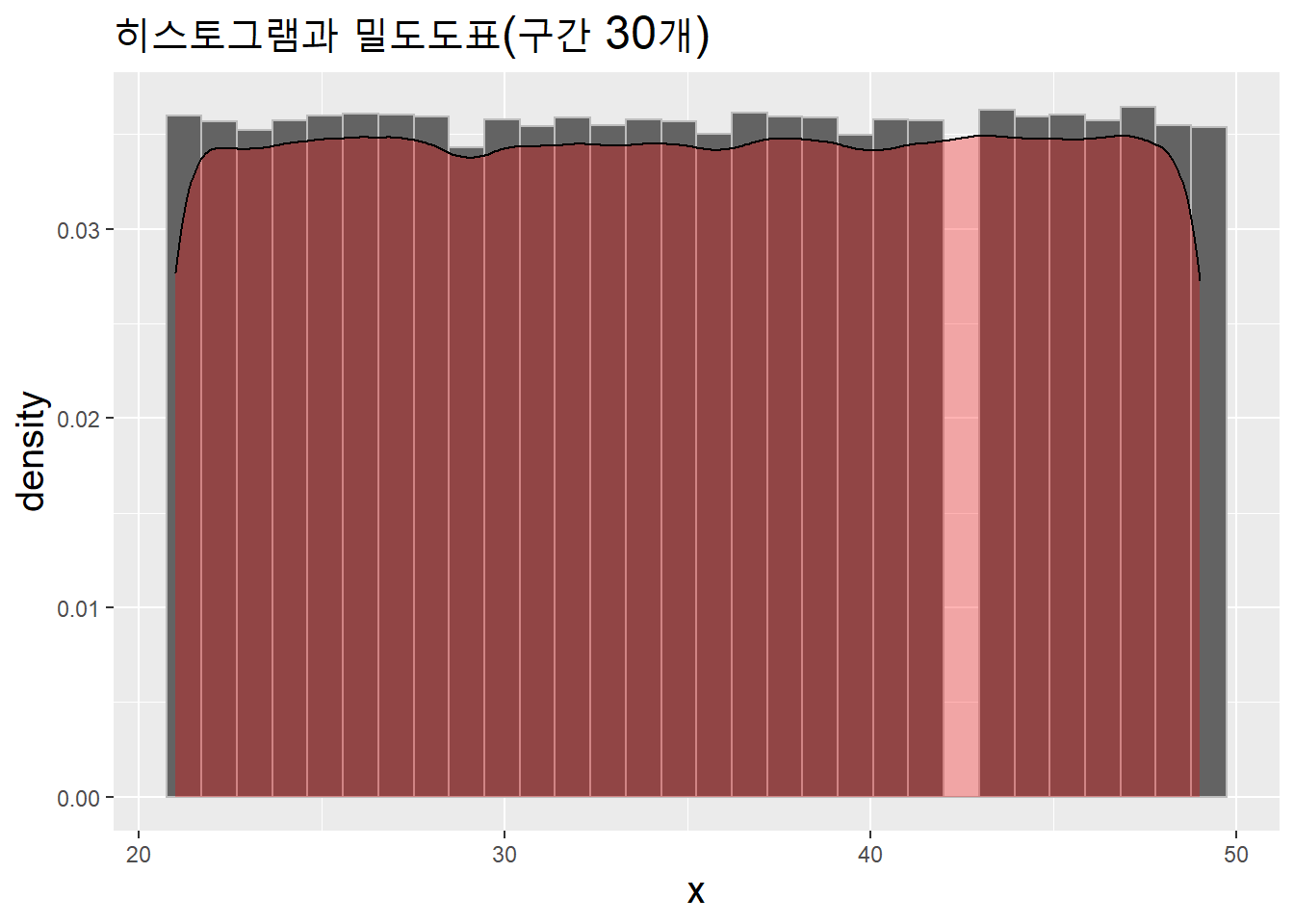
2.7.2.2 복용량과 기력
복용량은 연구참여자들마다 실제로 먹는 양을 측정할 것이므로 비율척도로 측정한다. 반면, 기력은 IQ와 같은 지수를 만들어 측정할 것이므로 등간척도로 측정한다. 등간척도나 비율척도로 측정한 변수는 분석에 이용하는 분석방법에는 차이가 없다.
