7 가설검정
c(
"rio", "tidyverse", "tidytable", "psych", "psychTools",
"skimr", "janitor", "tidymodels", "lm.beta", "mediation",
"GGally", "ggforce", "mdthemes", "patchwork", "ggdag",
"r2symbols", "equatiomatic", "gt"
) -> pkg
sapply(pkg, function(x){
if(!require(x, ch = T)) install.packages(x, dependencies = T)
library(x, ch = T)
})7.1 실재와 모형에 대한 과학적 접근
실재와 모형의 관계를 실제 사례에 적용해 보자.
사람들은 종종 자신에게 손해가 되는 행동을 선택한다. 자신의 자원을 다른 사람을 위해 내놓는다. 기부한만큼 자신의 자산이 줄어든다.
여기서 관측된 현상은 사람들의 손해를 보는 행동에 대한 자발적 선택이다. 이 관측된 현상은 우리 마음 속에 비친 그림자다. 이 그림자의 실재는 과연 무엇일까? 그 판단을 위해서는체계적 논리와 체계적 경험이 필요하다.
체계적 논리: 역인과관계 가능성과 허위관계 가능성을 배제해 모순없이 구성된 원인과 결과의 관계
체계적 경험: 타당하고도 신뢰성있는 방법으로 자료를 생성하고 분석해 정보를 생성함으로써 논리적으로 기대되는 관계에 대해 제시한 근거
7.1.1 체계적 논리
’자발적 손해’에 해당하는 친사회적 행동에 대해 독일 막스플랑크 연구소의 진화인류학자들은 집단 평판(group reputation)을 이용해 설명한다 (Engelmann, Herrmann, and Tomasello 2018).
직장 동료, 결혼 상대 등 사람들은 협력적인 사람을 선호한다. 사람들은 평판을 통해 그 사람이 협력적인지 아닌지 판단하기에, 모든 사람들에게는 좋은 평판을 만들고 유지하려는 동기가 있다. 좋은 평판이 만들어지고 유지되려면 자신의 친사회적 행동이 다른 사람들이 그 행동을 알아줘야 한다. 따라서 평판에 대한 관심이 사람들은 긍정적인 평판을 만들고 유지하려는 동기가 친사회적 행동을 촉진한다. 자신의 행동이 다른 공개적인 때 더 친사회적인 행동을 하게 되는 이유다.
개인은 자신의 집단에 동일시한다. ’나’의 행동이 곧 ’내가 속한 집단’의 행동이 된다. ’나’에게 돌아오는 직접적인 이익이 없어도, 그것이 집단의 평판에 도움이 된다면, 그것이 곧 ’나’의 이익으로 이어지기 때문이다. 즉, 친사회적 행동이 개인평판 뿐 아니라, 집단 향상에 기여할 수 있다면, 비록 개인의 평판에 직접적으로 도움이 되지는 않아도, 개인은 친사회적 행동을 선택할 가능성이 높다.
7.1.2 체계적 경험
경험의 체계성은 타당하고도 신뢰성있는 방법으로 자료를 생성하고 분석해 정보를 생성함으로써 논리적으로 기대되는 관계에 대한 근거를 제시하는데에 있다.
7.1.2.1 측정(자료의 생성)
자료 생성은 타당하고도 신뢰성있는 방법이어야 한다. 인과추론을 위한 기본적인 방법은 처치집단과 대조집단을 비교하는 실험이다. 가장 이상적인 실험은 무작위대조시험(RCT: Randomized Controlled Trial)이다. 처치집단과 대조집단에 측정대상을 무작위(random)로 할당해 독립변수로 작용하는 요소 이외의 요소를 가능한 모두 통제할 수 있도록 하기 때문이다.
실험을 위해서는 먼저 추상적인 개념(독립변수와 종속변수)를 측정할 수 있도록 구체화해야 한다. 추상적인 개념을 측정가능하게 구체화하는 작업을 조작화(operationalization)하고 한다.
- 종속변수(결과): 친사회성
- 친사회성 조작: 자신의 물건(장난감)을 모르는 사람에게 기부하는 횟수
- 독립변수(원인): 집단평판에 대한 관심
- 집단조작: 3명이 한 조 형성해 참가자들이 집단에 대한 소속감 부여
- 평판조작: 기부행위가 보이도록 만들어 평판에 대한 관심 형성
- 성과 나이는 혼란변수(confounder)로서 통제
표본
어린이 120명(5세).
대조(처치의 통제)
실험집단은 다음 4개의 집단이 만들어진다.
- 처치집단1: 집단평판o + 개인평판x
- 처치집단2: 집단평판o + 개인평판o
- 대조집단1: 집단평판x + 개인평판o
- 대조집단2: 집단평판x + 개인평판x
무작위 할당
연구에 참여한 표본(어린이 120명)을 4개 집단에 무작위 할당.
7.1.2.2 불러오기 및 정제(전처리)
측정을 완료하면 데이터셋이 생성된다. 이를 R환경에 불러와 데이터프레임으로 저장한다.
url <- "https://raw.githubusercontent.com/dataminds/art/main/files/group_reputation.xlsx"
rio::import(url) -> df
str(df)## 'data.frame': 120 obs. of 8 variables:
## $ child.id : num 1 2 3 4 5 6 7 8 9 10 ...
## $ gender : chr "m" "m" "m" "f" ...
## $ age.months : chr "70" "69" "64" "70" ...
## $ age.days : num 30 1 7 2 28 30 13 28 27 7 ...
## $ individual_public : chr "no" "no" "no" "no" ...
## $ group_public : chr "no" "no" "no" "no" ...
## $ number.stickers.shared: num 3 0 0 5 4 5 6 5 5 0 ...
## $ comment : chr "Study 1" "Study 1" "Study 1" "Study 1" ...분석할 수 있도록 변수의 이름 정하고, 자료유형(숫자형, 요인 등)을 적절하게 조정한다. 데이터프레임에서 새로운 변수를 만들때 dplyr패키지의 mutate() 혹은 transmute()함수를 이용한다. mutate()함수는 새 변수를 만들고 기존 열을 유지하는 반면, transmute()함수는 새로운 변수를 만들면서 기존 열을 삭제한다.