분포는 균등분포가 아니라 정규분포를 이루는 값으로 만들기로 했다. 현실의 세계에서 많이 발생하는 분포이기 때문이다.
정규분포(normal distribution): 봉우리가 하나이고 좌우 대칭인 종모양의 곡선을 이루는 확률분포다. 정규분포는 다양한 사회현상이나 자연현상에 나타나므로 실생활에서 자주 접할수 있는 확률분포다. 평균이 0이고, 표준편차가 1인 정규분포를 표준정규분포라고 한다.
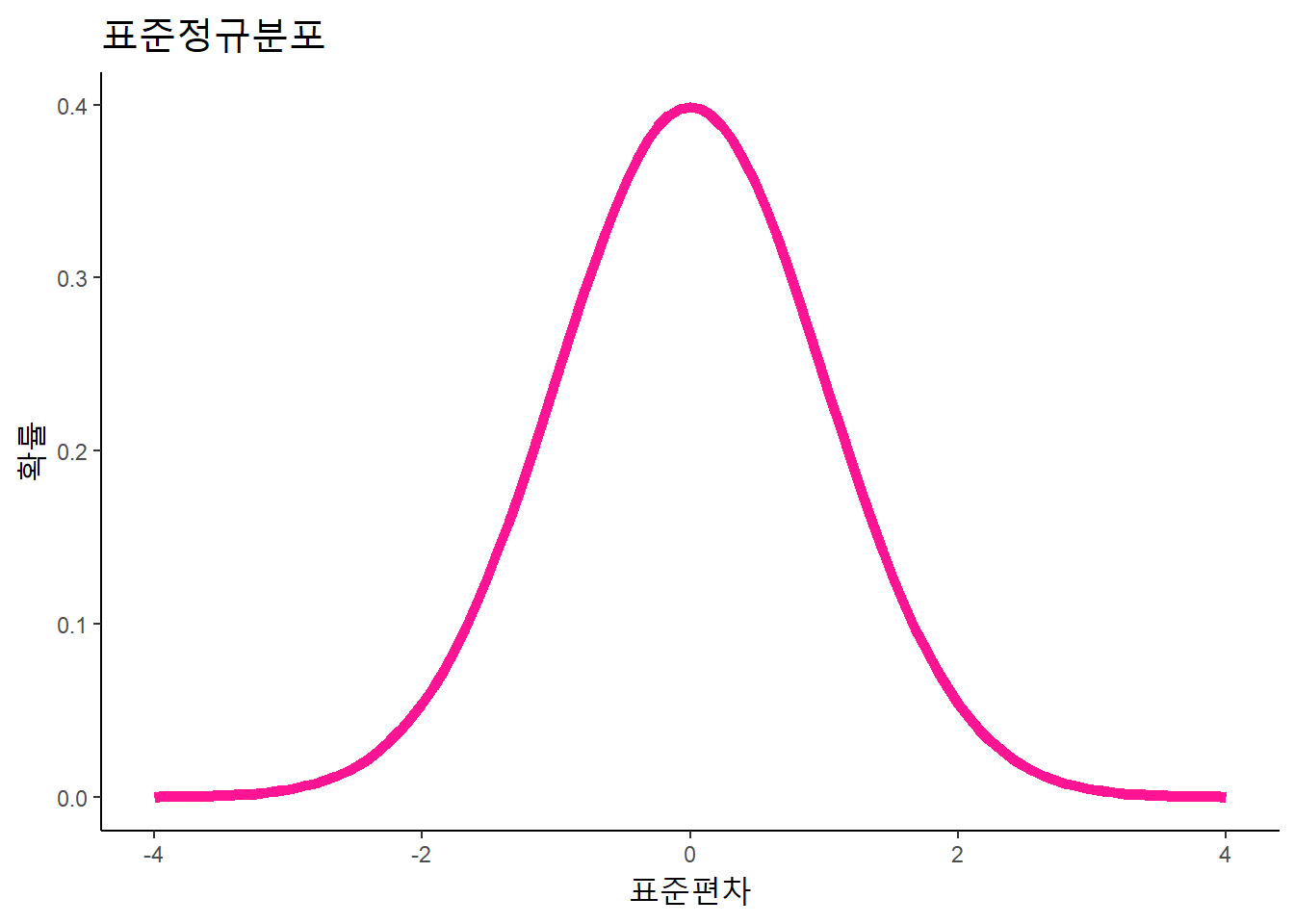
도표의 모양은 theme_계열 함수를 통해 다양하게 지정 가능. theme_ 용법 참조.
정규분포를 이루는 임의 값은 rnorm(n, mean, sd)함수로 만든다. rnorm()은 값의 개수(n)을 지정해 ’정규분포(normal distribution)를 만들라’는 명령을 컴퓨터에 전달하는 함수다. 예를 들어, 정규분포를 이루는 평균 10, 표준편차 4을 이루는 500개의 값으로 이뤄진 벡터를 만들기 위한 코드는 다음과 같다.
rnorm(n = 500, mean = 10, sd = 4)갑돌이는 그동안 저그마을에 머물며 이들의 행동을 관찰한 결과 보통 40단위 정도를 먹는 것을 알게됐다. 표준편차는 5정도 되는 것 같았다. 기력은 평균이 100이고 표준편차가 10인 기력척도를 이용하기로 했다.
set.seed(37)
dose_v <- rnorm(n = 180, mean = 40, sd = 5)
set.seed(37)
vigor_v <- rnorm(n = 180, mean = 100, sd = 10)복용량의 히스토그램과 밀도도표를 그려보자.
data.table(x = dose_v) %>%
ggplot(aes(x)) +
geom_histogram(aes(y = ..density..), bins = 10,
fill = "#636363", color = "#bdbdbd") +
geom_density(fill = "blue", alpha = .3) + # alpha는 투명도
labs(title = "복용량의 히스토그램과 밀도도표(구간 10개)") +