df %>%
transmute.(
pro = number.stickers.shared,
sex = gender %>% as.factor(),
age = as.numeric(age.months) * 30 + age.days,
repu_ind = individual_public %>% as.factor(),
repu_grp = group_public %>% as.factor(),
# 실험조건 4개 별로 구분
cond = paste(repu_ind, repu_grp) %>% as.factor(),
) -> df실험조건별로 구분한 cond열의 no no, no yes 등의 의미를 알기 쉽게 변경한다. 값 변경은 recode()함수 이용.
df %>%
mutate(
cond = recode(
cond,
`no no` = "private",
`no yes` = "grp_only",
`yes no` = "ind_only",
`yes yes` = "both"
)) -> df7.1.2.3 탐색분석
본격적인 분석에 앞서 자료의 분포, 결측값 여부, 기술통계에 대해 살핀다.
skimr::skim(df)| Name | df |
| Number of rows | 120 |
| Number of columns | 6 |
| Key | NULL |
| _______________________ | |
| Column type frequency: | |
| factor | 4 |
| numeric | 2 |
| ________________________ | |
| Group variables | None |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| sex | 0 | 1 | FALSE | 2 | m: 62, f: 58 |
| repu_ind | 0 | 1 | FALSE | 2 | no: 72, yes: 48 |
| repu_grp | 0 | 1 | FALSE | 2 | yes: 72, no: 48 |
| cond | 0 | 1 | FALSE | 4 | grp: 48, pri: 24, ind: 24, bot: 24 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| pro | 0 | 1 | 4.86 | 2.68 | 0 | 4.00 | 5.0 | 6 | 10 | ▃▅▇▁▃ |
| age | 0 | 1 | 2003.56 | 83.36 | 1803 | 1949.25 | 2009.5 | 2058 | 2457 | ▂▇▃▁▁ |
psych::describe(df)## vars n mean sd median trimmed mad min max range skew
## pro 1 120 4.86 2.68 5.0 4.83 1.48 0 10 10 0.14
## sex* 2 120 1.52 0.50 2.0 1.52 0.00 1 2 1 -0.07
## age 3 120 2003.56 83.36 2009.5 2002.76 86.73 1803 2457 654 1.04
## repu_ind* 4 120 1.40 0.49 1.0 1.38 0.00 1 2 1 0.40
## repu_grp* 5 120 1.60 0.49 2.0 1.62 0.00 1 2 1 -0.40
## cond* 6 120 2.40 1.02 2.0 2.38 1.48 1 4 3 0.27
## kurtosis se
## pro -0.17 0.24
## sex* -2.01 0.05
## age 5.80 7.61
## repu_ind* -1.85 0.04
## repu_grp* -1.85 0.04
## cond* -1.08 0.09각 변수의 관계에 대해서도 탐색한다. .
GGally::ggpairs(df) 4개 실험조건
4개 실험조건cond와 기부횟수pro만 부분선택해 보자.
df %>% select.(pro, cond) %>% ggpairs()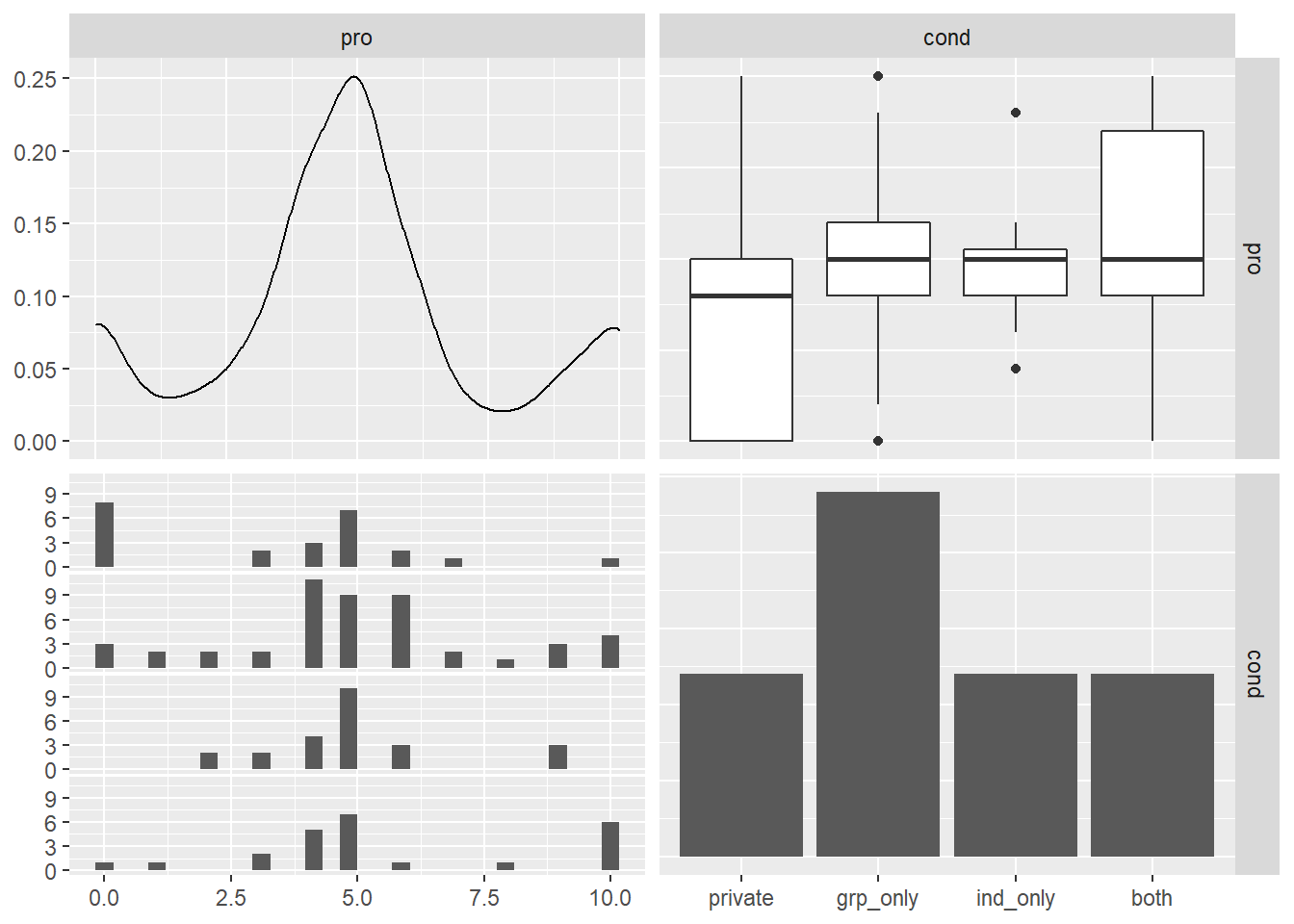
실험조건 별로 기부횟수의 평균과 표준편차를 구해 표로 정리하자.