theme(title = element_text(size = 15))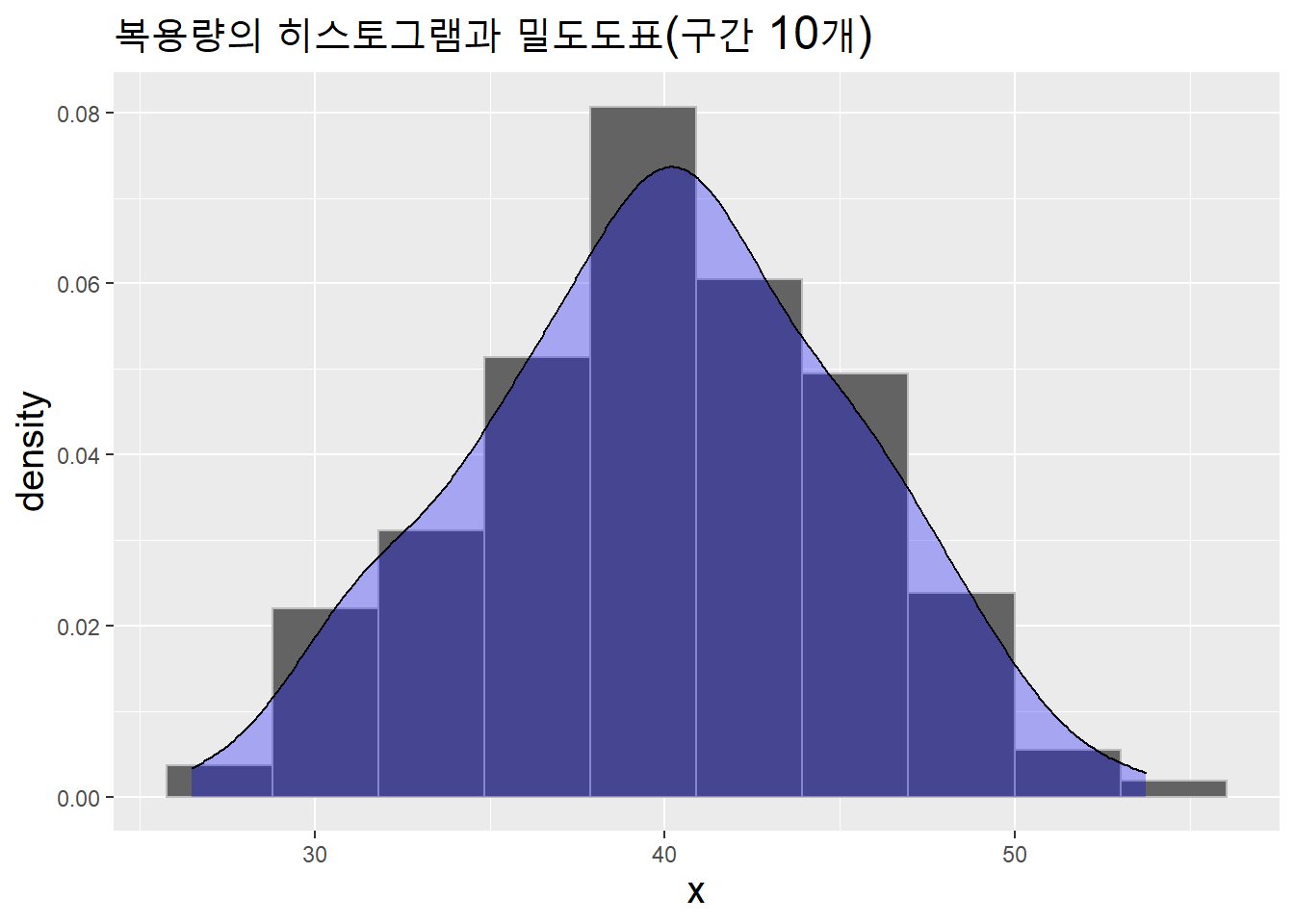
기력의 히스토그램과 밀도도표도 그리자.
data.table(x = vigor_v) %>%
ggplot(aes(x)) +
geom_histogram(aes(y = ..density..), bins = 10,
fill = "#636363", color = "#bdbdbd") +
geom_density(fill = "green", alpha = .3) + # alpha는 투명도
labs(title = "기력의 히스토그램과 밀도도표(구간 10개)") +
theme(title = element_text(size = 15))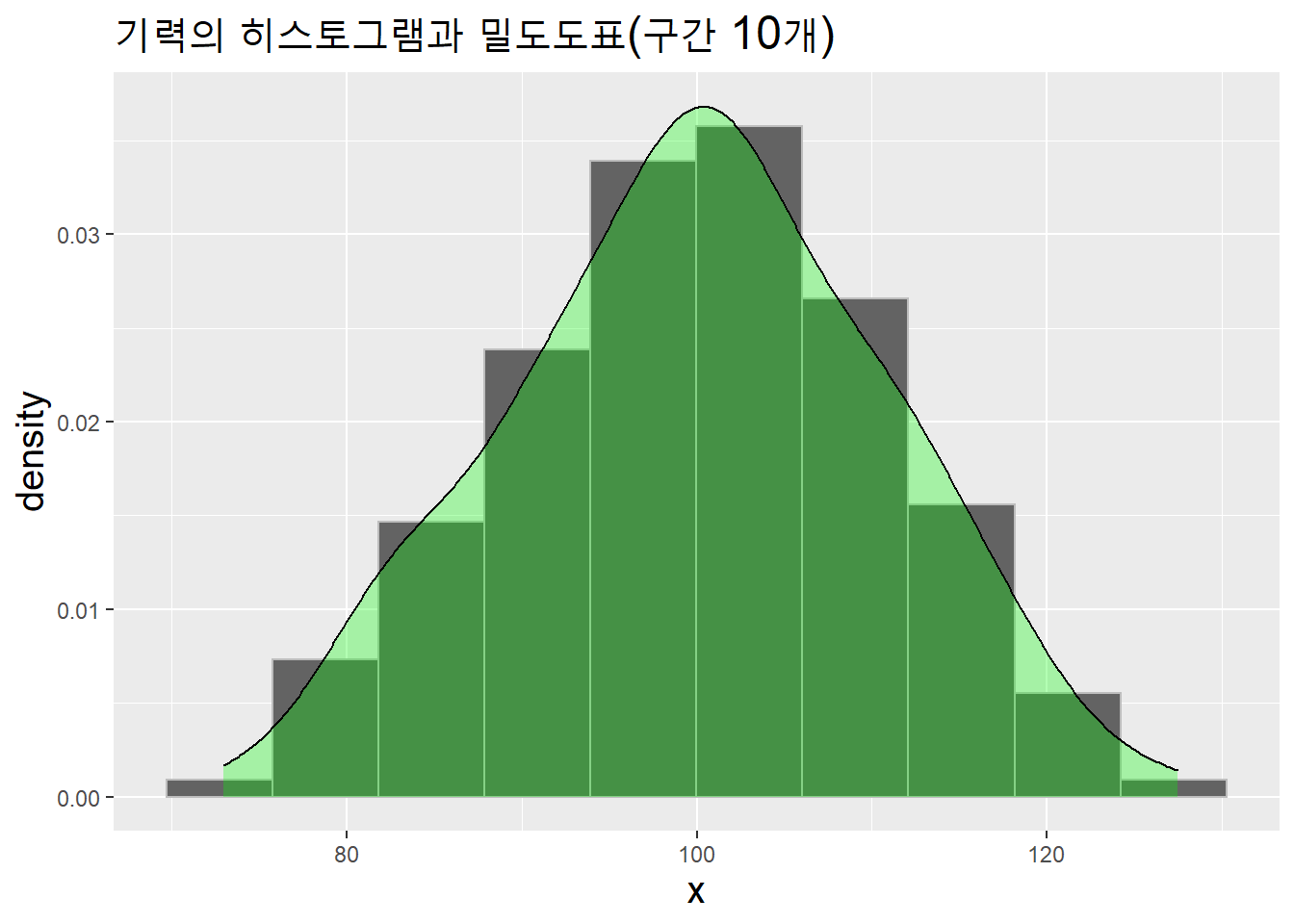
갑돌이는 모의분석을 위한 가상의 데이터셋을 거의 완성했다. 이제 데이터프레임으로 결합해 파일로 저장하면 된다. 저장폴더를 지정하지 않으면 작업디렉토리에 생성된다.
# ID와 종별 자료 생성
id <- c("저그", "테란", "프로토스")
nn <- 60
id_v <- vector()
species_v <- vector()
for(i in seq_along(id)){
o_id <- paste0(id[i], 1:nn)
o_sp <- rep(id[i], nn)