df %>%
group_by(repu_ind, repu_grp) %>%
summarise(m = mean(pro), sd = sd(pro))tidytable패키지는 dplyr패키지와 대부분 함수 용법이 비슷하지만, dplyr의 group_by() 대신 .by =를 이용하는 점이 다르다.
df %>%
summarise.(m = mean(pro), sd = sd(pro),
.by = c(repu_ind, repu_grp)) %>%
gt() %>%
tab_header("실험조건별 기부횟수의 기술통계") %>%
fmt_number(3:4, decimals = 2)| 실험조건별 기부횟수의 기술통계 | |||
|---|---|---|---|
| repu_ind | repu_grp | m | sd |
| no | no | 3.42 | 2.81 |
| yes | no | 5.04 | 1.88 |
| no | yes | 5.08 | 2.60 |
| yes | yes | 5.67 | 2.97 |
df %>%
summarise.(m = mean(pro), sd = sd(pro),
.by = cond) %>%
gt() %>%
tab_header("실험조건별 기부횟수의 기술통계") %>%
fmt_number(2:3, decimals = 2)| 실험조건별 기부횟수의 기술통계 | ||
|---|---|---|
| cond | m | sd |
| private | 3.42 | 2.81 |
| ind_only | 5.04 | 1.88 |
| grp_only | 5.08 | 2.60 |
| both | 5.67 | 2.97 |
비(ratio)를 구해 처치집단의 기부횟수를 각 대조집단과 비교해보자. 데이터프레임의 값을 열로 변경해 비를 계산한다.
df %>%
summarise.(m = mean(pro),
.by = cond) %>%
pivot_wider.(names_from = cond, values_from = m) %>%
transmute.(`집단+개인평판/익명` = both / private,
`집단평판/개인평판` = grp_only / ind_only,
`집단평판/익명` = grp_only / private) %>%
pivot_longer.(names_to = "A_B", values_to = "Ratio") %>%
gt() %>%
tab_header("처치집단/대조집단 기부횟수 비(ratio)") %>%
fmt_number(2, decimals = 2)| 처치집단/대조집단 기부횟수 비(ratio) | |
|---|---|
| A_B | Ratio |
| 집단+개인평판/익명 | 1.66 |
| 집단평판/개인평판 | 1.01 |
| 집단평판/익명 | 1.49 |
평판과 협력의 논리적 관계에 대해 자료를 수집해 탐색적으로 분석한 결과, 평판에 대한 관심이 친사회적 행동을 촉진하는 것처럼 보인다.
집단평판 집단의 어린이들이 대조집단 어린이에 비해 1.49회 더 기부했고, 집단평판집단과 개인평판집단 어린이 사이에는 큰 차이가 없다.
그러나, 이 결과는 표본에 대한 요약이다. 이 결과를 모집단에도 적용할 수 있을까?
7.2 통계적 추론
표본의 값(관측된 값: 통계치)을 통해 모집단의 값(실제의 값: 모수치)으로 일반화하기 위해서는 통계적 추론이 필요하다. 독일어린이 120명의 통계치를 통해 인류의 모수치로 일반화하는 절차다. 즉, 측정자료가 가설을 지지하는지 여부에 대해 판단해야 하는데, 이 판단의 과정에 필요한 정보를 생성하기 위해서는 통계적 가설검정(hypothesis testing)을 이용한다.
추론통계학(Inferential statistics): 인식의 대상(모집단)에 대해 측정하여 얻은 자료(표본)에 대한 기술통계를 바탕으로 모집단의 특성에 대해 추론하는 절차와 기법
기술통계학(Descriptive statistics): 측정하여 얻은 자료를 정리하고 요약함으로써 자료의 특성을 표현하는 절차와 기법
7.2.1 영가설 유의성 검정
영가설 유의성 검정(NHST: Null Hypothesis Significance Testing)은 어떤 현상에 대해 영가설(null hypothesis)을 설정하고, 자료를 관측한 후, ’영가설을 기각’하거나 ’영가설을 기각하지 않음’으로써, 관측자료의 연구가설 지지여부를 판단하는 추론방식이다.
영가설 검정은 인식하고자 하는 현상(혹은 대상)이 ’없다’고 가정한 가설인 영가설을 제시하고 그 영가설에 반하는 근거를 제시함으로써, 연구가설 지지 여부를 판단하는 간접적인 증명방법이다.
모순에 의한 증명(proof by contradiction: 귀류법/배리법/반증법)에 기반한 인식의 방법이다.
- 귀류법(歸謬法): 오류로 귀착됨을 제시
- 배리법(背理法): 이치에 어긋나게(배치) 됨을 제시
- 반증법(反證法): 반대 증거가 나타남을 제시
‘없다’고 가정했기 때문에’영가설’ 또는 ‘귀무(무에 귀인)가설’ 이라고 한다.
- 영가설은 \(H_0\)로 표기한다.
영가설 검정을 이용하는 이유는 어떤 현상에 대해 직접적으로 증명하는 것이 사실상 불가능하기 때문이다.