id_v <- c(id_v, o_id)
species_v <- c(species_v, o_sp)
}
# 성별 자료 생성
set.seed(73737)
sex_v <- rbinom(n = 180, size = 1, prob = .5)
# 나이 자료 생성
set.seed(55)
age_v <- runif(n = 180, min = 21, max = 50) %>%
as.integer()
# 복용량과 기력자료 생성
set.seed(37)
dose_v <- rnorm(n = 180, mean = 40, sd = 5)
set.seed(37)
vigor_v <- rnorm(n = 180, mean = 100, sd = 10)
# 데이터프레임으로 결합
data.table(
id = id_v,
sex = sex_v,
species = species_v,
age = age_v,
dose = dose_v,
vigor = vigor_v
) -> df
# 엑셀파일로 저장(작업디렉토리에 저장)
rio::export(df, "df.xlsx")코딩스타일
객체에 할당하는 방향이 오른쪽-> 혹은 <- 왼쪽 모두 가능하다. 객체를 오른쪽에 할당하면 사고의 흐름과 일치하는 장점이 있고, 왼쪽에 할당하면 할당한 객체가 무엇인지 읽기 편한 장점이 있다. 따라서 df 등 임시로 만들어 쓰는 객체는 오른쪽에 할당하고, age_v처럼 여러번 사용하는 객체는 왼쪽에 할당하는 것이 좋다.