예를 들어, ’온 세상의 백조는 희다’는 연구가설에 대해 직접적인 근거를 제시하기 해서는 이 세상에 존재하는 모든 백조(모집단)를 찾아 흰색인지 확인해야 하는데, 이는 사실상 실행 불가능하다.
반면, ’온 세상의 흰 백조는 희지 않다’는 영가설(=귀무가설)을 세운 다음, 표본을 통해 반례(예: 검은 백조 등 희지 않은 백조)를 찾아 영가설을 기각하거나, 혹은 반례를 찾지 못해 영가설을 기각하지 않는다면, 이는 실행 가능한 방법이다.
이때 영가설을 기각하고 대안으로서 채택하는 가설을 대안가설 또는 대립가설(alternative hypothesis)라고 한다.
- 대립가설은 \(H_a\) 혹은 \(H_1\)로 표기한다.
단측 vs. 양측 대립가설
- 단측(one-sided) 대립가설: 대안에 방향성을 설정할 수 있는 경우.
- 예: A가 B보다 더 크다(“greater”) 혹은 작다(“less”).
- 양측(two-sided) 대립가설: 대안에 방향성을 설정할 수 없어 관련성 혹은 차이만 고려해야 하는 경우.
- 예: A와 B 사이에 차이가 있다(“two-sided”).
영가설검정은 로날드 피셔(Ronald Fisher)가 소개한 이래 가장 널리 활용되는 방법이다. <계량 사회과학입문(Quantitative Social Science)>에서 이마이 코우스케가 정리한 피셔의 홍차 맛 연구 사례를 통해 영가설 검정의 원리에 대해 살펴보자.
어느날 켐브리지대학의 오후 모임에서 한 여성이 밀크홍차의 우유를 넣는 순서(차 → 우유 vs. 우유 → 차)에 따라 홍차의 맛이 다르다고 했다.
피셔는 이 주장을 검정하기 위한 실험을 했다. 동일한 컵 9개(붓는 컵 포함)를 준비해, 무작위로 4개의 컵에는 홍차에 우유를 부었고, 나머지 4개는 우유에 홍차를 부었다. 그 여성에게 각 컵에 대해 홍차와 우유 중 무엇을 먼저 부었는지 맞추도록 했다. 그 여성은 8개를 모두 정확하게 분류했다.
과연 이 8번을 모두 맞춘 사례를 통해 그 여성이 홍차의 맛을 정확하게 분류하는 능력이 있다고 판단할수 있을까?
여기서 피셔가 알고자 했던 연구가설은 “그 여성이 홍차의 맛을 분류할 수 있다”가 된다.
따라서, 이 연구가설을 검정하기 위해서는 영가설(“그 여성이 홍차의 맛을 분류할 수 없다”)의 기각 여부에 대한 정보가 필요하다.
이에 대한 판단은 확률을 계산해 달성할 수 있다.
8개의 컵에서 4개를 순서에 관계없이 선택하는 것이므로 조합에 해당한다. 8개의 컵에서 4개를 선택하는 경우의 수는 70가지다.
조합(combination): 서로 다른 대상을 뽑아 순서를 고려하지 않고 배열하는 경우의 수.
순열(permutation): 서로 다른 대상을 뽑아 순서를 고려해 배열하는 방법.
choose(8, 4)## [1] 70만일, 그 여성이 홍차-우유의 순서를 알지 못하는데도 8개의 컵에서 4개를 정확하게 선택할 확률을 70번 중 1번은 된다.
round(1/70, 3)## [1] 0.014약 0.014는 발생가능성이 낮은 것인가, 아닌가?
이에 대한 판단기준을 유의수준 \(\alpha\)라고 한다. 만일 유의수준을 0.01로 설정했다면, 0.014는 발생가능성이 낮지 않은 것이 된다. 만일 유의수준을 0.05로 설정했다면, 0.014는 발생가능성이 낮은 것이 된다.
유의수준 0.05에서 0.01은 발생 가능성이 낮으므로, 그 여성이 홍차-우유의 순서를 알지 못했을 가능성은 매우 낮다고 결론을 내릴 수 있다. 즉, 그 여성이 우연하게 8개의 컵의 순서를 우연하게 모두 맞췄을 가능성은 매우 낮다고 할 수 있다.
따라서, 홍차의 순서를 우연하게 분류했을 가능성 0.014는 유의수준 0.05보다 작으므로, 영가설을 기각할 수 있는 근거가 된다. 영가설 하에서 검정한 통계치가 발생할 가능성은 \(p\)값으로 정량화한다.
\(p\)값이 유의수준보다 크면 영가설 유지
\(p\)값이 유의수준보다 같거나 작으면 영가설 기각
\(p\)값(통계적 유의도: 유의확률): 극단적인 검정 통계치를 관측할 확률, 즉, 검정 통계치를 우연하게 관측할 확률. 또는 영가설 하에서 실제로 관찰할 확률.
유의수준 \(\alpha\): 영가설 기각 여부의 판단 기준
7.2.2 옳은 결정
영가설은 ’없음’에 대한 기술이다. 즉, 참인 영가설은 음성, 거짓인 영가설은 양성이라 할 수 있다.
영가설이 거짓인데 영가설을 기각한다는 것은 관측한 양성이 ‘진짜’ 양성이라는 의미다. 따라서, 영가설을 기각했는데, 실제로도 영가설이 거짓이라면, 영가설을 기각한 판단은 진양성(True Positive)이다.
영가설이 참인데 영가설을 유지한다는 것은 관측한 음성이 ‘진짜’ 음성이라는 의미다. 따라서, 영가설을 유지했는데, 실제로 영가설이 참이라면, 영가설을 유지한 판단은 진음성(True Negative)이다.
data.table(
구분 = c("영가설 거짓", "영가설 참"),
`영가설 기각` = c("진양성", "----"),
`영가설 유지` = c("----", "진음성")
) %>% t() %>% as.data.frame() %>%
rownames_to_column() %>% row_to_names(row_number = 1) %>%
gt() %>%
tab_header(title = "가설검정: 옳은 결정") %>%
tab_options(
heading.title.font.size = "middle",
table.width = pct(80),
column_labels.font.weight = "bold",
)| 가설검정: 옳은 결정 | ||
|---|---|---|
| 구분 | 영가설 거짓 | 영가설 참 |
| 영가설 기각 | 진양성 | ---- |
| 영가설 유지 | ---- | 진음성 |
7.2.3 결정오류
영가설은 100% 확실성으로 기각할수 없기에 확률적이다. 피셔의 홍차 맛 실험에서 그 여성이 8개의 순서를 모두 정확하게 맞췄어도 70번 중 1번 꼴로 우연일 가능성이 있다. 따라서 영가설을 기각하거나 혹은 영가설을 유지하지는 경우 모두 오류 가능성이 있다.
7.2.3.1 1종 오류(type 1 error)
1종 오류(type 1 error)는 영가설을 기각했는데, 영가설이 실제로는 참인 경우다. 양성이라고 판단했는데, 진짜가 아닌 가짜 양성이므로 위양성이라고도 한다.
data.table(
구분 = c("영가설 거짓", "영가설 참"),
`영가설 기각` = c("진양성", "1종 오류"),
`영가설 유지` = c("----", "진음성")
) %>% t() %>% as.data.frame() %>%
rownames_to_column() %>% row_to_names(row_number = 1) %>%
gt() %>%
tab_header(title = "가설검정: 결정 오류") %>%
tab_options(
heading.title.font.size = "middle",
table.width = pct(80),
column_labels.font.weight = "bold",
) %>% tab_style(
style = cell_text(weight = "bold", color = "crimson"),
locations = cells_body(
columns = `영가설 참`,
rows = `영가설 참` == "1종 오류")
)| 가설검정: 결정 오류 | ||
|---|---|---|
| 구분 | 영가설 거짓 | 영가설 참 |
| 영가설 기각 | 진양성 | 1종 오류 |
| 영가설 유지 | ---- | 진음성 |
유의수준 \(\alpha\)가 0.05라면 1종오류 가능성은?
유의수준은 영가설을 기각하는 기준이다. 유의수준이 0.05라는 것은 영가설을 기각했는데, 100번 중 5번은 실제로 영가설이 참일수 있다는 의미다. 즉, 5% 꼴로 위양성 혹은 1종 오류가 발생할 수 있다.
이런 이유로 1종 오류를 \(\alpha\)라고도 한다.
위양성을 통계치의 분포도로 표시하면 다음과 같다 (Figure 7.1).
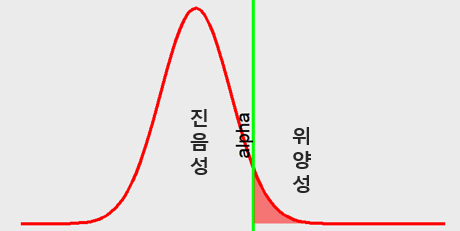
Figure 7.1: 위양성
유의수준 \(\alpha\)을 조절해 진음성과 위양성의 판단영역을 조절한다.
- 유의수준 \(\alpha\)가 0.05 (Figure 7.2)
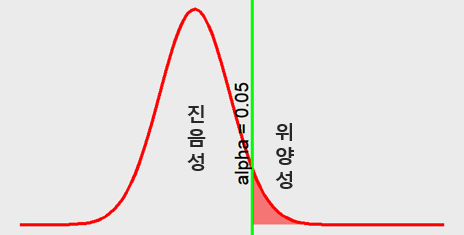
Figure 7.2: alpha = 0.05
- 유의수준 \(\alpha\)가 0.1 (Figure 7.3)
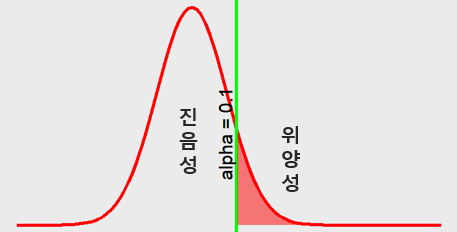
Figure 7.3: alpha = 0.1
- 유의수준 \(\alpha\)가 0.01 (Figure 7.4)
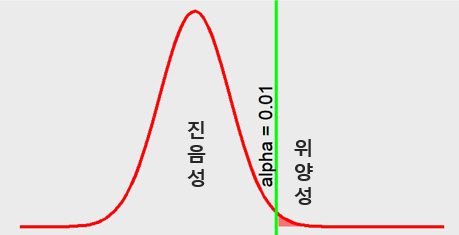
Figure 7.4: alpha = 0.01
7.2.3.2 2종 오류(type 2 error)
2종 오류(type 2 error)는 영가설을 유지했는데, 영가설이 실제로는 거짓인 경우다. 음성이라고 판단했는데, 진짜가 아닌 가짜 음성이므로 위음성이라고도 한다. 1종 오류 \(\alpha\)에 대비해 2종 오류는 \(\beta\)라고 한다.
data.table(
구분 = c("영가설 거짓", "영가설 참"),
`영가설 기각` = c("진양성", "1종 오류"),
`영가설 유지` = c("2종 오류", "진음성")
) %>% t() %>% as.data.frame() %>%
rownames_to_column() %>% row_to_names(row_number = 1) %>%
gt() %>%
tab_header(title = "가설검정: 결정 오류") %>%
tab_options(
heading.title.font.size = "middle",
table.width = pct(80),
column_labels.font.weight = "bold",
) %>% tab_style(
style = cell_text(weight = "bold", color = "darkmagenta"),
locations = cells_body(
columns = `영가설 거짓`,
rows = `영가설 거짓` == "2종 오류")
)| 가설검정: 결정 오류 | ||
|---|---|---|
| 구분 | 영가설 거짓 | 영가설 참 |
| 영가설 기각 | 진양성 | 1종 오류 |
| 영가설 유지 | 2종 오류 | 진음성 |
2종오류(위음성)를 분포도로 표시하면 다음과 같다 (Figure 7.5).