2.8 가져오기 및 정제(전처리)
갑돌이는 모의분석에 필요한 자료생성을 마쳤다. 이제 수집한 자료를 분석할 차례다.
먼저 저장한 파일을 R환경으로 가져오자.
rio::import("df.xlsx") -> dfR환경에 탑재된 자료는 분석하기 앞서 먼저 자료를 살펴보고 분석할 수 있도록 정제 작업을 한다. 결측값을 처리하거나 문항들을 결합해 변수를 생성하거나 자료구조나 자료 유형 등을 변경하는 작업 등이 포함된다.
str(df)## 'data.frame': 180 obs. of 6 variables:
## $ id : chr "저그1" "저그2" "저그3" "저그4" ...
## $ sex : num 0 0 1 1 1 0 0 0 1 1 ...
## $ species: chr "저그" "저그" "저그" "저그" ...
## $ age : num 36 27 22 43 37 23 24 29 35 23 ...
## $ dose : num 40.6 41.9 42.9 38.5 35.9 ...
## $ vigor : num 101.2 103.8 105.8 97.1 91.7 ...head(df, 3)## id sex species age dose vigor
## 1 저그1 0 저그 36 41 101
## 2 저그2 0 저그 27 42 104
## 3 저그3 1 저그 22 43 106갑돌이가 자료를 생성했기 때문에 결측값은 없다. 변수를 생성했기 때문에 문항을 결합해 변수를 생성할 필요도 없다. 데이터프레임이므로 자료구조를 바꾸지 않아도 된다. 다만, 변수 중 자료유형을 바꿔야 하는 것이 하나 있다. sex변수다. 성은 명목척도로 측정한 불연속변수다. 그런데, 숫자로 저장돼 있다. 따라서, 숫자형은 범주형(요인)으로 바꾸는 것이 원칙이다. 종도 문자형으로 돼 있으므로 요인형으로 변경한다.
정제단계에서 가장 많이 활용하는 패키지가 dplyr다. 이중 변수를 추가하거나 변경하는데 사용하는 함수는 mutate()함수. mutate.()함수는 처리 속도를 더 빠르게 개선한 tidytable패키지 함수. 용법은 거의 같다.
df %>%
mutate.(
sex = factor(sex, labels = c("남성", "여성")),
species = factor(species)
) -> df
str(df)## Classes 'tidytable', 'data.table' and 'data.frame': 180 obs. of 6 variables:
## $ id : chr "저그1" "저그2" "저그3" "저그4" ...
## $ sex : Factor w/ 2 levels "남성","여성": 1 1 2 2 2 1 1 1 2 2 ...
## $ species: Factor w/ 3 levels "저그","테란",..: 1 1 1 1 1 1 1 1 1 1 ...
## $ age : num 36 27 22 43 37 23 24 29 35 23 ...
## $ dose : num 40.6 41.9 42.9 38.5 35.9 ...
## $ vigor : num 101.2 103.8 105.8 97.1 91.7 ...
## - attr(*, ".internal.selfref")=<externalptr>head(df, 3)## # A tidytable: 3 x 6
## id sex species age dose vigor
## <chr> <fct> <fct> <dbl> <dbl> <dbl>
## 1 저그1 남성 저그 36 40.6 101.
## 2 저그2 남성 저그 27 41.9 104.
## 3 저그3 여성 저그 22 42.9 106.2.9 종합
2.9.1 과학
실재와 인식. 부분과 맥락. 대상을 한가지 방식으로만 보지 말고 다양한 관점, 다양한 수준에서 관찰할 필요가 있다.
착시는 시각적인 현상일뿐 아니라, 숫자와 통계에도 있다.