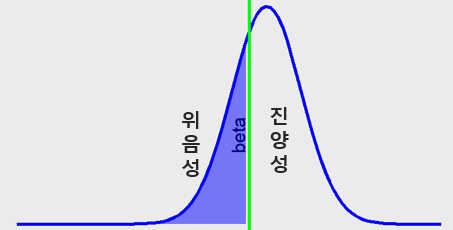
Figure 7.5: 위음성
1종 오류와 2종 오류는 동시에 줄일 수 없다. 1종 오류 가능성을 낮추면 2종 오류 가능성이 증가한다 (Figure 7.6).
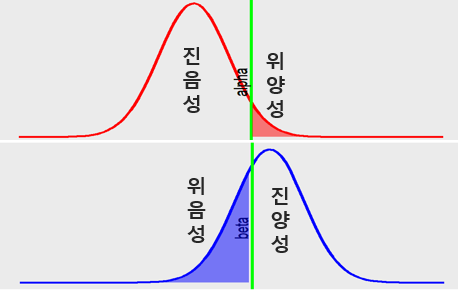
Figure 7.6: 검정력
- 유의수준 \(\alpha\)가 0.05일 때 위음성과 위양성의 분포 (Figure 7.7).
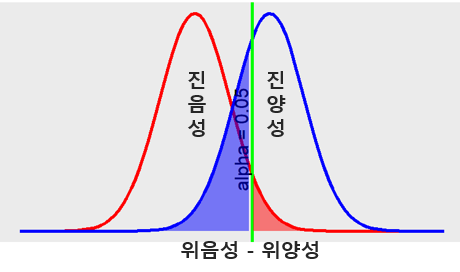
Figure 7.7: 위음성과 위양성 확률
- 유의수준 \(\alpha\)가 0.01일 때 위음성과 위양성의 분포 (Figure 7.8).
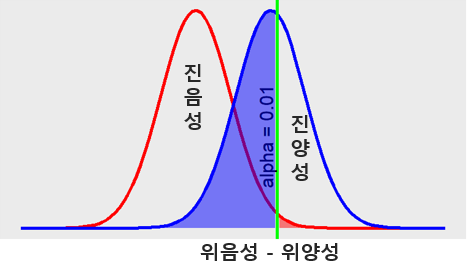
Figure 7.8: 위음성과 위양성의 분포
- 유의수준 \(\alpha\)가 0.1일 때 위음성과 위양성의 분포 (Figure 7.9).
Figure 7.9: 위음성과 위양성의 분포
7.3 집단간 비교: t검정
집단평판에 대한 관심과 친사회적 행동의 관계에 대한 가설을 검정해 보자.
“집단평판에 대한 관심이 있으면, 평판에 대한 관심이 없을 때보다 친사회적 행동을 촉진한다”는 연구가설을 통해 종속변수(결과)인 친사회성은 “자신의 물건(장난감)을 모르는 사람에게 기부하는 횟수”로 조작했고, 독립변수(원인)인 집단평판에 대한 관심은 집단구성에 의한 소속감 부여로 집단을 조작했고, 기부행위의 가시성 여부로 평판에 대한 관심을 조작했다.
이를 통해 연구 집단은 기본적으로 집단평판에 대한 관심을 부여한 처치집단과 그렇지 않은 대조집단 등 2개 집단으로 구분된다.
이 연구에서 제시한 연구가설을 검정하기 위해서는 “처치집단과 대조집단의 평균사이에 차이가 없다”는 영가설에 대한 기각 여부를 판단해야 한다.
집단 간 차이를 비교할수 있는 분석방법은 종속변수가 연속형일 때 주로 다음 3가지가 쓰인다.
- t검정(t-test)
- 변량분석(분산분석: ANOVA)
- 회귀분석(더미변수 이용)
7.3.1 t검정
t검정에는 일표본t검정(one-sample t-test), 짝진t검정(paired t-test), 그리고, 이표본t검정(two-sample t-test)이 있다.
7.3.1.1 이표본t검정(Independent two-sample t-test)
이표본t검정(t-test)은 독립변수가 범주형이고 종속변수가 연속형일때 사용하는 분석방법이다. 독립변수를 처치집단과 대조집단으로 측정하고, 종속변수를 연속형 변수로 측정할 때 사용한다.
집단평판관심과 친사회성에 대한 연구에서 독립변수는 집단평판관심이고 종속변수는 친사회성이므로, t검정을 통해 처치집단과 대조집단 사이의 친사회성에 통계적으로 유의한 차이가 있는지 검정해보자.
url <- "https://raw.githubusercontent.com/dataminds/art/main/files/group_reputation.xlsx"
rio::import(url) %>%
transmute.(
pro = number.stickers.shared,
repu_grp = group_public %>% as.factor()
) -> df
summary(df)## pro repu_grp
## Min. : 0.000 no :48
## 1st Qu.: 4.000 yes:72
## Median : 5.000
## Mean : 4.858
## 3rd Qu.: 6.000
## Max. :10.000df %>%
ggplot(aes(x = repu_grp, y = pro, color = repu_grp)) +
geom_boxplot() +
geom_sina(alpha = .4) +
labs(title = "집단평판 관심과 친사회성의 관계",
x = "집단평판 관심",
y = "친사회성") +
theme(legend.position = "none")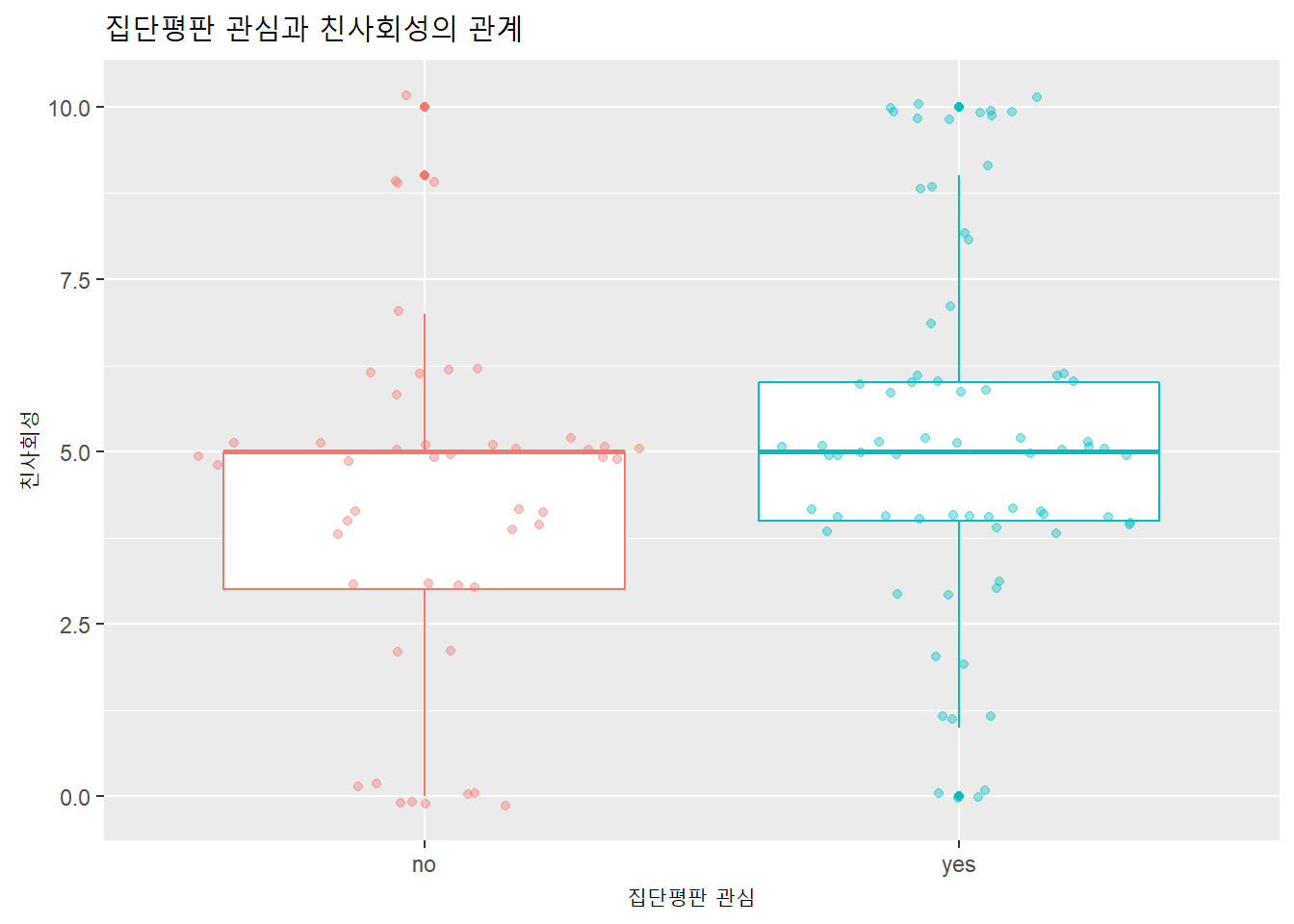
t검정에는 영가설에 대한 대립가설(alternative hypothesis)이 단측(“greater” or “less”)인지 혹은 양측(“two-sided”) 여부를 정해야 한다. 연구가설이 “집단평판에 대한 관심이 있으면, 평판에 대한 관심이 없을 때보다 친사회적 행동을 촉진한다”로서 방향성을 설정할 수 있으므로, 단측 대립가설(“greater”)로 t검정을 수행한다.
R 기본함수인 t.test()와 infer패키지가 제공하는 t_test()함수가 있다. infer패키지는 tidymodles 패키지에 포함돼 있다.
먼저 처치집단(집단평판 관심)과 대조집단의 평균과 그 차이를 구해보자.
df %>%
summarise.(m = mean(pro), .by = repu_grp) %>%
pivot_wider.(names_from = repu_grp, values_from = m) %>%
mutate.(diff = yes - no) %>%
gt() %>%
tab_header("집단평판관심 여부에 따른 기부횟수 차이") %>%
fmt_number(1:3, decimals = 2)| 집단평판관심 여부에 따른 기부횟수 차이 | ||
|---|---|---|
| no | yes | diff |
| 4.23 | 5.28 | 1.05 |
영가설 “처치집단과 대조집단의 차이가 없다”의 기각 여부는 집단간 평균의 차이 1.05가 0과 통계적으로 유의하게 다른지 여부로 판단할수 있다.
만일, 집단간 평균 차이 1.05가 0보다 통계적으로 유의하게 다르다면, 영가설은 기각된다. 영가설이 기각되면, 단측 대립가설(“greater”)인 “처치집단이 대조집단보다 크다”를 채택할수 있게 된다.
t_test()함수의alternative =기본값은"two-sided"이고,conf_level =기본값은0.95다.
df %>% t_test(formula = pro ~ repu_grp,
order = c("yes", "no"),
alternative = "greater") %>%
gt() %>%
tab_header("집단평판관심과 친사회성 관계에 대한 t검정 결과") %>%
fmt_number(c(1,2,5,6), decimals = 2) %>%
fmt_number(3, decimals = 3)| 집단평판관심과 친사회성 관계에 대한 t검정 결과 | ||||||
|---|---|---|---|---|---|---|
| statistic | t_df | p_value | alternative | estimate | lower_ci | upper_ci |
| 2.17 | 106.52 | 0.016 | greater | 1.05 | 0.25 | Inf |
\(p\)값이 0.016으로서 유의수준 0.05보다 작으므로, 집단간 평균 차이(1.05)는 통계적으로 유의하게 0과 다르다. 이는 신뢰구간을 통해서도 확인할 수 있다 (95% 신뢰수준[0.25, Inf]).
- “greater” 단측검정이기 때문에 upper_ci가 무한(Inf)이다.
- “less” 단측검정이라면 lower_ci가 무한(Inf).
즉, 유의수준 0.05에서 집단평판 관심집단의 기부횟수가 대조집단에 비해 통계적으로 유의하게 크다는 판단을 내릴 수 있다.