2.9.2 코딩
- 도표
- par()
- plot()
- ggplot2
- geom_point()
- geom_smooth()
- geom_bar()
- geom_histogram()
- geom_density()
- coord_flip()
- xlim()
- ylim()
- labs()
- theme()
- patchwork
- scale_fill_brewer()
- scale_color_brewer()
- geom_point()
- 자료의 유형과 구조
- 숫자형, 문자형, 논리형
- as.integer()
- as.character()
- as.logical()
- NA, NULL, NaN, Inf
- as.integer()
- 벡터, 데이터프레임, 매트릭스, 배열, 리스트
- c()
- data.frame()
- data.table()
- matrix()
- array()
- list()
- c()
- 요인(factor)
- levels =
- labels =
- str()
- 부분선택(subsetting)
- [ ]
- [[ ]]
- $
- filter.()
- select.()
- [ ]
- 분포함수
- rbinom()
- runif()
- rnorm()
- 가져오기/자료조작
- rio
- import()
- export()
- import()
- dplyr vs. tidytable
- mutate.()
- mutate.()
- 함수의 함수
- apply()
- laplly()
- sapply()
2.10 연습
- 다음 변수를 측정하기 위해서는 어느 측정수준의 척도를 이용해야 하는가?
- 성정체성(gender): 남성성과 여성성의 정도
- 만 나이
- 세대(청년, 중년, 노년 등)
- 수능점수
- 자료구조
갑돌이는 저그들의 성정체성을 프로토스의 성정체성과 비교하려고 한다. 이를 위해 저그와 프로토스 2000명을 대상으로 설문조사를 할 계획이다. 갑돌이가 필요한 자료구조는 무엇인가?
- 아래 코드는 오류 때문에 작동하지 않는다. 틀린 곳을 찾아내고, 몇개인지 제시하시오.
anscombe %>%
ggp1ot(aes(x2. y2) %>%
geom_Point() %>%
geom_smooth(methd = lm)- 시각화
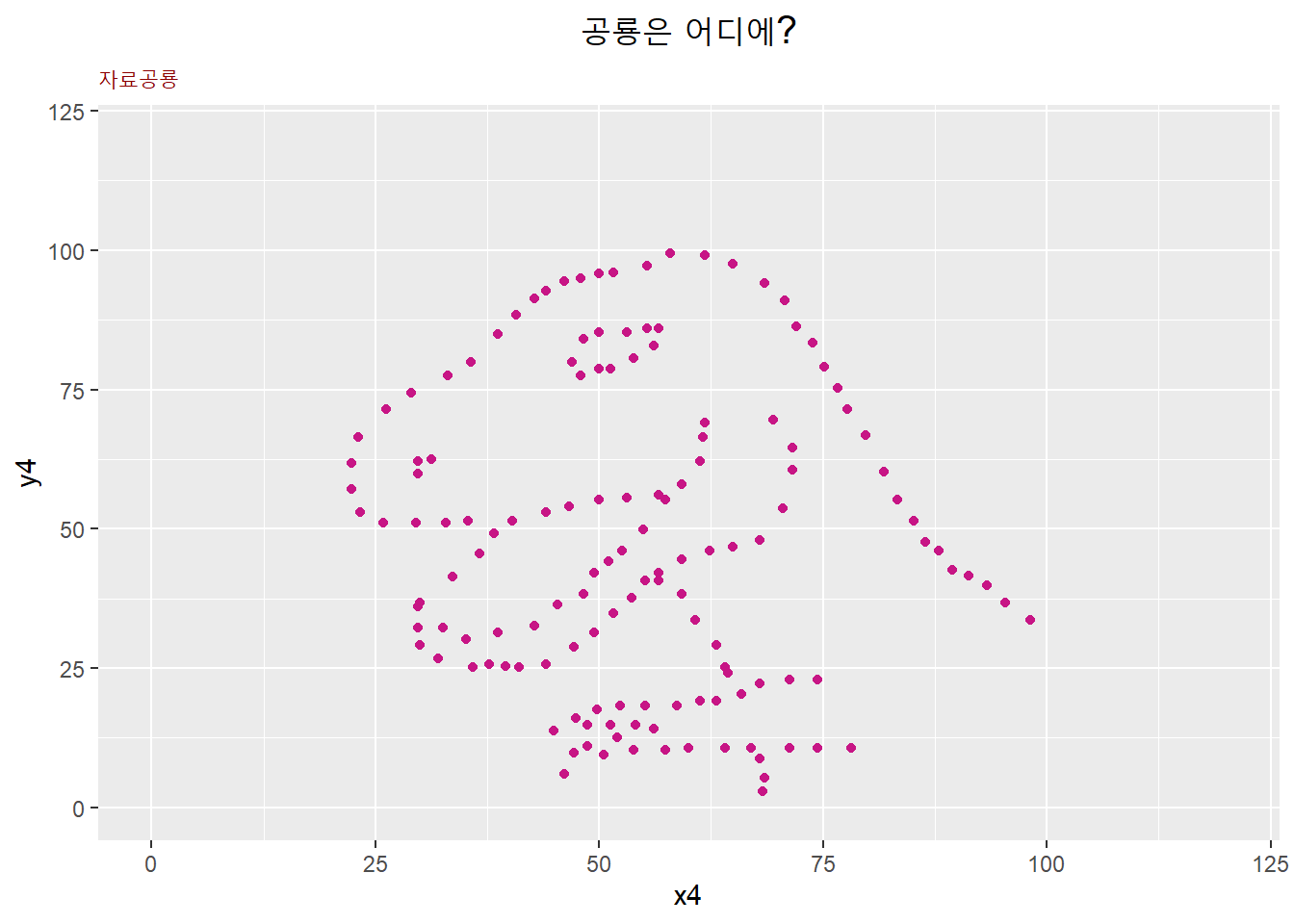