만일, 양측검정을 한다면 다음과 같은 결과를 얻을 수 있다.
df %>% t_test(formula = pro ~ repu_grp,
order = c("yes", "no"),
alternative = "two-sided") %>%
gt() %>%
tab_header("집단평판관심과 친사회성 관계에 대한 t검정 결과: 양측검정") %>%
fmt_number(c(1,2,5:7), decimals = 2) %>%
fmt_number(3, decimals = 3)| 집단평판관심과 친사회성 관계에 대한 t검정 결과: 양측검정 | ||||||
|---|---|---|---|---|---|---|
| statistic | t_df | p_value | alternative | estimate | lower_ci | upper_ci |
| 2.17 | 106.52 | 0.032 | two.sided | 1.05 | 0.09 | 2.01 |
\(p\)값이 0.032로서 유의수준 0.05보다 작으므로, 집단간 평균 차이(1.05)는 통계적으로 유의하게 0과 다르다. 이는 신뢰구간을 통해서도 확인할 수 있다 (95% 신뢰수준[0.09, 2.01]).
- 양측검정(“two-sided”)이기 때문에 lower_ci와 upper_ci 값이 특정돼 있다.
이처럼 두개의 독립적인 집단을 비교하기 때문에 이표본t검정을 독립이표본t검정(Independent two-sample t-test)라고도 한다.
7.3.1.2 일표본t검정(One-sample t-test)
일표본t검정(One-sample t-test)은 단일표본의 평균을 모집단의 모평균으로 추론하는 t검정이다.
예를 들어, 집단평판관심-친사회성 연구에서 친사회성의 모평균을 알고 있는 상황(예: 5)이라고 할때, 단일집단의 친사회성 평균과 모평균과의 일치 여부를 검정하는 경우에 사용한다.
이 경우, 영가설은 “표본평균과 모평균이 같다”가 되고, 대안가설은 “표본평균과 모평균은 다르다”가 된다.
df %>% t_test(response = pro, mu = 5) %>%
gt() %>%
tab_header("일표본 t검정 결과") %>%
fmt_number(c(1,2,5:7), decimals = 2) %>%
fmt_number(3, decimals = 3)| 일표본 t검정 결과 | ||||||
|---|---|---|---|---|---|---|
| statistic | t_df | p_value | alternative | estimate | lower_ci | upper_ci |
| −0.58 | 119.00 | 0.563 | two.sided | 4.86 | 4.37 | 5.34 |
\(p\)값이 0.563으로 유의수준 0.05보다 크므로, 이 표본의 평균은 모집단의 평균과 통계적으로 유의하게 0과 다르지 않다. 이는 평균 4.86이 신뢰구간 사이에 있음을 통해서도 확인할 수 있다 (95% 신뢰수준[4.37, 5.34]).
7.3.1.3 짝진 t-검정(Paired t-test)
짝진 t-검정(Paired t-test)은 단일 집단의 특정 시점 사전(before)과 사후(after)의 평균 차이를 검정하는경우에 사용한다.
예를 들어, 집단평판관심-친사회성 연구에서 특정 사건의 사전 친사회성 수준과 사후 친사회성 수준으로 구분해 측정한 다음, 사전평균과 사후평균을 비교하는 경우에 사용한다.
단일 표본에서 사전 사후 평균비교이므로, 영가설은 “사전평균과 사후 평균을 같다”가 된다 즉, “평균의 차이는 0과 같다”가 된다. 대안가설은 “사전평균과 사후평균이 다르다”가 된다. 즉, “평균의 차이는 0과 다르다”가 된다.
- 짝진t검정은 일표본t검정과 같은 방식으로 계산하는데, 다만 평균(
mu =)을 0으로 설정한다.
# 사전 사후 집단 분리
df %>% filter.(repu_grp == "no") -> df1
df %>% filter.(repu_grp == "yes") -> df2
# 데이터프레임의 열수를 맞추기 위해 각 48열 선택해 열결합
df1[1:48] %>% bind_cols.(df2[1:48]) %>%
# 평균 차이 계산
mutate.(diff = pro...3 - pro...1) %>%
# 일표본t검정 수행
t_test(response = diff, mu = 0) %>%
gt() %>%
tab_header("짝진t검정 결과") %>%
fmt_number(c(1,2,5:7), decimals = 2) %>%
fmt_number(3, decimals = 3)## New names:
## * pro -> pro...1
## * repu_grp -> repu_grp...2
## * pro -> pro...3
## * repu_grp -> repu_grp...4| 짝진t검정 결과 | ||||||
|---|---|---|---|---|---|---|
| statistic | t_df | p_value | alternative | estimate | lower_ci | upper_ci |
| 2.86 | 47.00 | 0.006 | two.sided | 1.52 | 0.45 | 2.59 |
\(p\)값이 0.006으로 유의수준 0.05보다 작으므로, 사전-사후 평균 차이(1.52)는 통계적으로 유의하게 0과 다르다. 이는 신뢰구간을 통해서도 확인할 수 있다 (95% 신뢰수준[0.45, 2.59]).
7.4 종합
7.4.2 통계
- 통계적 가설검정(hypothesis testing)
- 영가설 유의성 검정(NHST: Null Hypothesis Significance Testing)
- 모순에 의한 증명(proof by contradiction)
- 귀류법
- 배리법
- 반증법
- 영가설(Null Hypothesis)
- 대립가설(Alternative Hypothesis)
- 단측대립가설(One-sided Alternative Hypothesis)
- 양측대립가설(Two-sided Alternative Hypothesis)
- 조합(combination)
- 순열(permutation)
- p값
- 통계적 유의도
- 유의확률
- 진양성(True Positive)
- 진음성(True Negative)
- 결정오류
- 1종오류(type 1 error)
- 위양성
- 2종오류(type 2 error)
- 위음성
- 검정력(power)
- t검정
- 이표본t검정(two-sample t-test)
- 일표본t검정(one-sample t-test)
- 짝진t검정(paired t-test)