안스콤의 4개조에 영감을 받은 후대의 연구자들이 시각화의 중요성을 보다 흥미롭게 나타내기 위해 산점도로 공룡 등 다양한 기하모형이 나타나는 데이터셋을 구성했다(Matejka and Fitzmaurice 2017). 안스콤의 4개조처럼 모두 평균, 표준편차 및 상관계수가 같다 (Figure 2.6).

Figure 2.6: 자료공룡과 통계치
자료공룡 데이터셋에는 모두 13쌍, 즉 26개의 열이 있다. 이 데이터셋에서 공룡모양을 이루는 x열과 y열을 선택해 아래와 같은 산점도로 표시하시오 (점 및 도표의 제목의 색, 크기, 및 위치는 자율적으로 설정한다.)
먼저, 데이터셋을 R환경 안으로 가져오기를 한다. 가져오기 도구는 다양한데, 여기서는 rio패키지의 import()함수를 이용한다. 데이터형식에 구애받지 않고 가져오기가 가능한 장점이 있다.
산점도를 13개 모두 표시하기에는 화면 크기가 넉넉하지 않으므로, 먼저 6쌍의 열만 부분선택해서 나눠서 살펴보는 것도 방법이다.
if(!require(rio)) install.packages("rio")
url <- "https://raw.githubusercontent.com/dataminds/art/main/files/dino12xy.csv"
rio::import(url) %>%
# x1열부터 y6열까지 12개열 부분선택
select(x1:y6) -> dino_df 공룡 산점도를 찾기 위해서는 앞서 안스콤 4개조 산점도를 그리는데 사용한 코드(아래)를 쓸 수 있지만, 데이터가 조금 다르기 때문에 그대로 사용하면 안된다.
p <- lapply(1:4, function(i) {
x <- anscombe[, i]
y <- anscombe[, i + 4]
ggplot() +
geom_point(aes(x, y)) +
labs(subtitle = str_glue("변수{i}"))
})
px와 y열 쌍이 안스콤 4개조에서는 x1~x4, y1~y4로 따로 떨어져 있지만, 자료공룡에서는 x열과 y열이 나란히 배치돼 있다.
# 안스콤 4개조의 열
names(anscombe)## [1] "x1" "x2" "x3" "x4" "y1" "y2" "y3" "y4"# 자료공룡의 열
names(dino_df)## [1] "x1" "y1" "x2" "y2" "x3" "y3" "x4" "y4" "x5" "y5" "x6" "y6"함수를 실행하는 범위(1:4)를 자료공룡에 맞게 수정해야 한다. 당연히 데이터의 이름도 그대로 쓰면 안된다.
힌트: seq()함수를 이용하면 된다.